このトピックの内容
計画行列
計画行列には、指定したモデルの適合に回帰を使用する一般線形モデル(GLM)に使用されるのと同じアプローチが使用されます。Minitabでは、まず因子と指定したモデルから計画行列が作成されます。この行列のXと呼ばれる列はモデルに含まれる項を表しています。
- 定数
- 共変量
- ブロック
- 因子
- 交互作用
- 定数
- 共変量
- 連続因子
ブロックの場合、列の数はブロックの数より1つ少なくなります。
2水準計画のカテゴリ因子と交互作用
2水準計画では計画因子の項は1列になります。交互作用項も1列になります。
一般実施要因計画のカテゴリ因子
| 水準A | A1 | A2 | A3 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | -1 | -1 | -1 |
一般実施要因計画の交互作用
交互作用項の列を計算するには、交互作用項にある因子の対応する列の積を求めます。たとえば、因子Aに6つの水準があり、Cに3つの水準があり、Dに4つの水準があるとします。項A * C * Dの列は5 × 2 × 3 = 30となります。水準を取得するには、Aの列に、C、Dの各列を掛けます。
分割実験計画のプロット全体の列
注
Minitabでは二値応答で分割実験計画は分析されません。
分割実験計画の場合、Minitabでは2つのバージョンの計画行列が使用されます。1つ目のバージョンは2水準実施要因計画で使用される行列と同じものです。もう一方の行列にはプロット全体を表す列のブロックが含まれます。例として、プロット全体の誤差項の計算には2つ目のバージョンの計画行列が使用されます。プロット全体の列は変更が難しい因子の列および変更が難しい因子のみを含む交互作用の列に続きます。
効果
各因子の推定効果です。効果は2水準モデルに対してのみ計算され、一般要因モデルに対しては計算されません。因子の効果の計算式は以下になります。
効果 = 係数 * 2
係数(Coef)
回帰式における回帰係数の母集団の推定値です。各因子において、k - 1の係数が計算され、kは因子に含まれる水準の数を表しています。2因子、2水準、完全実施モデルにおいて、因子と交互作用の係数を求める計算式は以下です。
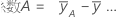
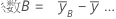

この2因子、2水準、完全実施モデルの係数の標準誤差は、以下です。

因子を2つより多く持つモデル、あるいは水準を2つより多く持つ因子に関する詳細は、Montgomeryの1を参照してください。
表記
| 用語 | 説明 |
|---|---|
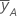 | 因子Aの高水準でのyの平均 |
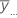 | すべての観測値の全体平均 |
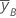 | 因子Bの高水準でのyの平均 |
 | 因子AおよびBの高水準でのyの平均 |
| 誤差の平均平方(MSE) | 誤差の平均平方 |
| n | 推定項の-1と1の数(共分散行列内) |
ボックスーコックス変換
ボックスーコックス変換では、以下に示す通り、二乗値の残差合計を最小化するλ値が選択されます。出力される変換は、λ ≠ 0の場合にYλ、およびλ = 0の場合にln(Y)です。λ < 0の場合に、変換済み応答に−1を掛けて、変換されていない応答の順序を維持します。
−2~2の範囲で最適値が検索されます。値がこの区間外になった場合、適合性が低下することがあります。
以下は一般的な変換方法です(Y′はデータYの変換データ)。
| ラムダ(λ)値 | 変換 |
|---|---|
| λ = 2 | Y′ = Y 2 |
| λ = 0.5 | Y′ = |
| λ = 0 | Y′ = ln(Y ) |
| λ = −0.5 | |
| λ = −1 | Y′ = −1 / Y |
重み付き回帰
重み付き最小二乗回帰は、観測値の分散が不均一な場合に用いられる手法です。分散が一定でない場合、
- 観測値の分散が大きい場合は比較的小さい重みが与えられます
- 観測値の分散が小さい場合は比較的大きい重みが与えられます
通常の重みの選択は、応答の純誤差分散の逆数です。
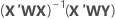
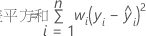
表記
| 用語 | 説明 |
|---|---|
| X | 計画行列 |
| X' | 計画行列の転置 |
| W | 対角線に重みを配置したn×n行列 |
| Y | 応答値のベクトル |
| n | 観測値数 |
| wi | i番目の観測値の重み値 |
| yi | i番目の観測値の応答値 |
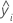 | i番目の観測値の適合値 |