このトピックの内容
CARTは、cを計算するために、隣接する2つの値の平均を常に使用します。N個の個別値をもつ連続変数は、親ノードについて、最大N – 1個の可能性がある分岐を生成します。解析では、最小ノードサイズが1より大きい場合、可能性がある分岐の実際の数は小さくなります。
{c1, c2, c3, .., ck} のカテゴリー変数Xの場合、分割は左のノードに送られる水準のサブセットです。k個の水準があるカテゴリ変数は、最大 2k - 1の分岐を生成します。
木の成長段階で可能性がある分岐について、改善基準は最小二乗 (LS) または最小絶対偏差 (LAD) のいずれかです。木に最高の改善を与えた分岐が追加されます。2 つの予測変数の改善が同じである場合、アルゴリズムを続行するには選択が必要です。選択では、ワークシート内の予測変数の位置、予測変数のタイプ、およびカテゴリ予測変数のクラス数を含む確定的な結合スキームが使用されます。
Minitabでは、解析にモデル検証方法が含まれている場合にのみ、トレーニングデータからの改善度が計算されます。次式を使用して、各基準の改善度を計算します。
最小二乗 (LS)

ここで

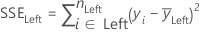

最小絶対偏差 (LAD)

ここで

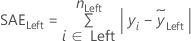

表記
| 用語 | 説明 |
|---|---|
| SSE | 平方誤差の合計 |
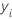 | ノード内の i番目 レコード |
| SAE | 絶対誤差の合計 |
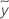 | ノードの応答の中央値 |
代理変数の分岐
最適な分岐を特定した後、他の可能性がある分岐の中で代理変数による分岐が探されます。代理変数の分岐は、記録が左と右のノードに移動する最適な分岐に類似しています。類似の尺度は関連です。
1の関連は、代理変数の分岐が最適な分岐を再現することを示します。関連が0の場合、最適な分岐の記録数が多いノードにすべての記録が送られます。正の関連による分岐は、可能な代理変数です。代理変数による分岐の改善度は、変数重要度の計算にあります。
分岐を形成する予測変数の欠損値が新しいデータに含まれる場合、Minitabは木に表示される予測変数ではなく、最適な欠損していない代理の予測変数を使用します。