ステップ
クラスターを結合する併合手順のステップ数。ステップごとに、新しいクラスターは既存のクラスターと結合され、類似水準と距離水準が計算されます。
クラスター数
併合処理の各ステップで形成されるクラスター数。最初のステップの前に、クラスター数は(クラスター観測値の)観測値数の合計またはクラスター変数の個数の合計と等しいです。最初のステップでは、2つのクラスターを結合して、新しいクラスターを形成します。後続の各ステップでは、既存クラスターに別なクラスターを結合して、新しいクラスターを作成していきます。最終ステップでは、すべての観測値または変数が1つのクラスターに結合されます。
メインダイアログボックスにクラスター数を入力して、データの最終分割を指定できます。どの連結手法と距離スケールを選択するかによって、クラスター化の結果は大きく異なります。
類似度の水準
データの観測値間の最大距離を基準に算出される、各併合ステップのクラスター間の最小距離のパーセント。2つのクラスターiとj間の類似度s(ij)は、s(ij) = 100 * [1 - d(ij)) / d(max)]という式で得られます。この式で、d(max)は、iとj間の距離をd(ij)として表す元の距離行列(D)の最大値です。
解釈
ステップごとに結合されたクラスターの類似度の水準を使用して、データの最終グループ化を判断しやすくします。ステップ間の類似度水準に急な変化があるかを確認します。類似度が急に変化する前のステップでは、最終分割に適した終止点が得られる可能性があります。最終分割では、クラスターの類似水準はかなり高くなる必要があります。データに関する実務知識も使用して、用途に最も適した最終グループ化を判断する必要があります。
たとえば、次の併合表は、類似度の水準がステップ1(93.9666)からステップ2(93.1548)へとわずかに減少することを示しています。類似度は、クラスター数が3から2に変化するステップ3(87.3150)で急に減少します。これらの結果は、3つのクラスターが最終分割で適切になる可能性があることを示しています。このグループ化が直観的な意味を持つとすれば、これが適していると考えられます。
併合ステップ
| ステップ | クラスター数 | 類似度の水準 | 距離水準 | 結合されたクラス ター | 新しいクラスター | 新しいクラスタ ー内の観測値数 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
距離水準
各ステップで結合されるクラスター(選択したリンケージ法を使用)間または変数間(選択した距離スケールを使用)の距離。Minitabでは、メインダイアログボックスで選択したリンケージ法と距離の測度に基づいて距離水準を計算します。
2つの変数間の距離は相関値と直接関係します。つまり、変数が2つある場合、X1およびX2の距離は1−相関値と等しいです。たとえば、Corr(X1,X2) = 0.879の場合、距離(X1,X2) = 1 − 0.879 = 0.121となります。
解釈
各ステップで結合されたクラスターの距離水準を使用して、データの最終グループ化を決定しやすくします。ステップ間の距離水準の急な変化を確認します。距離の急な変化が起こる前のステップでは、最終分割の適切な終止点になることがあります。最終分割では、クラスターの距離水準をかなり小さくする必要があります。データに関する実務的な知識を使用して、用途に最も適した最終グループ化を決定する必要もあります。
たとえば、次の併合表は、距離水準がステップ1(0.120669)からステップ2(0.136904)へとわずかに上昇していることを示しています。ステップ3(0.253700)では、距離は急に増加し、クラスター数は3から2に変わります。これらの結果は、最終分割では、3つのクラスターが適切である可能性があることを示しています。これらの結果が直観的な意味を持つとすれば、これが適していると考えられます。
併合ステップ
| ステップ | クラスター数 | 類似度の水準 | 距離水準 | 結合されたクラス ター | 新しいクラスター | 新しいクラスタ ー内の観測値数 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
結合されたクラスター
併合処理のステップごとに新しいクラスターを形成するために結合された2つのクラスター。
新しいクラスター
併合処理のステップごとに形成される新しいクラスターの識別番号。新しいクラスターの識別番号は、必ず、結合される2つのクラスターの識別番号の小さい方の番号になります。たとえば、クラスター2とクラスター9を結合する場合、新しく形成されるクラスターはクラスター2になります。
新しいクラスターの観測値の数
併合処理のステップごとに形成される新しいクラスターの観測値数。最終ステップでは、すべての観測値は1つのクラスターに結合されます。このため、最後のステップでの新しいクラスターの観測値数はデータの観測値の合計数と等しくなります。
注
クラスター分析 - 変数では、観測値数は、新しいクラスターの変数の数のことです。
最終分割(パーティション)
メインダイアログボックスで最終分割を指定した場合、クラスターごとの変数のリストが表示されます。指定した用途に基づいて、最終分割の各クラスター内の変数を直観的にする必要があります。
樹形図
樹形図は、ステップごとに変数のクラスター化によって形成されるグループとこれらの類似度水準を表示します。類似度水準が縦軸に沿って測定され(距離水準を表示することもできます)、さまざまな変数が水平軸に沿って表示されます。
解釈
樹形図を使用して、ステップごとにクラスターが作成される方法を表示し、作成されたクラスターの類似度(または距離)の水準を評価します。
類似度(または距離)の水準を表示するには、Minitabの樹形図上の水平線にポインタを置きます。ステップ間で類似度または距離の値が変化するパターンは、データの最終グループ化を選択する際の参考になります。値が急激に変わるステップでは、適したデータ点を特定して、最終グループ化を定義します。
最終グループ化に関する決定は、樹形図のカットとも呼ばれます。樹形図のカットは、樹形図を横断する線を引いて、最終グループを指定することと同じです。樹形図と別の最終グループ化を比較して、データにとって最も意味のある樹形図を決定しやすくすることもできます。
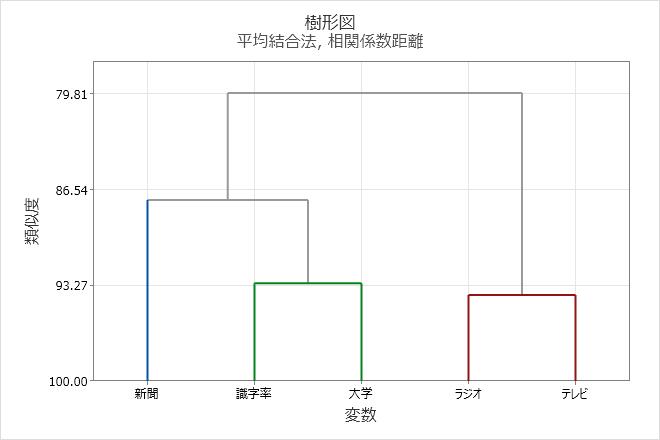
この樹形図は、3つのクラスターの最終分割を使用して、作成されます。各最終クラスターは異なる色で指定します。樹形図は、およそ88の類似度水準で「カット」されます。樹形図がこれより高い数値でカットされた場合、最終クラスター数は少なくなりますが、類似度水準は下がります。樹形図がこれより低い数値でカットされた場合、類似度水準は大きくなりますが、最終クラスター数は多くなります。
注
一部のデータセットでは、平均法、重心法、中央値法、およびウォード法によって階層構造の樹形図が作成されません。これは、併合距離が各ステップごとに常に増加するとは限らないことを示します。樹形図では、そのようなステップは上ではなく下に向かって進む結合を作成します。