主成分
主成分抽出法では、j番目の負荷量は、j番目の主成分のスケール化された係数です。因子は、最初のm個の成分と関係があります。無回転の解では、主成分分析の成分を解釈するように因子を解釈できます。ただし、回転させると、主成分に似た因子をもう解釈できなくなります。
固有値ー固有ベクトルのペア(λi, ei)、i = 1, ...,pとλ1 ≤ λ2 ≤ ... ≤ λpの観点から、サンプル相関行列R(または共分散行列S)の主成分因子分析が指定されます。m < pを共通因子の数とします。推定された因子負荷量の行列は、p × m行列のLであり、この行列のi列目は次のようになります。 (i = 1, ..., m)
(i = 1, ..., m)
最尤法
最尤法では、データが多変量正規分布に従うものとして、因子負荷量を推定します。その名前が示すとおり、この方法では、多変量正規モデルと関係のある最尤関数を最大化することによって、因子負荷量と一意の分散の推定値を見つけます。同様に、残差の分散を含む式を最小化することで見つけることができます。このアルゴリズムは、最小値が見つかるまで、または指定された最大反復回数(デフォルトは25)に到達するまで反復します。
Minitabは、ヨレスコグの1、2に基づくアルゴリズムを、収束の改善のために微調整を行って使用します。ここでアルゴリズムの簡単な要約を行います。
p個の変数があり、m個の因子を持つモデルを適合したいとします。Rを変数のp × p相関行列、Lを因子負荷量のp × m行列、Ψを対角要素が一意の分散Ψiであるp × p対角行列とします。その後、尤度関数f(L,Ψ)を最大化するLとΨの値を見つける必要があります。この手順は2段階あり、まずΨの値を見つけ、Lを見つけます。
Ψの最初の値を間接的に指摘できます。因子分析のオプションサブダイアログボックスに、共通性の初期推定値の共通性の最初の値を含む列を入力します。Minitabは、Ψを(1ー共通性)として対角要素を計算します。
Ψが固定値の場合、Lでf(L,Ψ)を最大化します。これは簡単な行列計算です。Lの値をf(L,Ψ)に代入します。こうして、fをΨの関数として表示できます。この関数の簡単な変換が行われます。
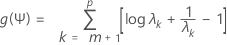
この式では、λ1 < λ2 < ... λpはΨ R- 1Ψの固有値です。ニュートン・ラフソン法を使用して、g(Ψ)を最小化します。これによりΨの推定値が求まり、尤度f(L,Ψ)に代入されます。その後、尤度を再びLで最大化します。さらに、g(Ψ)の新しい値などを計算します。デフォルトでは、反復は、収束しない限り、最大25ステップまで継続します。アルゴリズムが25ステップで収束しない場合、オプションサブダイアログボックスでデフォルトの最大反復回数を変更したいと思うかもしれません。
次のいずれかが真の場合、ステップnで収束します。
- 関数g(Ψ)は、連続するステップ間ではあまり変化しません。次の場合は特にそうなります。
- |(ステップnのg(Ψ)) − (ステップ(n − 1)のg(Ψ)) | < 10-6
- 連続するステップ間で大きく変化する一意の分散はありません。次の場合は特にそうなります。
- | ln(ステップnのΨi) − ln(ステップn − 1のΨi) | < K2
(すべてのiはi = 1, ... , p)式中、ΨiはΨのi番目の対角要素であり、変数iに対応する一意の分散です。
K2の値は、オプションサブダイアログボックスの収束で指定されます。デフォルトでは、値は0.005です。
結果サブダイアログボックスですべてとMLEでの反復を選択して、反復ごとの情報を表示します。目的関数g(Ψ)の値は表示され、最大値はln(Ψi)内で変化します。1回の反復でg(Ψ)の値が減少しない場合、小さい(半分のサイズの)ステップが行われます。ハーフステップはg(Ψ)が減少するまで、または25のハーフステップが行われるまで繰り返されます。ハーフステップ数が表示されます。g(Ψ)が25のハーフステップで減少しない場合、アルゴリズムは停止して、メッセージが表示されます。
2番目の導関数の行列は、g(Ψ)の最小化で使用されます。この行列は正の定数であるとは限りません。そうでない場合は、近似値が使用されます。Minitabが正しい行列を使用している場合、アスタリスクが結果に表示されます。
関数g(Ψ)を最小化するとき、0または負の数であるΨの対角要素の値を見つけることができます。これを防止するには、Minitabのアルゴリズムは、0から乖離するΨの対角要素に限界を設けます。特に、一意の分散ΨiがK2未満の場合、K2に等しく設定されます。K2は、オプションサブダイアログボックスの収束の項目に設定される値です。
アルゴリズムが収束すると、一意の分散に対して最後のチェックが実行されます。一意の分散のいずれかがK2未満の場合、0に設定されます。対応する共通性は、1に等しくなります。この結果は、ヘイウッドケースと呼ばれ、Minitabではメッセージを表示して、ユーザーにこの結果を通知します。最尤因子分析で使用されるアルゴリズムなどの最適化アルゴリズムは、入力内容がマイナーチェンジされても異なる解を求めることができます。たとえば、いくつかのデータ点を変更した、共通性の初期推定値の開始値を変更した、または収束の収束基準を変更した場合、因子分析結果の差を確認できます。このことは、解が最尤曲面の相対的に平らな場所にある場合は特にあてはまります。
負荷量の回転
直交回転は、因子負荷量を解釈しやすくするために因子負荷量を直交変換したものです。回転負荷量は、相関行列または共分散行列、残差行列、特定の分散、共通性を保持します。負荷量は変化するので、分散は各因子によって説明され、対応する比率は変化します。
回転は、可能な限り点の多い場所近辺に軸を設置し、因子を持つ変数の各グループを関連付けます。ただし、変数が複数の軸の近辺にあるため、複数の因子と関連付けられることもあります。
4つの回転方法から選択できます。
- エクイマックス:変数と因子の両方の平方負荷量の分散を最大化します。
- バリマックス:因子の平方負荷量の分散を最大化します。負荷量行列の列を単純化するこの方法は、最も広く使用されている回転方法です。解釈しやすくするには、この方法で負荷量を大きくしたり、小さくしたりすることを試します。
- コーティマックス:変数の平方負荷量の分散を最大化します。この方法は、負荷量行列の行を単純化します。
- γによるオーソマックス:パラメータガンマ(0~1)の値に応じて、上記の3つの方法によって構成される回転です。
因子分析モデル
因子分析モデルは次のようになります。
X = μ + L F + e
この式では、Xは測定値のp x 1ベクトル、μは平均のp x 1ベクトル、Lは負荷量のp × m行列、Fは共通因子のm × 1ベクトル、eは残差のp × 1ベクトルです。式中、pは被験者または項目に関する測定値の数を表し、mは共通因子の数です。Fとeは独立していると仮定し、個々のFは互いに独立しています。Fとeの平均は0、Cov(F) = Iは恒等行列、Cov(e) = Ψは対角行列です。Fは、独立しているという仮説により、直交因子モデルになります。
因子分析モデルでは、データのp × p共分散行列Xは次のように計算されます。
Cov(X) = L L' + Ψ
この式では、Lは負荷量のp × m行列、Ψはp × p対角行列です。負荷量の平方和L Lのi番目の対角要素はi番目の共通性と呼ばれます。共通性の値は、共通因子で説明されるばらつきの割合とみなすことができます。Ψのi番目の対角要素はi番目の特定の分散または特異性と呼ばれます。特定の分散は、共通因子では説明できないばらつきの比率です。共通性のサイズと特定の分散は適合値を評価するために使用できます。
負荷量
計算式
主成分法を使用する場合、推定因子負荷量の行列Lは次のようになります。
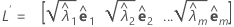
最尤法を使用する場合、因子負荷量の行列は反復処理を通じて取得します。
表記
| 用語 | 説明 |
|---|---|
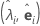 | 固有値ー固有ベクトルのペア |
共通性
計算式
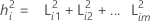
(i = 1, 2 ... p)
表記
| 用語 | 説明 |
|---|---|
| L | 因子負荷量の行列 |
分散
各因子によって説明されるデータのばらつきです。主成分を使用して因子を抽出する場合、分散は固有値と一致し、負荷量を回転させません。
分散%
計算式
相関行列を使用する場合、j番目の因子によって説明されるばらつきの比率は、次のように計算されます。


表記
| 用語 | 説明 |
|---|---|
| L | 因子負荷量の行列 |
| λj | j番目の固有値 |
| tr(R) | 相関行列のトレース |
| tr(S) | 共分散行列のトレース |
係数
計算式
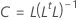
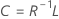
Rは相関行列です。係数の行列が共分散行列の場合、Rは共分散行列に置き換えられます。
表記
| 用語 | 説明 |
|---|---|
| L | 因子負荷量の行列 |
スコア
計算式
F = ZC
表記
| 用語 | 説明 |
|---|---|
| F | 因子スコアの行列 |
| Z | 標準化されたデータ |
| C | 因子スコア係数の行列 |