このトピックの内容
ステップ1:応答に対して最大の効果を持つ項を特定する
標準化効果のパレート図は、主効果、二乗効果、交互作用効果について、相対的重要度と統計的有意性の両方を比較するために使用します。
Minitabでは、標準化効果をその絶対値の降順でプロットします。管理図上の参照ラインは、効果の有意性を示します。デフォルトでは、有意水準0.05で参照ラインが引かれます。
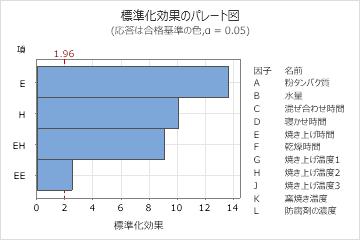
主要な結果:パレート図
この結果では、プロットには、モデルにある項のみが含まれます。このプロットでは、2つの主効果は統計的に有意です。2次項と交互作用項も統計的に有意です。
また、Eは最も長く伸びているため、これが最大の効果を持つこともわかります。EE2次項の効果の伸びは最も短いため、時間の効果は最小です。
ステップ2:応答に対して統計的に有意な効果を持つ項を特定する
- p値 ≤ α:関連性は統計的に有意である
- p値が有意水準以下の場合は、応答変数と項の間に統計的に有意な関連性が存在すると結論付けることができます。
- p値 > α:その関連性は統計的に有意ではない
- p値が有意水準より大きい場合は、応答変数と項の間に統計的に有意な関連性があると結論することはできません。項を持たないモデルを再適合したいと考えるかもしれません。
- 因子
- 因子の係数が有意である場合、事象の確率が全ての因子水準で同じではないと結論付けることができます。
- 因子間の交互作用
- 交互作用項の係数が有意な場合は、因子と応答の間の関係はその項の他の因子に依存します。こうしたケースでは、交互作用の影響の考慮なしに主効果を解釈すべきではありません。
- 2次項z
- 二乗項の係数が統計的に有意な場合は、因子と応答の間の関係が曲線になると結論付けることができます。
- 共変量
- 共変量の係数が統計的に有意な場合、応答と共変量の関連性は統計的に有意であると結論付けることができます。
- ブロック
- ブロックの係数が統計的に有意である場合、ブロックのリンク関数は平均値と異なると論付けることができます。
コード化係数
| 項 | 係数 | 係数の標準誤差 | VIF |
|---|---|---|---|
| 定数 | 2.394 | 0.145 | |
| 焼き上げ時間 | 0.7349 | 0.0538 | 1.11 |
| 焼き上げ温度2 | 0.5451 | 0.0541 | 1.20 |
| 焼き上げ時間*焼き上げ時間 | -0.384 | 0.153 | 1.04 |
| 焼き上げ時間*焼き上げ温度2 | -0.5106 | 0.0562 | 1.24 |
主要な結果:係数
この結果では、焼き上げ時間と焼き上げ温度2の係数は正の数です。焼き上げ時間の2次項の係数と焼き上げ時間と焼き上げ温度2の間の交互作用項の係数は負の数です。一般的に、項の値が増加するにつれ、係数が正の場合は事象の可能性は高くなり、係数が負の場合は事象の可能性は低くなります。
分散分析
| 要因 | 自由度 | 調整偏差 | 調整平均 | カイ二乗 | p値 |
|---|---|---|---|---|---|
| モデル | 4 | 737.452 | 184.363 | 737.45 | 0.000 |
| 焼き上げ時間 | 1 | 203.236 | 203.236 | 203.24 | 0.000 |
| 焼き上げ温度2 | 1 | 100.432 | 100.432 | 100.43 | 0.000 |
| 焼き上げ時間*焼き上げ時間 | 1 | 6.770 | 6.770 | 6.77 | 0.009 |
| 焼き上げ時間*焼き上げ温度2 | 1 | 80.605 | 80.605 | 80.61 | 0.000 |
| 誤差 | 45 | 32.276 | 0.717 | ||
| 合計 | 49 | 769.728 |
主要な結果:p値
この結果では、焼き上げ時間と焼き上げ温度2の主効果は、水準0.05のときに統計的に有意になります。この結果から、これらの変数の変化は応答変数の変化に関連付けられていると結論付けることができます。モデル内に高次項があるので、主効果の係数では、これらの因子の効果を完全には説明できません。
焼き上げ時間の二乗項は有意です。この結果から、これらの変数の変化は応答変数の変化に関連付けられているものの、その関係は線形ではないと結論付けることができます。
焼き上げ時間と焼き上げ温度2の間の交互作用の効果は有意です。焼き上げ時間における変化の色に関する効果が焼き上げ温度2の水準によって変わることを結論付けることができます。同様に、焼き上げ温度2における変化の色に関する効果が焼き上げ時間の水準によって変わることを結論付けることができます。
ステップ3:予測変数の効果を理解する
- 連続予測変数のオッズ比
- オッズ比が1より大きい場合、予測変数が増加するにつれて事象が発生する可能性が高くなることを示します。オッズ比が1未満の場合、予測変数が増加するにつれて事象が発生する可能性が低くなることを示します。
連続予測変数のオッズ比
変更ユニット オッズ比 95%信頼区間 焼き上げ時間 2 * (*, *) 焼き上げ温度2 15 2.1653 (1.9652, 2.3858) 主要な結果:オッズ比
これらの結果では、モデル内で焼き上げ時間、焼き上げ温度2および焼き上げ時間の二乗項の3つの項を持つプレッツェルの色が品質基準を満たしているかどうかを予測します。この例では、許容範囲の色は事象です。
変更単位には、計画内のコード化単位における自然単位の差が表示されます。たとえば、自然単位では、焼き上げ温度2の下限は127です。上限は157度です。下限から中点までの距離は、1コード化単位分の変化を表します。本ケースでこの距離は15度です。
焼き上げ温度2のオッズ比は約2.17です。温度が15度上昇する度に、プレッツェルの色が許容範囲になるオッズ比は約2.17倍増加します。
このモデルには焼き上げ時間の二乗項が含まれているので、焼き上げ時間のオッズ比が欠損しています。値は焼き上げ時間の値によって変わるので、オッズ比には固定値がありません。
- カテゴリ予測変数のオッズ比
-
カテゴリ変数の場合、オッズ比は、予測変数の2つの異なる水準に出現する事象のオッズを比較します。水準Aと水準Bの2つの列に水準を登録することによって比較を設定できます。水準Bは因子の参照水準です。オッズ比が1より大きい場合、事象は水準Aになる可能性が高くなることを示します。オッズ比が1未満の場合、事象は水準Aになる可能性が低くなることを示します。カテゴリ予測変数のコーディングに関する詳細はカテゴリ予測変数のコード化方式を参照してください。
カテゴリ予測変数のオッズ比
水準A 水準B オッズ比 95%信頼区間 月 2 1 1.1250 (0.0600, 21.0834) 3 1 3.3750 (0.2897, 39.3165) 4 1 7.7143 (0.7461, 79.7592) 5 1 2.2500 (0.1107, 45.7172) 6 1 6.0000 (0.5322, 67.6397) 3 2 3.0000 (0.2547, 35.3325) 4 2 6.8571 (0.6556, 71.7169) 5 2 2.0000 (0.0976, 41.0019) 6 2 5.3333 (0.4679, 60.7946) 4 3 2.2857 (0.4103, 12.7323) 5 3 0.6667 (0.0514, 8.6389) 6 3 1.7778 (0.2842, 11.1200) 5 4 0.2917 (0.0252, 3.3719) 6 4 0.7778 (0.1464, 4.1326) 6 5 2.6667 (0.2124, 33.4861) 主要な結果:オッズ比
この結果では、カテゴリ予測変数はホテルの繁忙期の開始月です。応答は、宿泊客が予約をキャンセルするかどうかです。この例ではキャンセルは事象です。最大オッズ比は7.71で、水準Aが4か月目のときと水準Bが1か月目のときが当てはまります。これは、宿泊客が4か月目に予約をキャンセルするオッズは、宿泊客が1か月目に予約をキャンセルするオッズよりも約8倍高いことを示しています。
ステップ4:データに対するモデルの適合度を判断する
データに対するモデルの適合度を判断するために、モデル要約表の適合度統計量を調査します。
注
モデル要約統計量と適合度統計量の多くは、データがワークシートでどのように配置されているか、行あたりで1回の試行なのか複数の試行なのか、の影響を受けます。ホスマー-レメショウ検定は、データの配置に影響されず、行ごとで1回の試行の場合と複数の試行の場合とで比較されます。詳細は、データフォーマットが2値ロジスティック回帰の適合値に与える影響を参照してください。
- 逸脱度R二乗
-
逸脱R2値が大きくなるほど、データへのモデル適合度は上がります。逸脱R2は必ず0~100%の間の値になります。
逸脱度R2はモデルに新しい項を追加すると必ず大きくなります。たとえば、最適な5項モデルの逸脱度R2は必ず、最適な4予測変数モデルと少なくとも同じ大きさになります。したがって、逸脱度R2値は同じ大きさのモデルの比較に最も便利です。
データの配置は逸脱度R2値に影響します。逸脱度R2は通常、行ごとに試行が1回の場合のデータより複数の試行の場合のデータの方が高くなります。逸脱度R2値は同じデータフォーマットのモデル間でのみ比較可能です。
適合度統計量は、データに対するモデルの適合度を測る1つの測度に過ぎません。モデルの値が望ましい場合でも残差プロットと適合度検定を確認してデータに対するモデルの適合度を評価する必要があります。
- 逸脱度R二乗(調整済み)
-
異なる数の項を持つモデルを比較する場合は、調整済み逸脱度R2を使用します。逸脱度R2はモデルに項を追加すると必ず大きくなります。調整済み逸脱度R2値にはモデルに含まれる項の数が組み入れられるため、正しいモデルの選択に役立ちます。
- AIC、AICc、BIC
- 異なるモデルを比較する際はAIC、AICc、BICを使用します。どちらの統計量でも、小さい値が好ましいと考えられます。ただし、予測変数セットに対して最小値を持つモデルは必ずしもデータに良好に適合しません。適合度検定と残差プロットも使用して、データに対するモデルの適合度を評価してください。
モデル要約
| 逸脱 (deviance) R二乗 | 逸脱 (deviance) R二乗 (調整済み) | AIC | AICc(修正済み 赤池情報量基準) | BIC(ベイズ 情報量基準) |
|---|---|---|---|---|
| 95.81% | 95.16% | 243.85 | 245.80 | 255.32 |
主要な結果:逸脱度R二乗、逸脱度R二乗(調整済み)、AICc、BIC
これらの結果を基に、モデルは、応答変数における総変動のおよそ95.81%を説明づけます。これらのデータでは、逸脱度R2値はデータに良好に適合するモデルを示します。追加的なモデルが異なる項と適合する場合は、調整済み逸脱度R2値、AIC値、AICc値、BIC値を使用して、どれほどモデルがデータに適合しているかを比較します。
ステップ5:データに適合しないモデルかどうかを判断する
- 不適切なリンク関数
- モデル内にある変数の高次項が省略されています
- モデル内にはない予測変数が省略されています
- 過分散
逸脱度が統計的に有意な場合、別のリンク関数を実行、あるいはモデル内の項を変更できます。
- 逸脱度:逸脱度検定のp値では、1行当たりの試行回数が1回に配置されているデータの方が、試行回数が複数回のデータよりも低い傾向があり、一般的には、試行回数が少なくなるほどp値も減少します。データフォーマットが1試行/行の場合は、ホスマー-レメショウ検定の結果の信頼度がより高くなります。
- ピアソン:ピアソン検定で使用する近似カイ二乗分布は、データに含まれる行ごとの事象の期待数が小さい場合は不正確になります。それゆえ、データのフォーマットが1試行/行の場合、ピアソンの適合度検定は不正確となります。
- ホスマー-レメショウ(Hosmer-Lemeshow):ホスマー-レメショウ検定は他の適合度検定のように、データ内の行ごとの試行回数にも左右されません。データの各行の試行回数がほとんどない場合、ホスマー-レメショウ検定は、データに対するモデルの適合度を示す指標として、信頼度が高まります。
適合度検定
| 検定 | 自由度 | カイ二乗 | p値 |
|---|---|---|---|
| 逸脱 (deviance) | 44 | 32.26 | 0.905 |
| ピアソン | 44 | 31.98 | 0.911 |
| Hosmer-Lemeshow | 7 | 4.18 | 0.758 |
事象 試行フォーマットの主要な結果:応答情報、逸脱度検定、ピアソン検定、ホスマー-レメショウ検定
これらの結果では、すべての適合度検定のp値は、通常の有意水準である0.05よりも大きいです。この検定は、二項分布が予測できないように、予測される確率が観測される確率から離れた値になることを示す根拠にはなりません。