合計予測変数
木で使用できる合計予測変数。これは、指定した連続予測変数とカテゴリ予測変数の総数です。
重要な予測変数
木の重要な予測変数の数。重要な予測変数は、最良の分岐変数または代理変数として使用される変数です。
解釈
相対変数重要度プロットを使用して、相対変数の重要度の順序を表示することができます。たとえば、20個の予測変数のうち10個がその木で重要であるとします。
ターミナルノードの数
ターミナルノードは、それ以上分岐できない最終ノードです。
解釈
ターミナルノード情報を使用して予測を行うことができます。
最小ターミナルノードサイズ
最小ターミナルノードサイズは、ケースの数が最も少ないターミナルノードのサイズです。
解釈
デフォルトでは、ターミナルノードで許容される最小ケース数は3ケースに設定されます。ただし、木の最小ターミナルノードサイズは、分析で許可されている最小数よりも大きくなる場合があります。このしきい値は、オプションサブダイアログボックスで変更できます。
R二乗
R2は、モデルによって説明される応答の変動のパーセントです。外れ値は、平均絶対偏差 (MAD) や 平均絶対パーセント誤差 (MAPE) に対してよりも、 R2に大きな影響を与えます。
検証法を使用する場合、表にはトレーニングデータセットのR2統計量とテストデータセットのR2統計量が含まれます。検証法がK分割交差検証の場合、テストデータセットは木の生成において除外される各分割になります。通常、テストのR2統計量は、新しいデータに対してモデルがどのように働くかについての、優れた指標です。
解釈
R2を使用して、モデルがデータにどの程度適合するかを判断します。R2値が高いほど、モデルが良好にデータに適合します。R2は常に0%から100%の間です。
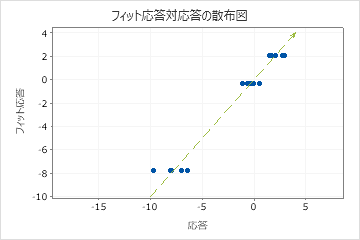
テストのR2がトレーニングのR2より大幅に小さい場合は、木が現在のデータセットに適合するほどは新しいケースの応答値を予測しない可能性があることを示します。
二乗平均平方根誤差 (RMSE)
二乗平均平方根誤差 (RMSE) は、木の正確性を評価します。外れ値は、MADやMAPEに対してよりも、RMSEに大きな影響を与えます。
検証法を使用する場合、表にはトレーニングデータセットのRMSE統計量とテストデータセットのRMSE統計量が含まれます。検証法がK分割交差検証の場合、テストデータセットは木の生成において除外される各分割になります。通常、テストのRMSE統計量は、新しいデータに対してモデルがどのように働くかについての、優れた指標です。
解釈
さまざまな木の適合値を比較するためにを使用します。値が小さいほど、適合性が高いことを示します。トレーニング RMSE よりも大幅に大きいテスト RMSE は、ツリーが現在のデータ セットに適合するだけでなく、新しいケースの応答値を予測しない可能性があることを示します。
平均二乗誤差 (MSE)
平均二乗誤差 (MSE)は、木の正確性を測定します。外れ値は、MADやMAPEに対してよりも、MSEに大きな影響を与えます。
検証法を使用する場合、表にはトレーニングデータセットの誤差のMSE統計量とテストデータセットのMSE統計量が含まれます。検証法がK分割交差検証の場合、テストデータセットは木の生成において除外される各分割になります。通常、テストのMSE統計量は、新しいデータに対してモデルがどのように働くかについての、優れた指標です
解釈
さまざまな木の適合値を比較するためにを使用します。値が小さいほど、適合性が高いことを示します。トレーニング MSE よりも大幅に大きいテスト MSE は、ツリーが現在のデータ セットに適合するだけでなく、新しいケースの応答値を予測しない可能性があることを示します。
平均絶対偏差 (MAD)
平均絶対偏差(MAD)は、データと同じ単位で正確性を表し、誤差の量を概念化するのに役立つます。外れ値は、R2、RMSE、およびMSEに対してよりも、MADに対する影響が少ないです。
検証法を使用する場合、表には、トレーニングデータセットの MAD統計量とテストデータセットのMAD統計量が含まれます。検証法がK分割交差検証の場合、テストデータセットは木の生成において除外される各分割になります。通常、テスト MAD統計は、新しいデータに対してモデルがどのように働くかについての、優れた指標です
解釈
さまざまな木の適合値を比較するためにを使用します。値が小さいほど、適合性が高いことを示します。トレーニング MAD よりも大幅に大きいテスト MAD は、ツリーが現在のデータセットに適合するだけでなく、新しいケースの応答値を予測しない可能性があることを示します。
平均絶対パーセント誤差 (MAPE)
平均絶対パーセント誤差(MAPE)では、精度を誤差のパーセント値として表します。MAPEはパーセント値であるため、他の精度の測度を表す統計量よりも容易に理解できます。たとえば、MAPE が平均で0.05の場合、適合誤差とすべてのケースの実際の値の平均比率は5%になります。外れ値は、R2、RMSE、およびMSEに対してよりも、MAPEに対する影響が少ないです。
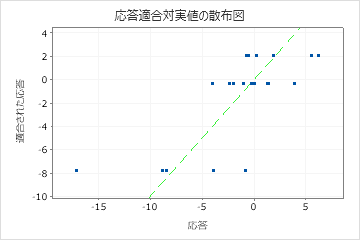
しかし、木がデータに良好に適合しているように見えても、非常に大きなMAPE値が表示されることがあります。適合値と実応答値のプロットを調べて、データ値が0に近いかどうかを調べます。MAPEは絶対誤差を実際のデータで割るため、0に近い値はMAPE を大きく増大させる可能性があります。
検証法を使用する場合、表にはトレーニングデータセットの MAPE統計量とテストデータセットのMAPE統計量が含まれます。検証法がK分割交差検証の場合、テストデータセットは木の生成において除外される各分割になります。通常、テストのMAPE統計量は、新しいデータに対してモデルがどのように働くかについての、優れた指標です。
解釈
さまざまな木の適合値を比較するためにを使用します。値が小さいほど、適合性が高いことを示します。トレーニング MAPE よりも大幅に大きいテスト MAPE は、ツリーが現在のデータ セットに適合するだけでなく、新しいケースの応答値を予測しない可能性があることを示します。