ある医療機関が、薬物乱用治療サービスを提供する施設を運営しています。この施設のサービスの1つは、通常の治療コースが1日から30日間続く可能性がある外来解毒プログラムです。人員配置と補給品の予測を担当するチームは、患者がプログラムに加入するときに患者に関して収集できる情報に基づいて、患者がサービスを利用する期間の長さについて、より良い予測を行うことができるかどうかを調査したいと考えています。これらの変数には、人口統計情報と患者の薬物乱用に関する変数が含まれます。
まず、Minitabの従来の回帰分析を検討します。データに欠損値パターンがあるため、分析ではデータの 70% 以上が省略されています。このような大量のデータが除かれるということは、多くの情報が失われていることを意味します。データが欠損していないケースの分析結果は、データセット全体を使用する結果とは大きく異なる場合があります。CART® 回帰 予測変数の欠落値を自動で処理するため、チームはデータをさらに評価するために CART® 回帰 を使うことに決めました。
- サービスの長さ.MWXサンプルデータを開きます。
- を選びましょう。
- 応答に ‘サービス期間’を入力してください。
- 連続予測変数に’入学時の年齢’から’教育の年’を入力してください。
- カテゴリ予測変数に’その他の刺激剤の使用’から’DSM 診断’を入力してください。
- 検証をクリックします。
- 検証法でK分割交差検証を選択します。
- ID列ごとに各分割の行を割り当てる を選択します。
- ID列にを入力します倍。
- 各ダイアログボックスのOKをクリックします。
結果を解釈する
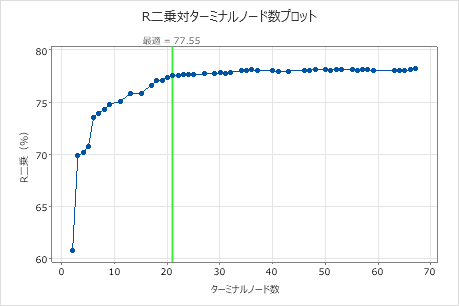
デフォルトでは、最大R2値をもつ木の1標準誤差内のR2値をもつ最小の木が表示されます。ヘルスケアチームはK分割検証を使用するため、基準は最大K分割R2値です。この木には21個のターミナルノードがあります。
代替木を選択
- 出力で、代替木を選択をクリックします。
- プロットで、17個のノードがある木を選択します。
- 木を作成をクリックします。
結果を解釈する
研究者は、交差検証からのR2統計量とターミナルノードの数のプロットを考察します。17個のノードがある木がプロット上の最大値に近いR2統計量をもつため、残りの出力の結果は17個のノードがある木に関するものです。
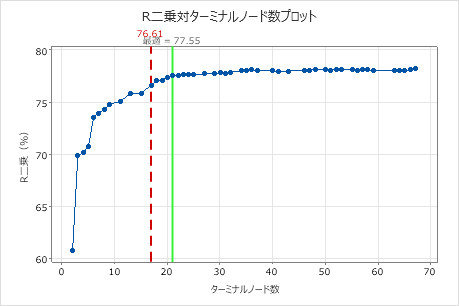
研究者たちはまずモデルの概要を見て、小さい木の性能を評価します。トレーニング統計量とクロスバリデーション統計量の値は近くにあるため、木が過剰適合しているようには見えません。R2統計量は21個のノードの木とほぼ同じ高さであるため、研究者は17個のノードがある木を使用して、予測変数と応答値の関係を調べます。
方法
| ノード分岐 | 最小二乗誤差 |
|---|---|
| 最適木 | 最大R二乗の2.5標準誤差内 |
| モデル検証 | 倍で定義された行との交差検証 |
| 使用中の行 | 4453 |
応答情報
| 平均 | 標準偏差 | 最小 | Q1 | 中央値 | Q3 | 最大 |
|---|---|---|---|---|---|---|
| 17.5960 | 9.29097 | 1 | 10 | 18 | 26 | 30 |
モデル要約
| 合計予測変数 | 44 |
|---|---|
| 重要な予測変数 | 33 |
| ターミナルノード数 | 17 |
| 最小終端節サイズ | 49 |
| 統計量 | トレーニング | 交差検証 |
|---|---|---|
| R二乗 | 77.99% | 76.61% |
| 二乗平均平方根誤差(RMSE) | 4.3585 | 4.4932 |
| 平均平方誤差 (MSE) | 18.9967 | 20.1887 |
| 平均絶対偏差 (MAD) | 3.4070 | 3.5226 |
| 平均絶対パーセント誤差(MAPE) | 0.6535 | 0.6674 |
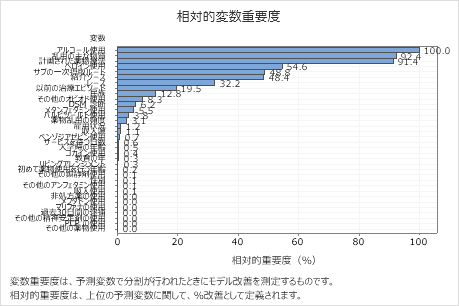
- 乱用の主な物質 そして 計画された薬物療法 は、約92%ほど重要 アルコール使用。
- ヘロイン使用 アルコール使用の約55%の重要性です。
- サブの一次摂取ルート そして 紹介ソース は、約48%ほど重要 アルコール使用。
これらの結果には、確かに重要な33個の変数が含まれますが、相対順位が、特定の応用に関して制御または監視する変数の数に関する情報を提供します。ある変数から次の変数への相対重要度値の急な低下は、どの変数を制御するかまたは監視するかの決定を導くことができます。たとえば、これらのデータでは、3 つの最も重要な変数重要度値は、次の変数に対する相対重要度が40%近く低下する前の比較的近い値になります。同じように、3つの変数の重要度は類似した50%近くです。さまざまなグループから変数を削除し、分析をやり直して、さまざまなグループの変数がモデル要約表の予測の正確性の値にどのように影響するかを評価できます。
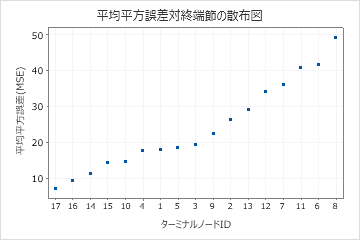
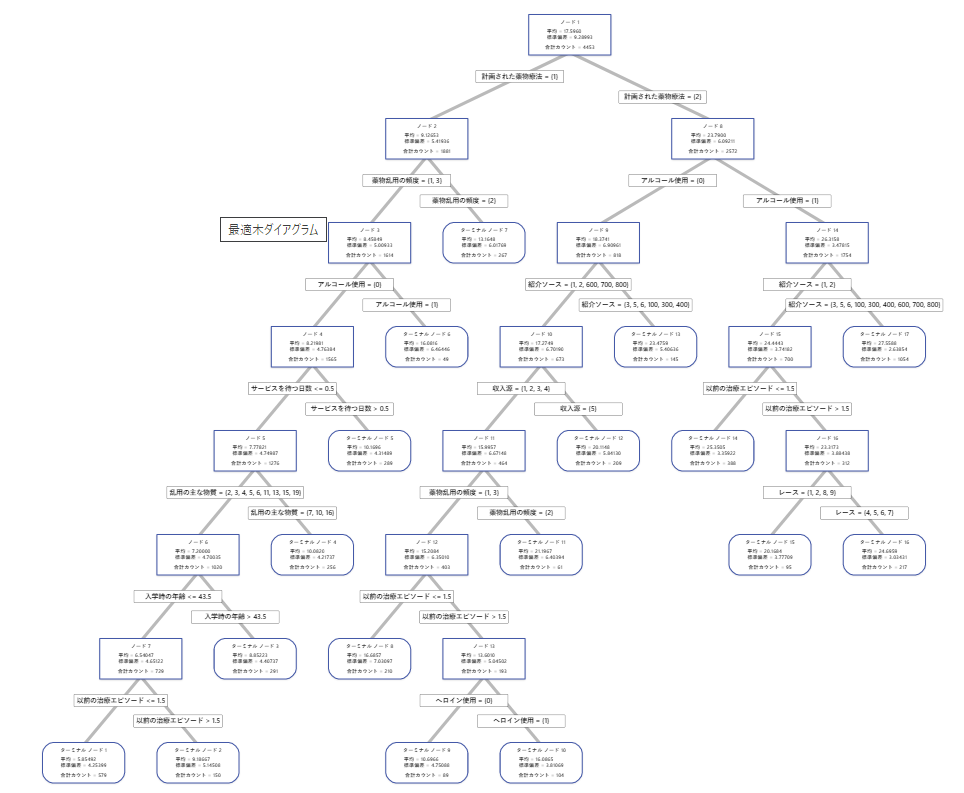
K分割交差検証を使用した分析では、ツリー図は、すべてのデータセットからのすべての4453ケースを示しています。詳細ビューとノード分岐ビューの間で、木のビューを切り替えることができます。適合値と誤差の統計量の表と、対象を分類するための基準は、ターミナルノードに関する追加情報を提供します。
- ノード2には 計画された薬物療法 = 1の場合が含まれます。このノードには1881ケースがあります。ノードの平均は全体の平均より小さいです。ノード2の標準偏差は約5.4で、分割することでより多くの純粋なノードが得られるため、全体の標準偏差より小さいです。
- ノード8には 計画された薬物療法 = 2の場合が含まれます。このノードには2572ケースがあります。ノードの平均は全体平均を超えています。ノード8の標準偏差は約6.1で、これも全体の標準偏差より小さいです。
次に、ノード2は 薬物乱用の頻度 分かれ、ノード8は アルコール使用分岐します。終端ノード17は、 計画された薬物療法 = 2、 アルコール使用 = 1、 紹介ソース = 3、5、6、100、300、400、600、700、または800のケースを持ちます。研究者たちは、ターミナルノード17が最も平均が高く、標準偏差が最も小さく、ケースも多いと指摘しています。
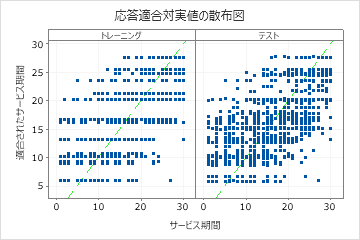
結果には、適合した応答値と実際の応答値の散布図が含まれます。トレーニングデータセットとクロスバリデーション結果セットのポイントは類似したパターンを示しています。この類似性は、新しいデータに対する木のパフォーマンスが、トレーニングデータに対する木のパフォーマンスに近いことを示唆しています。
- 計画された薬物療法 = {2}
- アルコール使用 = {0}
- 紹介ソース = {1, 2, 600, 700, 800}
- 収入源 = {1, 2, 3, 4}
- 薬物乱用の頻度 = {1, 3}
- 以前の治療エピソード <= 1.5
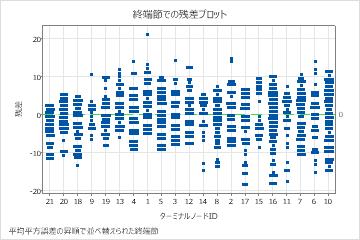
末端ノードごとの残差プロットは、エンドポイント8の少数患者群に対してフィットが大きすぎることを示しています。分析者は、これらの患者の一部がグループの典型的な患者よりも短い期間サービスを利用する理由の調査を検討します。例えば、これらの患者がターミナルノード内の他の患者とは異なる地理的場所にある場合、異なる政府や保険規制がサービスの利用期間に影響を与える可能性があります。
終端ノードごとの残差のプロットは、分析者がクラスタや外れ値の調査を選択できる他のケースを示しています。例えば、これらのデータでは、ターミナルノード1とターミナルノード7で他の残差よりもはるかに大きく見える残差が一つあります。分析官たちは、これらの患者が他の患者よりも長くサービスを利用した理由を調査することにしました。
クロスバリデーションのR2 値には改善の余地があり、残差プロットは木がうまく適合していないケースを示すため、研究者たちは適合度を改善するために TreeNet® 回帰 か Random Forests® 回帰 のどちらを使うかを検討しています。