注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
ゲインとリフトチャートを使用して、分類モデルのパフォーマンスを評価します。ゲインチャートは、合計カウント数のパーセントに対するパーセントで合計陽性率をプロットします。リフトチャートでは、累積リフト(または非累積リフト)と合計カウント数の割合をプロットします。
ゲインチャートの解釈
トレーニング行とテスト行は、予測モデルを使用して予想される応答を表します。トレーニング データセットはモデルに適合し、テストデータセットはモデルを評価します。点線の参照線は、傾斜角が1の線を表し、モデルを使用しないランダム応答が予想されます。
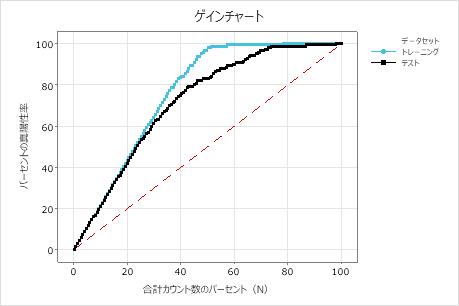
この例では、ゲインチャートは参照線の上に急激に増加し、次に平坦化を示しています。この場合、データの約40%が真陽性の約80%を占めています。したがって、ビジネスがモデルによって導かれた人口の20%をターゲットにしている場合、真陽性の割合のパーセントは約40%です。モデルがない場合、対応するパーセントは20%です。この違いは、モデルを使用した場合の追加の利益です。
リフトチャートの解釈
トレーニング行とテスト行は、予測モデルを使用して予想される応答を表します。トレーニング データセットはモデルに適合し、テストデータセットはモデルを評価します。リフトは、予想されるランダムな結果に対するゲイン率のパーセントです。点線の参照線は累積リフト1を表し、ランダムと比較してゲインがないことを意味します。
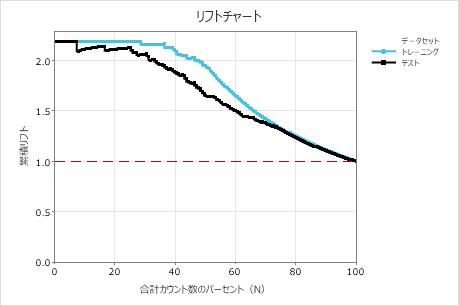
この例では、リフトチャートは、徐々に落ちる基準線の上に大きな増加を示しています。したがって、このモデルを使用すると、顧客の10%のみと連絡を取るだけで、モデルを使用しない場合と比べて2倍以上の回答者にリーチします。