ステップ1:類似度と距離水準を調べる
併合工程のステップごとに、形成されたクラスターを表示し、類似度と距離水準を調べます。類似度水準が高くなるほど、各クラスターにある変数の類似性(相関性)が高くなります。距離水準が低くなるほど、各クラスターにある変数の距離が近くなります。
クラスターの類似度水準が相対的に高くなり、距離水準が相対的に低くなるのが理想的です。ただし、目標と合理的で実用的なクラスター数を持つこととのバランスを取る必要があります。
併合ステップ
| ステップ | クラスター数 | 類似度の水準 | 距離水準 | 結合されたクラス ター | 新しいクラスター | 新しいクラスタ ー内の観測値数 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
主要な結果:類似度水準と距離水準
これらの結果では、データには合計5つの変数が含まれます。ステップ1では、2つのクラスター(ワークシートの変数2と変数3)が結合されて、新しいクラスターが作成されます。これにより、データに4つのクラスターが作成され、類似度水準は93.9666、距離水準は0.130669となります。類似度水準は高く、距離水準は低くなるけれども、クラスター数が多すぎて役には立ちません。後続のステップごとに、新しいクラスターが作成されると、類似度水準は減少し、距離水準は増加します。最後のステップでは、すべての変数は結合されて、1つのクラスターになります。
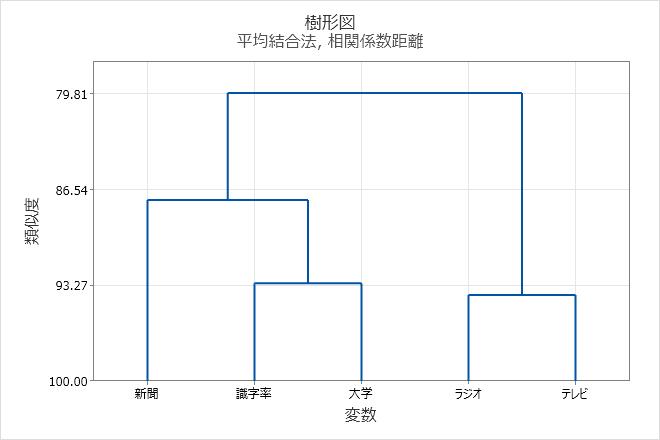
樹形図の類似度水準を表示するには、Minitabの枝分かれ図上の水平線にポインタを置きます。
ステップ2:データの最終グループ化を判断する
ステップごとに結合されたクラスターの類似度の水準を使用して、データの最終グループ化を判断しやすくします。ステップ間の類似度水準に急な変化があるかを確認します。類似度が急に変化する前のステップでは、最終分割に適した終止点が得られる可能性があります。最終分割では、クラスターの類似水準はかなり高くなる必要があります。データに関する実務知識も使用して、用途に最も適した最終グループ化を判断する必要があります。
たとえば、次の併合表は、類似度水準がステップ1(93.9666)からステップ2(93.1548)へとわずかに減少していることを示しています。類似度は、ステップ3(87.3150)で急に減少し、クラスターの数も3から2に変化します。これらの結果は、3つのクラスターが最終分割で適切になる可能性があることを示します。このグループ化が直観的な意味を持つとすれば、これが適していると考えられます。
併合ステップ
| ステップ | クラスター数 | 類似度の水準 | 距離水準 | 結合されたクラス ター | 新しいクラスター | 新しいクラスタ ー内の観測値数 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
主要な結果:類似度水準とクラスター数
最終グループ化に関する決定は、樹形図のカットとも呼ばれます。樹形図のカットは、樹形図に水平線を引いて、最終グループを指定することと同じです。たとえば、この樹形図をカットして4つのクラスターにする前に、垂直軸の下側周辺、およそ88の類似度水準のすぐ下に水平線を引くことを想像してみてください。
ステップ3:最終分割を調べる
ステップ2の最終グループ化を決定後、分析を繰り返して、最終分割のクラスター数(または類似度水準)を指定します。Minitabでは、最終分割表が表示され、最終分割の各クラスターの変数が示されます。
最終分割(パーティション)のクラスターを調べて、グループ化が用途に合わせて論理的に見えるかを判断します。まだ不明な場合、分析を繰り返して、別の最終グループ化の樹形図を比較して、データにとって最も論理的な樹形図を決定します。
併合ステップ
| ステップ | クラスター数 | 類似度の水準 | 距離水準 | 結合されたクラス ター | 新しいクラスター | 新しいクラスタ ー内の観測値数 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
最終分割 (パーティション)
| 変数 | |
|---|---|
| クラスター1 | 新聞 |
| クラスター2 | ラジオ テレビ |
| クラスター3 | 識字率 大学 |
主要な結果:最終分割、樹形図
これらの結果では、最終分割で3つのクラスターが作成されます。
- 人口1,000人当たりの新聞発行数
- ラジオとテレビの台数
- 識字水準と大学の有無
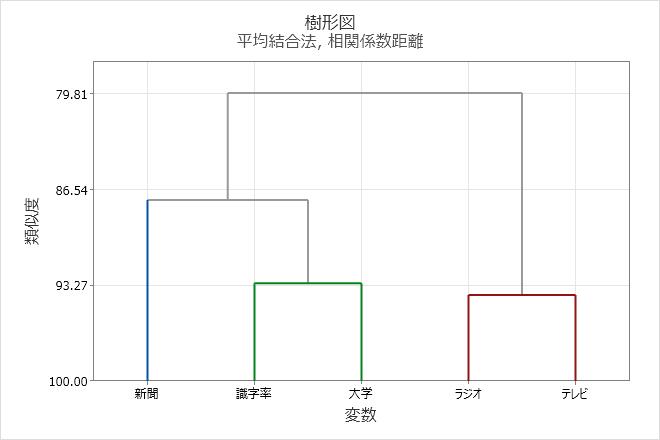
この樹形図は、3つのクラスターの最終分割を使用して、作成されます。各最終クラスターは異なる色で指定します。樹形図は、およそ88の類似度水準で「カット」されます。樹形図がこれより高い数値でカットされた場合、最終クラスター数は少なくなりますが、類似度水準は下がります。樹形図がこれより低い数値でカットされた場合、類似度水準は大きくなりますが、最終クラスター数は多くなります。