注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
重要な変数
Minitab統計ソフトウェアは、Random
Forests® 回帰
順列法で変数の重要度を決定します。順列メソッドは、アウトオブバッグデータを使用します。特定のツリーjの分析ではアウトオブバッグデータをツリーで分類します。フォレスト内のすべてのツリーについて予測を繰り返します。次に、アウトオブバッグデータに少なくとも1回表示される各行に対してアウトオブバッグ予測の平均を計算します。予測を使用して、アウトオブバッグデータの平均二乗誤差を計算します。
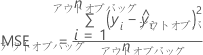
ここで、
| 用語 | 説明 |
|---|---|
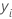 | 行 iの応答変数の値 |
 | フォレスト全体で、アウトオブバッグデータに表示される行の数 |
 | 行 iのアウトオブバッグ予測 |
次に、アウトオブバッグデータ全体で変数の値xmをランダムに順序を変えます。応答値と他の予測値は同じままにします。次に、同じステップを使用して、順序を変えたデータの平均二乗誤差を計算します
 .
.
変数xmの重要度は、2つの平均二乗誤差の差から来ています。
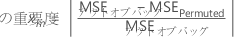
Minitabでは、10–7 未満の値は0に四捨五入されます。
分析内のすべての変数に対してこのプロセスを繰り返します。最も高い重要度を持つ変数が、最も重要な変数です。相対変数重要度スコアは、最も重要な変数の重要度によってスケ-リングされます。

アウトオブバッグとテスト予測
以下のモデル精度の測定値の予測計算は、検証方法によって異なります。アウトオブバッグの予測は、行がアウトオブバッグである木のみに由来します。特定のツリーjの分析ではアウトオブバッグデータをツリーで分類します。フォレスト内のすべてのツリーについて予測を繰り返します。次に、アウトオブバッグデータに少なくとも1回表示される各行に対してアウトオブバッグ予測の平均を計算します。アウトオブバッグデータを使用したモデルの評価では、応答変数の平均は、アウトオブバッグデータ内のすべての行の平均です。
テストデータセットの場合、フォレスト内の各ツリーを使用して、テストデータ セットの各値を予測します。次に、すべてのツリーからの予測を平均化して、モデルの予測を取得します。テストセットを使用したモデルの評価では、平均応答はテストセットの行の平均です。
R二乗
R2の計算では、アウトオブバッグデータまたはテストデータが使用されます。予測は、この2つの場合で異なります。一般に、R2 の式は以下のようになります。

二乗平均平方根誤差 (RMSE)

平均二乗誤差 (MSE)
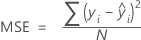
平均絶対偏差 (MAD)
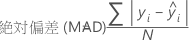
平均絶対パーセント誤差 (MAPE)

表記
| 用語 | 説明 |
|---|---|
| yi |  観測された応答値 観測された応答値 |
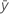 | 平均応答 |
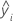 | 行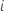 |
| N | 行数 |