調整平方和
調整平方和は、項をモデルに入力するときの順序に依存しません。調整平方和は、その他のすべての項が入力された順序にかかわらずモデル内に含まれる場合に、項によって説明される変動量を表します。
たとえば、3つの因子X1、X2、X3を扱うモデルがあった場合、X2の項が、調整平方和はX2の残りの変動にどれほど寄与しているのかを表します。モデル内のX1およびX3も同様です。
3つの因子の調整平方和の計算式は以下になります。
- SSR(X3 | X1, X2) = SSE (X1, X2) - SSE (X1, X2, X3)または
- SSR(X3 | X1, X2) = SSR (X1, X2, X3) - SSR (X1, X2)
上の式で、SSR(X3 | X1, X2)は、X1とX2がモデルに含まれる場合のX3の調整平方和です。
- SSR(X2, X3 | X1) = SSE (X1) - SSE (X1, X2, X3)または
- SSR(X2, X3 | X1) = SSR (X1, X2, X3) - SSR (X1)
上の式で、SSR(X2, X3 | X1)は、X1がモデルに含まれる場合のX2とX3の調整平方和です。
モデル1に4つ以上の因子がある場合はこの式を拡張して計算します。
- J. Neter、W. WassermanおよびM.H. Kutner(1985年)、Applied Linear Statistical Models第2版、Irwin, Inc.
平方和(SS)



Minitabでは、逐次平方和と調整平方和の両方を使って平方和モデルの成分を各項で説明される変動量に分解します。
表記
| 用語 | 説明 |
|---|---|
| b | 係数のベクトル |
| X | 計画行列 |
| Y | 応答値のベクトル |
| n | 観測値数 |
| J | 全て1のn×n行列 |
遂次平方和
Minitabでは、分散の平方和(SS)モデル成分を各因子項または因子項セットの遂次平方和に分解します。遂次平方和は、因子や予測変数をモデルに入力するときの順序によって異なります。逐次平方和は、過去に入力した項を前提とした項ごとに説明する平方和モデルの一意な部分です。
たとえば、X1、X2、およびX3という3つの因子を含むモデルがある場合、X2の遂次平方和は、X1がモデル内にすでに含まれている場合、X2によって説明される残りの変動の割合を示します。別の連続した項を得るには、分析を繰り返して異なる順序の項を入力します。
自由度(DF)
異なる平方和には異なる自由度があります。
数値因子 = 1の自由度
カテゴリ因子 = b − 1の自由度
2次項 = 1の自由度
ブロック = c − 1の自由度
誤差 = n − pの自由度
純粋誤差 = の自由度 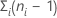
不適合度 = m − pの自由度
自由度の合計 = n − 1


注
Minitabのスクリーニング計画のカテゴリ因子には2つの水準があります。このため、カテゴリ因子の自由度は2 – 1 = 1です。したがって、因子間の交互作用の自由度も1です。
表記
| 用語 | 説明 |
|---|---|
| b | 因子の水準数 |
| c | ブロック数 |
| n | 観測値の総数 |
| ni | i番目の因子水準の組み合わせの観測値数 |
| m | 因子水準の組み合わせ数 |
| p | 係数の数 |
調整平均平方~モデル

表記
| 用語 | 説明 |
|---|---|
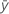 | 応答変数の平均 |
 | i番目の応答適合値 |
| p | 定数項を含まないモデル内の項の数 |
調整平均平方~項

調整平均平方…誤差
平均平方誤差(略はMS ErrorまたはMSE、表記はs2)は適合回帰線からの分散です。式は以下になります。

表記
| 用語 | 説明 |
|---|---|
| yi | i番目の観測された応答値 |
 | i番目の適合された応答 |
| n | 観測値数 |
| p | 定数を含まないモデル内の係数の数 |
F
F統計量の計算は、次のように、仮説検定によって変わります。
- F(項)
-

- F(不適合度)
-

表記
| 用語 | 説明 |
|---|---|
| 調整平均平方項 | モデル内に含まれるその他の項を説明した後、項によってどれだけの変動を説明できるかを測定する測度。 |
| 平均平方誤差 | モデルによって説明できない変動の測度。 |
| 平均平方不適合度 | モデルに項を追加することによってモデル化できる応答の変動を測定する測度。 |
| 平均平方純粋誤差 | 反復応答データの変動を測定する測度。 |
- J. Neter、W. Wasserman、M.H. Kutner(1985)、Applied Linear Statistical Models第2版、Irwin, Inc.
p値~分散分析表
p値は自由度(DF)が以下であるF分布から計算される確率です。
- 分子DF
- 項の自由度の和、または検定内の項
- 分母DF
- 誤差に対する自由度
計算式
1 − P(F ≤ fj)
表記
| 用語 | 説明 |
|---|---|
| P(F ≤ f) | F分布についての累積分布関数 |
| f | 検定におけるF統計量 |
p値~不適合検定
- 分子DF
- 不適合に対する自由度
- 分母DF
- 純粋誤差に対する自由度
計算式
1 − P(F ≤ fj)
表記
| 用語 | 説明 |
|---|---|
| P(F ≤ fj) | F分布についての累積分布関数 |
| fj | 検定におけるF統計量 |