注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
ある研究チームが、心臓病に影響を与える要因に関する詳細な情報を収集し、公開しています。変数には、年齢、性別、コレステロール値、最大心拍数などがあります。この例は、心臓病に関する詳細情報を提供する公開データセットに基づいています。元のデータは4 archive.ics.uci.edu 年のものです。
重要な予測因子を特定するために CART® 分類 で初期の探索を行った後、研究者たちは TreeNet® 分類 と Random Forests® 分類 の両方を用いて同じデータセットからより集中的なモデルを作成しました。研究者たちは、結果のモデル要約表とROCプロットを比較して、予測精度の高いモデルを評価します。他の分析の結果については、CART® 分類の例およびRandom Forests® 分類の例を参照してください。
- サンプルデータ、心臓病バイナリ.MWXを開きます。
- を選択します。
- ドロップダウンリストから2値応答を選択します。
- 応答に ‘心臓病’を入力してください。
- 応答事象では、患者に心臓病が確認されたことを示す はい を選択します。
- 連続予測変数では、 '年齢'、’レスト血圧’、 ‘コレステロール’、’最大心拍数’’、’オールドピーク’と入力します。
- カテゴリ予測変数では、 ‘セックス‘、 ‘胸痛タイプ’、 ‘断食血糖’、 ‘レスト心電図’、 ‘運動狭心症’、 ‘斜面‘、 ‘主要な船舶’、 ‘タール‘を入力します。
- OKをクリックします。
結果を解釈する
この分析では、Minitabは300本の木を増加させ、最適な木の数は298本です。最適な木の数が、モデルが成長する木の最大数に近いため、木の数を増やして再実行します。
モデル要約
| 合計予測変数 | 13 |
|---|---|
| 重要な予測変数 | 13 |
| 増加した木の数 | 300 |
| 最適な木の数 | 298 |
| 統計量 | トレーニング | 交差検証 |
|---|---|---|
| 負の対数尤度の平均 | 0.2556 | 0.3881 |
| ROC曲線下面積 | 0.9796 | 0.9089 |
| 95%信頼区間 | (0.9664, 0.9929) | (0.8759, 0.9419) |
| リフト | 2.1799 | 2.1087 |
| 誤分類率 | 0.0891 | 0.1617 |
500本の木を含む例
- 結果で [ ハイパーパラメータの調整 ] を選択します。
- 木の数に、500と入力します。
- 結果を表示をクリックします。
結果を解釈する
この分析では、500本の木が成長し、最適な木の数は351です。最良のモデルは学習率0.01を使用し、サブサンプル分数は0.5、ターミナルノードの最大数は6を使用します。
方法
| 木の最適な数の選択基準 | 最大対数尤度 |
|---|---|
| モデル検証 | 5分割交差検証 |
| 学習率 | 0.01 |
| サブサンプルの選択方法 | 完全にランダム |
| サブサンプルの割合 | 0.5 |
| 木あたりの最大終端ノード | 6 |
| 最小終端節サイズ | 3 |
| ノード分岐に対して選択された予測変数の数 | 予測変数の合計数 = 13 |
| 使用中の行 | 303 |
二項応答情報
| 変数 | クラス | 計数 | % |
|---|---|---|---|
| 心臓病 | はい (事象) | 139 | 45.87 |
| いいえ | 164 | 54.13 | |
| すべて | 303 | 100.00 |
方法
| 木の最適な数の選択基準 | 最大対数尤度 |
|---|---|
| モデル検証 | 5分割交差検証 |
| 学習率 | 0.001, 0.01, 0.1 |
| サブサンプルの割合 | 0.5, 0.7 |
| 木あたりの最大終端ノード | 6 |
| 最小終端節サイズ | 3 |
| ノード分岐に対して選択された予測変数の数 | 予測変数の合計数 = 13 |
| 使用中の行 | 303 |
二項応答情報
| 変数 | クラス | 計数 | % |
|---|---|---|---|
| 心臓病 | はい (事象) | 139 | 45.87 |
| いいえ | 164 | 54.13 | |
| すべて | 303 | 100.00 |
ハイパーパラメータの最適化
| モデル | 最適な木の数 | 負の対数尤度の平均 | ROC曲線下面積 | 誤分類率 | 学習率 | サブサンプルの割合 | 最大終端ノード |
|---|---|---|---|---|---|---|---|
| 1 | 500 | 0.542902 | 0.902956 | 0.171749 | 0.001 | 0.5 | 6 |
| 2* | 351 | 0.386536 | 0.908920 | 0.175027 | 0.010 | 0.5 | 6 |
| 3 | 33 | 0.396555 | 0.900782 | 0.161694 | 0.100 | 0.5 | 6 |
| 4 | 500 | 0.543292 | 0.894178 | 0.178142 | 0.001 | 0.7 | 6 |
| 5 | 374 | 0.389607 | 0.906620 | 0.165082 | 0.010 | 0.7 | 6 |
| 6 | 39 | 0.393382 | 0.901399 | 0.174973 | 0.100 | 0.7 | 6 |
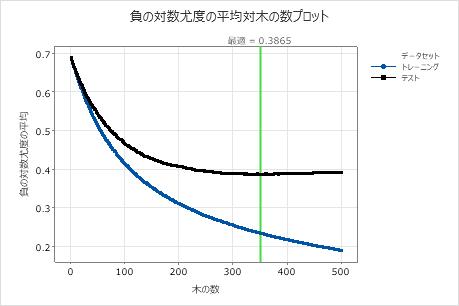
平均-対数有利度対数プロットは、成長した樹木数全体の曲線を示します。クロスバリデーションによる最適値は、ツリー数が351の場合0.3865です。
モデル要約
| 合計予測変数 | 13 |
|---|---|
| 重要な予測変数 | 13 |
| 増加した木の数 | 500 |
| 最適な木の数 | 351 |
| 統計量 | トレーニング | 交差検証 |
|---|---|---|
| 負の対数尤度の平均 | 0.2341 | 0.3865 |
| ROC曲線下面積 | 0.9825 | 0.9089 |
| 95%信頼区間 | (0.9706, 0.9945) | (0.8757, 0.9421) |
| リフト | 2.1799 | 2.1087 |
| 誤分類率 | 0.0759 | 0.1750 |
モデル要約
| 合計予測変数 | 13 |
|---|---|
| 重要な予測変数 | 13 |
| 統計量 | アウトオブバッグ |
|---|---|
| 負の対数尤度の平均 | 0.4004 |
| ROC曲線下面積 | 0.9028 |
| 95%信頼区間 | (0.8693, 0.9363) |
| リフト | 2.1079 |
| 誤分類率 | 0.1848 |
モデルの要約表は、木の数が351時の平均負の対数尤度は訓練データで約0.23、クロスバリデーション結果で約0.39であることを示しています。これらの統計値は、Minitab Random Forests®が作成するものと同様のモデルを示しています。また、誤判別率も同様です。
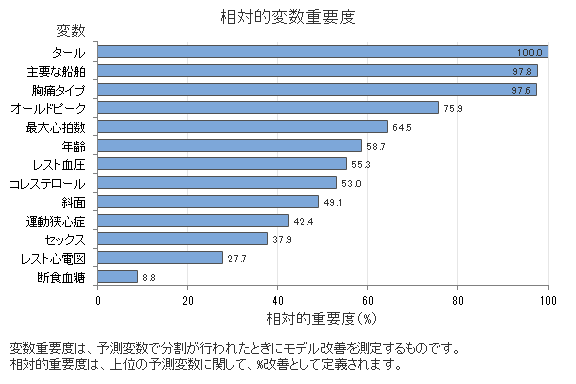
相対変数重要度グラフは、予測変数が木の列に分割された際のモデル改善への影響順に予測変数をプロットします。最も重要な予測変数はThalです。最上の予測変数であるThalの寄与度が100%の場合、次に重要な変数である主要な血管は97.8%の寄与度を有します。これは、この分類モデルで、主要な血管がThalの97.8%重要であることを意味します。
混同行列
| 予測クラス(トレーニング) | 予測クラス (交差検証) | ||||||
|---|---|---|---|---|---|---|---|
| 実クラス | 計数 | はい | いいえ | %正 | はい | いいえ | %正 |
| はい (事象) | 139 | 124 | 15 | 89.21 | 110 | 29 | 79.14 |
| いいえ | 164 | 8 | 156 | 95.12 | 24 | 140 | 85.37 |
| すべて | 303 | 132 | 171 | 92.41 | 134 | 169 | 82.51 |
| 統計量 | トレーニング(%) | 交差検証 (%) |
|---|---|---|
| 真陽性率(感度または検出力) | 89.21 | 79.14 |
| 偽陽性率(第一種過誤) | 4.88 | 14.63 |
| 偽陰性率(第二種過誤) | 10.79 | 20.86 |
| 真陰性率(特異度) | 95.12 | 85.37 |
混同行列は、モデルがクラスをどの程度正しく分類しているかを示します。この例では、事象が正しく予測される確率は79.14%です。非事象が正しく予測される確率は85.37%です。
誤分類
| トレーニング | 交差検証 | ||||
|---|---|---|---|---|---|
| 実クラス | 計数 | 誤分類されました | %誤差 | 誤分類されました | %誤差 |
| はい (事象) | 139 | 15 | 10.79 | 29 | 20.86 |
| いいえ | 164 | 8 | 4.88 | 24 | 14.63 |
| すべて | 303 | 23 | 7.59 | 53 | 17.49 |
誤分類率は、モデルが新しい観測値を正確に予測するかどうかを示すのに役立ちます。事象の予測において、クロス検証結果の誤分類誤差は20.86%です。非事象の予測では、誤分類誤差は14.63%であり、全体では誤分類誤差は17.49%です。
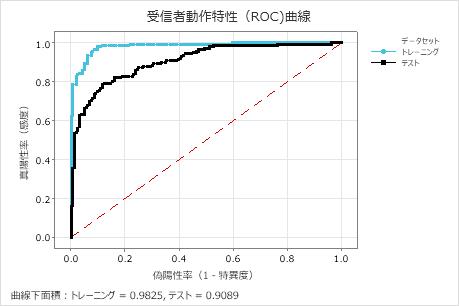
351本の木の木数がある場合、ROC曲線下の面積は訓練データで約0.98、クロスバリデーション結果では約0.91です。これは、CART® 分類モデルよりも優れた改善を示しています。Random Forests® 分類 モデルの交差検証AUROCは0.9028であるため、これら2つの方法は同様の結果をもたらします。
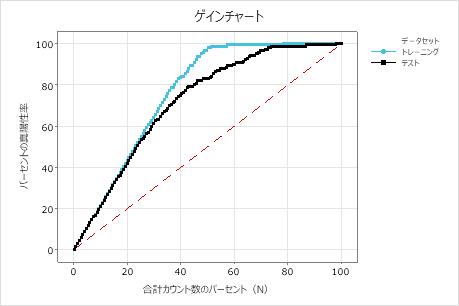
この例では、ゲインチャートは参照線の上に急激に増加し、次に平坦化を示しています。この場合、データの約 40% が真陽性の約 80% を占めます。この違いは、モデルを使用した場合の追加の利益です。
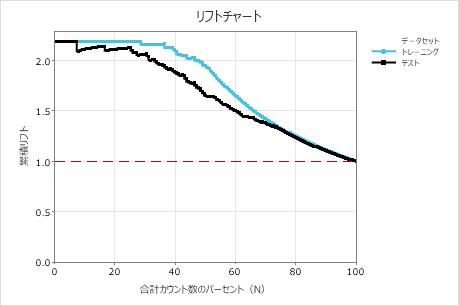
この例では、リフトチャートは、徐々に落ちる基準線の上に大きな増加を示しています。
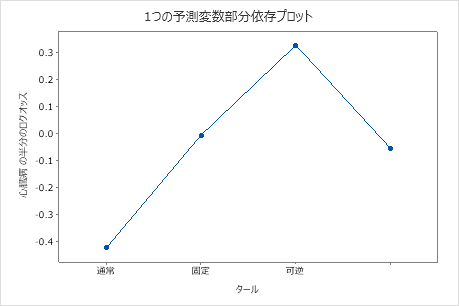
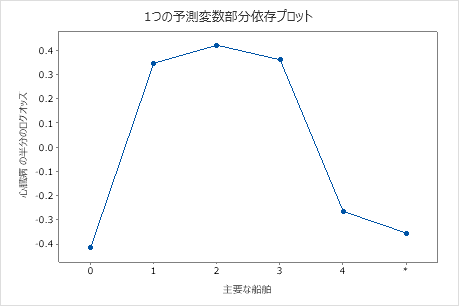
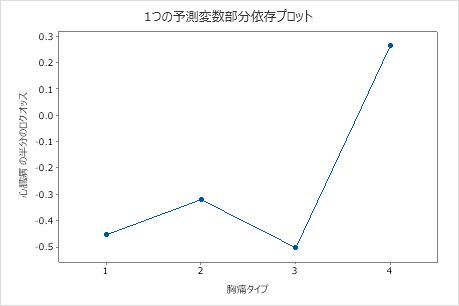
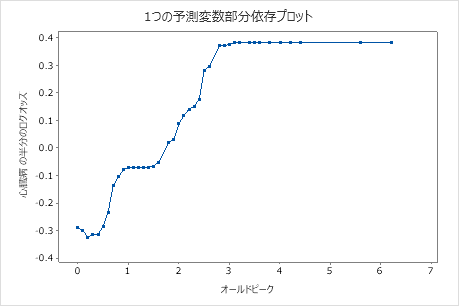
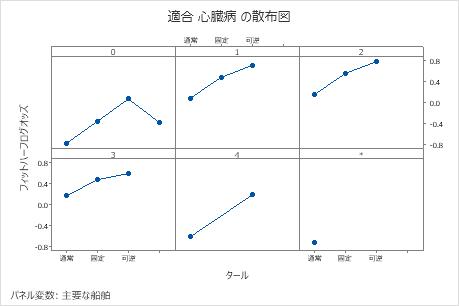
偏依存プロットを使用して、重要な変数または変数のペアが適合応答値にどのように影響するかについての洞察を得ます。フィットした応答値は1/2対数スケールで示されます。部分依存プロットは、応答と変数の関係が線形、単調、またはより複雑であるかどうかを示します。
たとえば、胸痛タイプの部分的依存性プロットでは、1/2対数のオッズが変化し、その後急激に増加します。胸痛のタイプが4の場合、心臓病発生率の1/2ログオッズは約−0.04から0.03に増加する。他の変数のプロットを作成するには または を選択します