適合値
適合する値は、適合値または とも呼ばれます。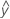 .適合値は、予測変数の値の平均応答の点推定です。予測変数の値は、X-値とも呼ばれます。
.適合値は、予測変数の値の平均応答の点推定です。予測変数の値は、X-値とも呼ばれます。
解釈
適合値は、データセットに含まれる観測値ごとの特定のx値をモデル式に入力することによって計算されます。
たとえば、式がy = 5 + 10xの場合に、X値が2ならば、適合値は25(25 = 5 + 10(2))となります。
観測された値と非常に異なる適合値を含む観測値は、異常な観測値である可能性があります。異常な予測値を持つ観測値は、影響力がある可能性があります。Minitabが、データに異常または影響力がある値が含まれていると判断した場合は、これらの観測値が特定された、異常な観測値の適合値と診断の表が出力されます。ラベルが付けられた異常な観測値は、提示された回帰式にしっかりと従っていません。ただし、いくつかの異常な観測値があることは予測されています。たとえば、大きな標準化残差の基準に基づくと、観測値の約5%は大きな標準化残差を持つとしてフラグが付けられることが予測されます。異常な値に関する詳細は、異常な観測値を参照してください。
適合値の標準誤差(SE Fit)
適合値の標準誤差(SE Fit)は、特定の変数設定について推定される平均応答の変動を推定します。平均応答の信頼区間の計算には、適合値の標準誤差が使用されます。標準誤差は常に正数です。この解析では、 統計 メニューのモデルと 予測分析モジュールの 線形回帰 モデルと 2値ロジスティック回帰 モデルの標準誤差が計算されます。
解釈
適合値の標準誤差は、平均応答の推定値の精度を測定するために使用します。標準誤差が小さいほど、予測される平均応答の精度は高くなります。たとえば、分析者が配達時間を予測するモデルを開発するとします。変数設定のひとつのセットに、モデルは3.80日の平均配達時間を予測します。これらの設定の適合値の標準誤差は0.08日です。変数設定の2つめのセットに、モデルは適合値の標準誤差の0.02日で同じ平均配達時間を生成します。分析者は、変数設定の2つめのセットの平均配達時間が3.80日近くであるということに、より自信を持つことができます。
あてはめ値を使用すると、近似の標準誤差を使用して、平均応答の信頼区間を作成できます。たとえば、自由度の数に応じて、95% 信頼区間は、予測平均の上下に約 2 つの標準誤差を拡張します。配達時間の場合、標準誤差が 0.08 の場合の予測平均 3.80 日の 95% 信頼区間は (3.64, 3.96) 日です。これは、95%の信頼度で、母集団の平均がこの範囲に含まれることを意味します。標準誤差が 0.02 の場合、95% 信頼区間は (3.76, 3.84) 日です。変数設定の 2 番目のセットの信頼区間は、標準誤差が小さいため、より狭くなります。
適合値の信頼区間(95%の信頼区間)
これらの信頼区間は、モデルに含まれる因子や予測変数の観測値を持つ、母集団の平均応答を含む可能性が高い値の幅です。
データのサンプルはランダムであるため、2つの母集団サンプルの信頼区間が同一である可能性は低くなります。しかし、サンプルを何度も繰り返して測定すると、得られた信頼区間の特定の割合に未知の母集団パラメータが含まれることになります。このようなパラメータを含む信頼区間の割合(%)を区間の信頼水準と言います。
- 点推定
- 点推定は、サンプルデータから算出されるパラメータの推定値です。信頼区間は、この値を中心にして得られます。
- 誤差幅
- 誤差幅は、信頼区間の幅を定義し、サンプル、サンプルサイズ、信頼水準において観測された変動性によって決定します。信頼区間の上限を計算するには、誤差幅を点推定に加算します。信頼区間の下限を計算するには、点推定から誤差幅を減算します。
解釈
信頼区間を使用して、変数の観測値に関する適合値の推定値を評価します。
たとえば、信頼水準が95%の場合、モデルに含まれる因子や予測変数における特定の値の母平均が信頼区間に含まれていることが95%信頼できます。信頼区間により、結果の実質的な有意性を評価しやすくなります。状況に応じた専門知識を利用して、信頼区間に実質的に有意な値が含まれているかどうかを判断します。信頼区間が広い場合、将来価値の平均値に対する信頼性が低くなります。信頼区間が広すぎて役に立たない場合、サンプルのサイズを増加させることを検討します。
Resid
残差(ei)とは、観測値(y)とそれに対応する適合値(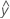 )モデルによって予測される値です。
)モデルによって予測される値です。
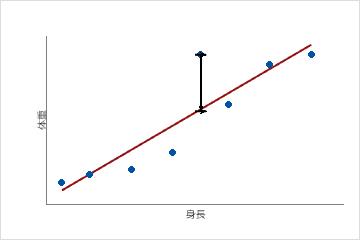
この散布図は成人男性のサンプルの身長対体重を表示しています。適合回帰線は身長と体重の関係を表しています。身長が6フィートであれば、体重の適合値は190ポンドです。実際の体重が200ポンドの場合は、残差は10となります。
解釈
残差をプロットし、モデルが適切であり、回帰仮定が満たされているかどうかを確認できます。残差を調べることにより、データに対するモデルの適合度に関して有用な情報を得ることができます。一般的に、残差はランダムに分布し、明確なパターンや異常値がありません。Minitabが、データに異常な観測値が含まれていると判断した場合は、これらの観測値が特定された、異常な観測値の適合値と診断の表が出力されます。ラベルが付けられた異常な観測値は、提示された回帰式にしっかりと従っていません。ただし、いくつかの異常な観測値があることは予測されていることです。たとえば、大きな残差の基準に基づくと、観測値の約5%は大きな残差を持つとしてフラグが付けられることが予測されます。異常な値に関する詳細は、異常な観測値を参照してください。
標準化残差
標準化残差は、残差(ei)をその標準偏差の推定値で割ったものです。
解釈
標準化残差を使用すると、外れ値を検出しやすくなります。2より大きく、-2より小さい標準化残差は、通常は大きなものであると見なされます。異常な観測値の適合値と診断の表では、これらの観測値が「R」で示されます。ラベルが付けられた観測値は、提示された回帰式にしっかりと従っていません。ただし、いくつかの異常な観測値があることは予測されています。たとえば、大きな標準化残差の基準に基づくと、観測値の約5%は大きな標準化残差を持つとしてフラグが付けられることが予測されます。詳細は、異常な観測値を参照してください。
標準化残差が役に立つのは、生の残差が外れ値を識別するものとして許容されない場合があるためです。生の残差の分散は、それに関連付けられたx値によって異なることがあります。この残差の不一致では、生の残差の大きさを評価するのが難しくなります。残差を標準化することで、異なる分散が共通の尺度に変換され、この問題は解消されます。
削除した残差
各スチューデント化削除残差は、データセットからの各観測値の系統的な削除、回帰式の推定、削除した観測値をモデルがどの程度良好に予測するかの判断に使われるのと同じ計算式によって求められます。各スチューデント化削除残差は、観測値の削除した残差をその標準偏差の推定値で割ることでも標準化されます。観測値を除外したのは、観測値がない状態でのモデルの動作を見るためです。観測値に大きいスチューデント化削除残差がある(絶対値が2より大きい)場合は、データ内の外れ値の可能性があります。
解釈
スチューデント化削除残差を使用して、外れ値を検出します。観測値が含まれない状態のモデルの適合工程で、モデルがどの程度良好に応答を予測するかを判断するために、各観測値は削除されています。2よりも大きい、または-2より小さいスチューデント化削除残差は、通常は大きなものであると見なされます。ラベルがつけられた観測値は、提示された回帰式にしっかりとは従っていません。ただし、いくつかの異常な観測値があることは予測されています。たとえば、大きな残差の基準に基づくと、観測値の約5%は大きな残差を持つとしてフラグが付けられることが予測されます。分析で異常な観測値が多数示される場合は、そのモデルは十分に予測変数と応答変数の関係を説明しきれていない可能性があります。詳細は異常な観測値を参照してください。
外れ値の予想には、生の残差よりも標準化残差と削除した残差の方が役立つかもしれません。これは、予測変数や因子の様々な値に起因する、生の残差の分散の潜在的な差に応じて、これらの残差が調整されるためです。
Hi(てこ比)
てこ比は、観察値のx値からデータセット内のすべての観察値のx値の平均までの距離を測定します。
解釈
てこ比値は0から1の間の値で、Minitabの異常な観測値の適合値と診断の表では、観測値のてこ比値が3p/nまたは0.99のいずれか小さい方を超えていることがXという文字によって示されます。3p/nでは、pはモデル内の係数の数で、nは観測値の数を表します。Minitabで「X」とラベル付けされる観測値は、影響力がある可能性があります。
影響力のある観測値は、モデルに対し不均衡な影響を与えるので、誤解を招く結果が生じる可能性があります。たとえば、影響力のある点を含める、または除外することにより、係数が統計的に有意かどうかが変わることがあります。影響力のある観測値は、てこ比点、外れ値またはその両方である可能性があります。
影響力のある観測値を確認する場合、観測値がデータ入力エラーまたは測定エラーでないかどうかを調べます。観測値はデータ入力エラーでも測定エラーでもない場合、観測値の影響度を判断します。まず、観測値のあるモデルとないモデルを適合します。その後、係数、p値、R2やその他のモデルの情報を比較します。影響力のある観測値を除外したときにモデルが大きく変化する場合は、モデルをさらに調べて、モデルの指定に誤りがあるかどうかを判断します。問題を解決するには、さらに多くのデータを集めることが必要な場合もあります。
クックの距離(D)
クックの距離(D)は、一般線形モデルにおける係数のセットに対して観測値が持つ影響力を測る測度です。クックの距離は、観測値の影響力を判定するために、各観測値のてこ比値と標準化残差が考慮されます。
解釈
D値が大きい観測値は、影響力がある可能性があります。D値が大きい場合の一般的な基準は、D値がF分布の中央値であるF(0.5, p, n-p)よりも大きいときです。ここで、pはモデル項の数(定数も含む)で、nは観測値の数です。D値を調べるもう1つの方法は、個別値プロットなどのグラフを使用して値を比較することです。D値が他に比べて大きい観測値は、影響力がある可能性があります。
影響力のある観測値は、モデルに対し不均衡な影響を与えるので、誤解を招く結果が生じる可能性があります。たとえば、影響力のある点を含める、または除外することにより、係数が統計的に有意かどうかが変わることがあります。影響力のある観測値は、てこ比点、外れ値またはその両方である可能性があります。
影響力のある観測値を確認する場合、観測値がデータ入力エラーまたは測定エラーでないかどうかを調べます。観測値がデータ入力エラーでも測定エラーでもない場合、観測値の影響力を判断します。まず、観測値のあるモデルとないモデルを適合します。その後、係数、p値、R2やその他のモデルの情報を比較します。影響力のある観測値を除外したときにモデルが大きく変化する場合は、モデルをさらに調べて、モデルの指定が間違っているかどうかを判断します。問題を解決するには、さらに多くのデータを集めることが必要な場合もあります。
DFITS
DFITSは、一般線形モデルにおける適合値に対して各観測値が持つ影響力を測る測度です。DFITSは、各観測値をデータセットから取り除きモデルを再度適合させたときに適合値が変化するおおよその標準偏差を表します。
解釈
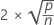
| 用語 | 説明 |
|---|---|
| p | モデルの項の数 |
| n | 観測値数 |
影響力のある観測値を確認する場合、観測値がデータ入力エラーまたは測定エラーでないかどうかを調べます。観測値がデータ入力エラーでも測定エラーでもない場合は、観測値の影響力を判断します。まず、観測値があるモデルとないモデルを適合します。その後、係数、p値、R2やその他のモデルの情報を比較します。影響力のある観測値を除外したときにモデルが大きく変化する場合は、モデルの指定に間違いがないかどうかをさらに調べます。問題を解決するには、さらに多くのデータを集めることが必要な場合もあります。