注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
研究チームは、焼きプレッツェルの品質特性に影響を与える因子に関するデータを収集します。変数には、 などの ミックスツールプロセス設定と 小麦粉タンパク質、.
データの最初の調査の一環として、研究者は重要でない予測変数を順に除去して主要な予測変数を特定することで、モデルの比較に使用する主要な予測変数を検出ことを決定します。研究者は、品質特性に大きな影響を与える主要な予測変数を特定し、品質特性と主要な予測変数の関係に関するより多くの洞察を得たいと考えています。
- サンプルデータ、プレッツェルの受容性.MWXを開きます。
- を選択します。
- ドロップダウンリストから2値応答を選択します。
- 応答にを入力します受け入れ可能なプレッツェル。
- 応答事象で、プレッツェルが許容可能であることを示す場合は 1 を選択します。
- に 連続予測変数「-かさ密度」と入力します 小麦粉タンパク質。
- に カテゴリ予測変数「-窯法」と入力します ミックスツール。
- 予測変数の消去をクリックします。
- 消去ステップの最大数に、29と入力します。
- 各ダイアログボックスのOKをクリックします。
結果を解釈する
この分析では、28のモデルを比較します。最初のモデルでは泡の安定性予測変数の重要度スコアが0であるために、ステップ数が最大ステップ数よりも小さくなります。つまりアルゴリズムは最初のステップで2つの変数を削除します。モデル評価表のモデル列のアスタリスクは、平均対数尤度統計量の最小値を持つモデルがモデル23であることを示しています。モデル評価表に続く結果は、モデル23に対するものです。
モデル23は平均対数尤度統計量の最小値を持ちますが、他のモデルも同様の値を持ちます。チームは、代替モデルの選択をクリックして、モデル評価表から他のモデルの結果を生成できます。
モデル23の結果で、平均対数尤度対木の数プロットは、最適な木の数が分析の木の数に近いことを示しています。ハイパーパラメータの調整をクリックすると、木の数を増やしたり、他のハイパーパラメーターに加えた変更によってモデルのパフォーマンスが向上するかどうかを確認できます。
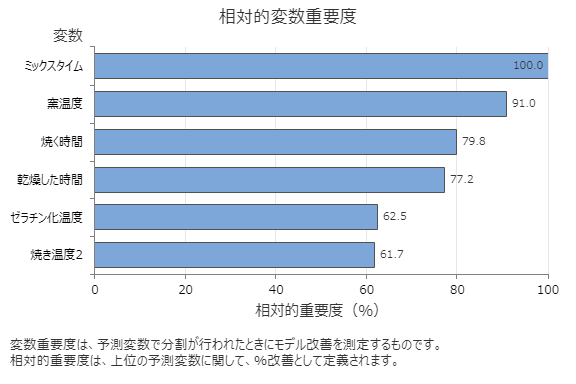
相対変数重要度グラフは、木のシーケンスに対して予測変数で分岐が行われたときに、モデルの改善に対する予測変数の効果の順に予測変数をプロットします。最も重要な予測変数はミックスタイムです。最上の予測変数であるミックスタイムの寄与度が100%の場合、次に重要な変数である窯温度は91.0%の寄与度を有します。これは、窯温度が、Bのミックスタイム91.0%重要であることを意味します。
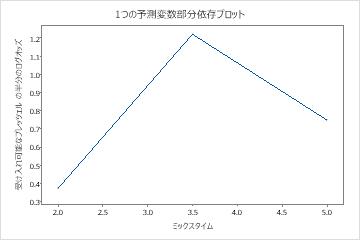
偏依存プロットを使用して、重要な変数または変数のペアが適合応答値にどのように影響するかについての洞察を得ます。適合した応答値は、1/2 対数スケールです。部分依存プロットは、応答と変数の関係が線形、単調、またはより複雑であるかどうかを示します。
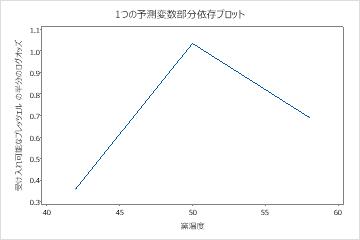
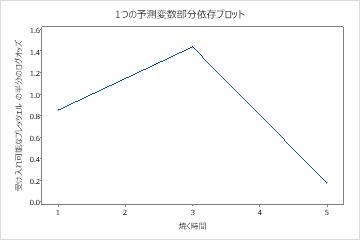
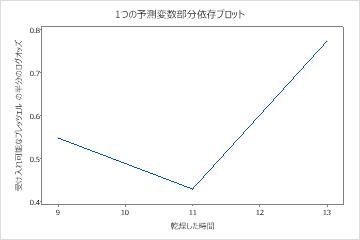
1つの予測変数の部分依存プロットは、ミックスタイム、窯温度および 焼く時間に対する中央値が、許容可能なプレッツェルのオッズを増やすことを示しています。乾燥した時間の中央値は許容可能なプレッツェルのオッズを減少させます。研究者は、他の変数のプロットを生成するように選択 できます。
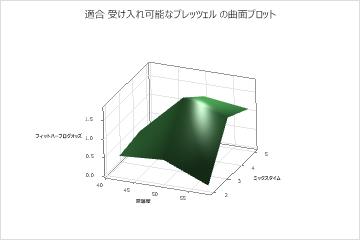
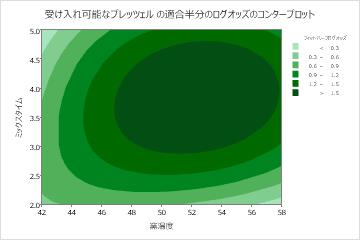
ミックスタイムおよび窯温度の2つの予測変数の部分依存プロットは、2つの変数と応答との間のより複雑な関係を示しています。と 窯温度 の値が中 ミックスタイム 程度の場合、許容可能なプレッツェルのオッズが増加しますが、プロットは、両方の変数が中程度の値にあるときに最高のオッズが発生することを示しています。研究者は、他の変数ペアのプロットを作成するように選択 できます。
方法
| 木の最適な数の選択基準 | 最大対数尤度 |
|---|---|
| モデル検証 | 70/30%トレーニング/テストセット |
| 学習率 | 0.05 |
| サブサンプルの選択方法 | 完全にランダム |
| サブサンプルの割合 | 0.5 |
| 木あたりの最大終端ノード | 6 |
| 最小終端節サイズ | 3 |
| ノード分岐に対して選択された予測変数の数 | 予測変数の合計数 = 29 |
| 使用中の行 | 5000 |
二項応答情報
| トレーニング | テスト | ||||
|---|---|---|---|---|---|
| 変数 | クラス | 計数 | % | 計数 | % |
| 受け入れ可能なプレッツェル | 1 (事象) | 2160 | 61.82 | 943 | 62.62 |
| 0 | 1334 | 38.18 | 563 | 37.38 | |
| すべて | 3494 | 100.00 | 1506 | 100.00 | |
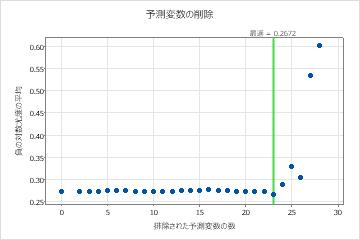
重要でない予測変数を削除するモデル選択
| モデル | 最適な木の数 | 負の対数尤度の平均 | 予測変数の数 | 削除された予測変数 |
|---|---|---|---|---|
| 1 | 268 | 0.273936 | 29 | なし |
| 2 | 268 | 0.274186 | 27 | 泡の安定性, かさ密度 |
| 3 | 234 | 0.273843 | 26 | 最も少ないゲル化濃度 |
| 4 | 233 | 0.274350 | 25 | オーブンモード2 |
| 5 | 232 | 0.274943 | 24 | 窯法 |
| 6 | 273 | 0.275553 | 23 | オーブンモード1 |
| 7 | 244 | 0.274811 | 22 | ミックススピード |
| 8 | 268 | 0.274258 | 21 | オーブンモード3 |
| 9 | 272 | 0.274185 | 20 | 安静表面 |
| 10 | 232 | 0.274077 | 19 | 焼き温度3 |
| 11 | 287 | 0.273598 | 18 | ミックスツール |
| 12 | 227 | 0.274358 | 17 | 焼き温度1 |
| 13 | 276 | 0.275374 | 16 | 休憩時間 |
| 14 | 272 | 0.276082 | 15 | 水 |
| 15 | 268 | 0.275595 | 14 | 苛性濃度 |
| 16 | 268 | 0.277810 | 13 | 膨潤能力 |
| 17 | 253 | 0.276436 | 12 | 乳化安定性 |
| 18 | 231 | 0.276159 | 11 | エマルジョン活性 |
| 19 | 268 | 0.273537 | 10 | 吸水能力 |
| 20 | 260 | 0.273455 | 9 | 吸油能力 |
| 21 | 299 | 0.272848 | 8 | 小麦粉タンパク質 |
| 22 | 278 | 0.272629 | 7 | 泡容量 |
| 23* | 299 | 0.267184 | 6 | 小麦粉の大きさ |
| 24 | 297 | 0.288621 | 5 | 焼き温度2 |
| 25 | 234 | 0.330342 | 4 | 乾燥した時間 |
| 26 | 290 | 0.305993 | 3 | ゼラチン化温度 |
| 27 | 245 | 0.534345 | 2 | 焼く時間 |
| 28 | 146 | 0.599837 | 1 | 窯温度 |
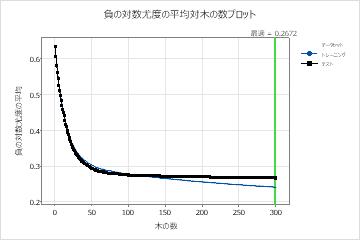
モデル要約
| 合計予測変数 | 6 |
|---|---|
| 重要な予測変数 | 6 |
| 増加した木の数 | 300 |
| 最適な木の数 | 299 |
| 統計量 | トレーニング | テスト |
|---|---|---|
| 負の対数尤度の平均 | 0.2418 | 0.2672 |
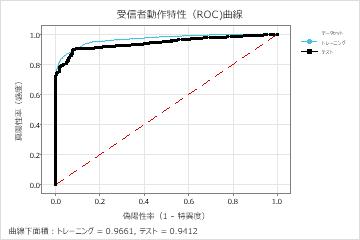
| ROC曲線下面積 | 0.9661 | 0.9412 |
| 95%信頼区間 | (0.9608, 0.9713) | (0.9295, 0.9529) |
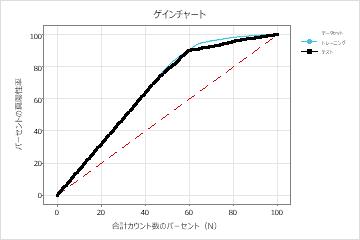
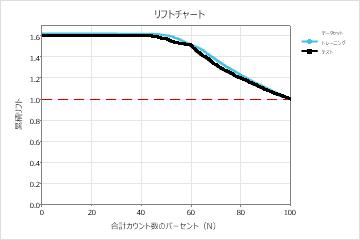
| リフト | 1.6176 | 1.5970 |
| 誤分類率 | 0.0970 | 0.0963 |
混同行列
| 予測クラス(トレーニング) | 予測クラス(テスト) | |||||||
|---|---|---|---|---|---|---|---|---|
| 実クラス | 計数 | 1 | 0 | %正 | 計数 | 1 | 0 | %正 |
| 1 (事象) | 2160 | 1942 | 218 | 89.91 | 943 | 846 | 97 | 89.71 |
| 0 | 1334 | 121 | 1213 | 90.93 | 563 | 48 | 515 | 91.47 |
| すべて | 3494 | 2063 | 1431 | 90.30 | 1506 | 894 | 612 | 90.37 |
| 統計量 | トレーニング(%) | テスト(%) |
|---|---|---|
| 真陽性率(感度または検出力) | 89.91 | 89.71 |
| 偽陽性率(第一種過誤) | 9.07 | 8.53 |
| 偽陰性率(第二種過誤) | 10.09 | 10.29 |
| 真陰性率(特異度) | 90.93 | 91.47 |
誤分類
| トレーニング | テスト | |||||
|---|---|---|---|---|---|---|
| 実クラス | 計数 | 誤分類されました | %誤差 | 計数 | 誤分類されました | %誤差 |
| 1 (事象) | 2160 | 218 | 10.09 | 943 | 97 | 10.29 |
| 0 | 1334 | 121 | 9.07 | 563 | 48 | 8.53 |
| すべて | 3494 | 339 | 9.70 | 1506 | 145 | 9.63 |