前方情報基準法
- この手順では、8つの連続したステップの基準の改善は見つかりません。
- 手順は完全なモデルに適合します。
- 手順は誤差自由度が1つあるモデルに適合します。
前方選択手順
モデルにどの項を維持するかを判断する方法です。前方選択は、ステップワイズと同じ手順でモデルに予測変数を追加します。一度追加した予測変数は、削除されません。デフォルトでは、モデルに追加しようとする候補の変数に変数追加時のαで指定した値よりも小さなp値を持つものがなくなると、前方選択手順は終了します。
後方削除手順
モデルにどの変数を維持するかを判断する方法です。後方削除は、全ての項を含むモデルからスタートし、ステップワイズ手順と同じ方法で1つずつ項を削除していきます。一度取り除いた予測変数は、再度モデルに入れることはできません。デフォルトでは、モデルに含まれる変数に変数削除時のαで指定した値よりも大きなp値を持つものがなくなると、後方削除手順は終了します。
初期モデルですべての自由度を使用している場合、他の分析で使用しているので、要因計画の分析では停止できません。その代わり、要因計画の分析と変動性の分析を使用すれば、開始するのに十分な自由度を取得できるように、項の4分の1が削除されます。四捨五入したときに最も近い整数が、削除する項の数になり、9が最大数になります。飽和モデルにより、モデルの階層を維持したまま、最も小さい調整平方和を持つ項が削除されます。後続のステップでこれらの項が見直されることはありません。削除された項は、モデル選択詳細の表に一覧表示されます。
ステップワイズ法
F検定に基づき、現在のモデルに対し予測変数の追加または削除を行い、変数の選択を実行します。ステップワイズは、前方選択と後方削除の組み合わせです。
初期モデルですべての自由度を使用している場合、他の分析で使用しているので、要因計画の分析では停止できません。その代わり、要因計画の分析と変動性の分析を使用すれば、開始するのに十分な自由度を取得できるように、項の4分の1が削除されます。四捨五入したときに最も近い整数が、削除する項の数になり、9が最大数になります。飽和モデルにより、モデルの階層を維持したまま、最も小さい調整平方和を持つ項が削除されます。後続のステップでこれらの項が見直されることはありません。モデル選択詳細の表では削除された項が一覧表示されます。
取り除く変数
Minitabは、モデルの各変数に対してF統計量とp値を計算します。モデルにj個の変数がある場合、xr変数値に対するFは以下の計算式になります。

表記
| 用語 | 説明 |
|---|---|
| 誤差平方和(j – Xr) | xrを含まないモデルに対する誤差平方和 |
| 誤差平方和 j | xrを含むモデルに対する誤差平方和 |
| 平均平方誤差 j | xr を含むモデルに対する平均平方誤差 |
いずれかの変数に対するp値が変数削除時のαで指定した値より大きい場合、Minitabは最大のp値を持つ変数をモデルから取り除き、回帰式を計算し、結果を表示して次のステップを開始します。
追加する変数
Minitabが変数を取り除けない場合は、変数を追加しようとします。Minitabは、モデルにない各変数に対してF統計量とp値を計算します。モデルにj個の変数がある場合、xa変数値に対するFは以下の計算式になります。
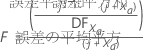
表記
| 用語 | 説明 |
|---|---|
| 誤差平方和 j | xa前の誤差平方和がモデルに追加されます。 |
| 誤差平方和(j + Xa) | xa後の誤差平方和がモデルに追加されます。 |
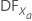 | 変数Xaの自由度 |
| 平均平方誤差(j + Xa) | xa後の平均平方誤差がモデルに追加されます。 |
いずれかの変数に対するF統計量に対応するp値が変数追加時のαで指定した値より小さい場合、Minitabは最小のp値を持つ変数をモデルに追加し、回帰式を計算し、結果を表示して新しいステップに移行します。これ以上変数を追加または削除できない場合は、ステップワイズの手順は終了します。