方法
Minitabでは、繰り返し測定値または反復測定値の標準偏差の分析において、最小二乗法と最尤法の2つの方法が使用されます。これらの方法は両方とも、対数リンク関数、ln(σ) = Aγの線形モデルに基づいており、この式でAは計画行列、γは推定するパラメータのベクトルを表しています。対数リンク関数を使う利点の1つとして、適合値が常に正数になるということが挙げられます。
これら2つの方法は、パラメータの数がデータ点の数と等しいとき、飽和モデルで同等の結果になります。
最小二乗推定では、重み付き最小二乗回帰が使用されます。繰り返し数や反復数が同じ場合、重みは等しくなります。
最尤推定法(MLE)では、元のデータが正規分布のデータであると仮定しています。サンプル分散の分布は、χ2分布に関係しています。
計画行列(M)
計画行列には、指定したモデルの適合に回帰を使用する一般線形モデル(GLM)に使用されるのと同じアプローチが使用されます。Minitabでは、まず因子と指定したモデルから計画行列が作成されます。この行列のXと呼ばれる列はモデルに含まれる項を表しています。
計画行列はn行(n=観測値の数)およびモデル内の各項に対するいくつかの列ブロックを持ちます。最初のブロックは定数のためのブロックで1列しかなく、すべての列の値は1です。連続因数のブロックもまた、1列しか持ちません。カテゴリ因子の列ブロックはr個の列を持ち、rは因子の自由度を表しています。
たとえば、ある一部実施要因計画に3つの要因があり、それぞれ2つの水準を持つとします。モデルには3つの主効果が含まれます。この場合、各行は次の中の1つにコード化されます。
| ブロック | 因子1 | 因子2 | 因子3 |
|---|---|---|---|
| 1 | −1 | −1 | −1 |
| 1 | 1 | −1 | −1 |
| 1 | −1 | 1 | −1 |
| 1 | 1 | 1 | −1 |
| 1 | −1 | −1 | 1 |
| 1 | 1 | −1 | 1 |
| 1 | −1 | 1 | 1 |
| 1 | 1 | 1 | 1 |
効果
各因子の推定効果です。効果は2水準モデルに対してのみ計算され、一般要因モデルに対しては計算されません。因子の効果の計算式は以下になります。
効果 = 係数 * 2
係数(Coef)
回帰式における回帰係数の母集団の推定値です。各因子において、k - 1の係数が計算され、kは因子に含まれる水準の数を表しています。2因子、2水準、完全実施モデルにおいて、因子と交互作用の係数を求める計算式は以下です。
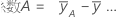
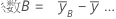

この2因子、2水準、完全実施モデルの係数の標準誤差は、以下です。

因子を2つより多く持つモデル、あるいは水準を2つより多く持つ因子に関する詳細は、Montgomeryの1を参照してください。
表記
| 用語 | 説明 |
|---|---|
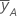 | 因子Aの高水準でのyの平均 |
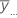 | すべての観測値の全体平均 |
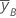 | 因子Bの高水準でのyの平均 |
 | 因子AおよびBの高水準でのyの平均 |
| 誤差の平均平方(MSE) | 誤差の平均平方 |
| n | 推定項の-1と1の数(共分散行列内) |
重み付き回帰
重み付き最小二乗回帰は、観測値の分散が不均一な場合に用いられる手法です。分散が一定でない場合、
- 観測値の分散が大きい場合は比較的小さい重みが与えられます
- 観測値の分散が小さい場合は比較的大きい重みが与えられます
重みは、各標準偏差の計算に使用される繰り返しや反復の数を反映します。基になるデータが多い標準残差の方が、受け取る重みが大きくなります。
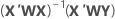
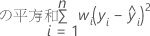
表記
| 用語 | 説明 |
|---|---|
| X | 計画行列 |
| X' | 計画行列の転置 |
| W | 対角線に重みを配置したn×n行列 |
| Y | 対数標準偏差値のベクトル |
| n | 観測値数 |
| wi | i番目の観測値の重み値 |
| yi | i番目の観測値の対数標準偏差値 |
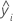 | i番目の観測値の対数標準偏差適合値 |
重みの計算
位置モデルを分析するときに使用するために、散布モデルに基づき適合分散や調整済み分散を使用して重みを計算、保存することができます。
- 1 / 適合分散
- σ2(実験間) + σ2 (実験内) / 繰り返し回数
「実験間」と「実験内」は実験の実行を表します。実験内の変動は、繰り返し観測値の標準偏差で測定する値です。実験間の変動は、新しい実行における変動の要因を意味します。
繰り返し間の標準偏差を分析すると、s(実験内)にモデルを適合することになります。反復がある場合、σ2(実験内)のモデルと反復の平均分散が組み合わされ、σ2(実験間)の推定値が取得されます。その後σ2(実験間)の推定値は、σ2(実験内) / 繰り返し回数 と再度組み合わされ、散布モデルと一致する平均値の分散推定値が算出されます。
このアプローチでは、σ2(実験間)は定数で、因子水準に依存しないと仮定します。この仮定が正しくない場合、モデルをxの分散に適合するために、応答の前処理 を使用して、反復のσ2を取得します。
を使用して、反復のσ2を取得します。
モデルに共変量がある場合、反復の分散で明らかにする必要があります。適合分散では説明できません。