トレーニングデータセットまたは検証なし
トレーニングデータセットのチャートでは、チャート上の各点は、木のターミナルノードを表します。事象確率が最も高いターミナルノードは、チャート上の最初の点で、左端に表示されます。その他のターミナルノードは、事象確率が減少する順に並んでいます。
次の手順を使用して、点のx座標とy座標を計算します。
- 各ターミナルノードの事象確率を計算します。
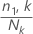
- n1,kは、k番目のノードの事象クラスのケースの数です。
- Nkはk番目のノードにあるケースの数です。
- ターミナルノードを最高から最低の事象確率にランク付けします。
- 各事象確率をしきい値として使用します。ある特定のしきい値に関して、推定された事象確率がしきい値以上の場合は予測クラスとして1となり、それ以外の場合は0となります。次に、観測されたクラスを行とし、予測されたクラスを列として、すべての場合に対して2x2の表を形成し、各ターミナルノードに関連する真陽性率を計算することができます。
たとえば、次の表に、4つのターミナルノードがある木を要約するとします。
A:ターミナルノード B:事象の数 C:ケースの数 D:しきい値 (B/C) 4 18 30 0.60 1 25 67 0.37 3 12 56 0.21 2 4 36 0.11 合計 59 189 次に、対応する4つの表と、それぞれの真陽性率を小数点以下2桁で示します。
表 1. しきい値 = 0.60. 真陽性率 = 18 / 59 = 0.31 予測 事象 非事象 観測 事象 18 41 非事象 12 118 表 2. しきい値 = 0.37. 真陽性率 = (18 + 25) / 59 = 0.73 予測 事象 非事象 観測 事象 43 16 非事象 54 76 表 3. しきい値 = 0.21. 真陽性率 = (18 + 25 + 12) / 59 = 0.93 予測 事象 非事象 観測 事象 55 4 非事象 98 32 表 4. しきい値 = 0.11. 真陽性率 = (18 + 25 + 12 + 4) / 59 = 1 予測 事象 非事象 観測 事象 59 0 非事象 130 0 - 並び替えられたターミナルノードから、ターミナルノード内の母集団に対するパーセントを計算します。

- Nkはk番目のノードにあるケースの数です。
- N は、トレーニングデータセット内のケースの数です。
- 並び替えられたリストから、各ターミナルノードのデータの累積パーセントを計算します。これらの累積値は、チャート上のx座標になります。
たとえば、予測確率が最も高いターミナルノードにデータの0.16が含まれ、2番目に高い事象確率のターミナルノードに母集団の0.35が含まれている場合、最初のターミナルノードのデータの累積パーセントは0.16で、 2番目のターミナルノードの母集団に対する累積パーセントは0.16 + 0.35 = 0.51です。
- y座標の累積リフトを求めるには、真陽性率を母集団に関する累積パーセントで除算します。

次の表は、小さな木の計算例を示しています。値は小数点以下2桁です。
| A:ターミナルノード | B:事象の数 | C:ケースの数 | D:並べ替えのための事象確率 (B/C) | E:真陽性率 | F:データのパーセント (C/Cの合計) | G:データの累積パーセント、x座標 | H:累積リフト(E/G)、y座標 |
|---|---|---|---|---|---|---|---|
| 4 | 18 | 30 | 0.60 | 0.31 | 0.16 | 0.16 | 1.92 |
| 1 | 25 | 67 | 0.37 | 0.73 | 0.35 | 0.51 | 1.42 |
| 3 | 12 | 56 | 0.21 | 0.93 | 0.30 | 0.81 | 1.15 |
| 2 | 4 | 36 | 0.11 | 1 | 0.19 | 1.00 | 1 |
別のテストデータセット
トレーニングデータセットのケースと同じステップを使用しますが、テストデータセットのケースから事象確率を計算します。
K分割交差検証を使用したテスト
累積リフトチャートで、K分割交差検証を使用してx座標とy座標を定義する手順には、追加のステップがあります。このステップにより、多くの異なる事象確率が生成されます。たとえば、ツリー図に4つのターミナルノードがあるとします。私たちは10分割交差検証を行います。次に、i番目の分割に対して、データの9/10部分を使用して、分割iのケースの事象確率を推定します。このプロセスが各分割に対して繰り返されると、個別の事象確率の最大数は 4 ×10 = 40 になります。その後、すべての個別の事象確率を降順に並べ替えます。データセット全体の場合に関して予測クラスを割り当てるには、各しきい値として事象確率を使用します。このステップの後、トレーニングデータセットの3から最後までのステップを適用して、x座標とy座標を計算します。