帰無仮説と対立仮説
等分散の検定は、2つ以上の母集団標準偏差に関する2つの相互排他的ステートメントを評定する仮説検定手法です。2つのステートメントは帰無仮説と対立仮説と呼ばれます。仮説検定手法では、サンプルデータを用いて帰無仮説を棄却するかどうかを判断します。
- 帰無仮説(H0)
- 帰無仮説では母集団標準偏差がすべて等しくなります。
- 対立仮説(HA)
- 対立仮説ではすべての母集団標準偏差は等しくありません。
解釈
帰無仮説を棄却するかどうかを判断するには、p値を有意水準と比較します。
N
サンプルサイズ(N)は、各グループに含まれる観測値の合計数です。
解釈
サンプルサイズは信頼区間と検出力に影響します。
通常、サンプルが大きいと信頼区間は狭くなり、差の検出力も高くなります。
標準偏差
標準偏差とは、散布度、つまり平均からのデータの広がり方を表す最も一般的な測度です。多くの場合、母集団の標準偏差を表すには記号σ(シグマ)が使用されます。サンプルの標準偏差を表すには記号sが使用されます。
解釈
標準偏差では、変数と同じ単位が使用されます。標準偏差の値が高いほど、データの広がりが大きいことを示します。データが正規分布に従っていれば、値のおよそ68%が平均の1つの標準偏差の範囲内にあり、値の95%が2つの標準偏差の範囲内にあり、値の99.7%が3つの標準偏差の範囲内にあります。
ボンフェローニの信頼区間
ボンフェローニの信頼区間を使用して、カテゴリ変数に基づく各母集団の標準偏差を推定します。各信頼区間は、対応する母集団の標準偏差が含まれる可能性が高い値の範囲です。Minitabではボンフェローニの信頼区間を調整して同時信頼水準を保ちます。
同時信頼水準を制御することは、多重信頼区間を評価する場合に特に重要です。同時信頼水準を制御しない場合、少なくとも1つの信頼区間に真の標準偏差が含まれない確率は、信頼区間の数に応じて増加します。
詳細については、「多重比較における個別および同時信頼水準の理解」と「ボンフェローニの方法とは」を参照してください。
注
このボンフェローニ信頼区間からは、グループペア間の差が統計的に有意であるかどうかは判断できません。要約プロットのp値と多重比較信頼区間から、差の統計的な有意性を判断してください。
解釈
方法
| 帰無仮説 | すべての分散が等しい |
|---|---|
| 対立仮説 | 少なくとも1つの分散が異なっている |
| 有意水準 | α = 0.05 |
標準偏差に対する95%のBonferroni信頼区間
| 肥料 | N | 標準偏差 | 信頼区間 |
|---|---|---|---|
| GrowFast | 50 | 4.28743 | (3.43659, 5.61790) |
| なし | 50 | 5.09137 | (4.24793, 6.40914) |
| SuperPlant | 49 | 5.49969 | (4.48577, 7.08914) |
これらの結果では、95%のボンフェローニ信頼区間は、信頼区間のセット全体に全グループの真の母集団標準偏差が含まれることを95%信頼できることを示しています。また、個別信頼水準は、1つの個別信頼区間がその特定のグループの母集団標準偏差を含むことをどの程度信頼できるかを示しています。たとえば、急成長の母集団の標準偏差が信頼水準(3.43659, 5.61790)の間に含まれるということに対する信頼度は98.3333%です。
個別信頼水準
個別信頼水準とは、分析が2回以上繰り返された場合に、1つの信頼区間にその特定のグループの真の標準偏差が含まれる回数の割合のことを言います。
信頼区間数を増やすと、少なくとも1つの信頼区間に真の標準偏差が含まれない確率は増加します。同時信頼水準は、信頼区間のセット全体に全グループの真の母集団標準偏差が含まれるということをどの程度信頼できるかを表しています。
解釈
方法
| 帰無仮説 | すべての分散が等しい |
|---|---|
| 対立仮説 | 少なくとも1つの分散が異なっている |
| 有意水準 | α = 0.05 |
標準偏差に対する95%のBonferroni信頼区間
| 肥料 | N | 標準偏差 | 信頼区間 |
|---|---|---|---|
| GrowFast | 50 | 4.28743 | (3.43659, 5.61790) |
| なし | 50 | 5.09137 | (4.24793, 6.40914) |
| SuperPlant | 49 | 5.49969 | (4.48577, 7.08914) |
各信頼区間にその特定のグループの母集団の標準偏差が含まれるということを98.3333%信頼できます。たとえば、急成長の母集団の標準偏差が信頼水準(3.43659, 5.61790)の間に含まれるということに対する信頼度は98.3333%です。しかし、そのセットには3つの信頼区間が含まれるため、すべての区間に真の値が含まれるということは95%しか信頼できません。
テスト
Minitabによって表示される等分散の検定のタイプはオプションサブダイアログボックスで正規分布に基づく検定を使用するを選択したかどうかと、データに含まれるグループの数で異なります。
多重比較、ルビーンの方法
正規分布に基づく検定を使用するを選択しなかった場合、多重比較の方法とルビーンの方法の結果の両方が表示されます。ほとんどの連続分布において、この2つの方法では有意水準(αまたはアルファとも呼ばれる)に近い第1種過誤率の原因となります。通常、多重比較の方法の方がより検出力が高いです。多重比較の方法でのp値が有意である場合、要約プロットを使って他と異なる標準偏差を持つ母集団を特定することができます。
- 各サンプルの観測値が20未満です。
- 1つ以上の母集団の分布は、偏りが大きいか裾が重くなっています。正規分布に比べ、裾が重い分布では下端と上端にデータが集まっています。
多重比較検定におけるp値が選択した有意水準より小さい場合、いくつかの標準偏差間の差は統計的に有意です。多重比較区間を使用して、どの標準偏差が有意に異なっているかを特定します。2つの区間が重ならない場合、対応する標準偏差(と分散)は統計的に有意です。
偏りが大きい分布や裾の重い分布からのデータがある場合、多重比較の方法における第1種過誤率はαよりも高くなる可能性があります。この状態でルビーンの方法が算出するp値の方が多重比較のそれよりも小さい場合、ルビーンの方法から結論を導いてください。
F検定、バートレットの検定
正規分布に基づく検定を使用するを選択し、2つのグループがある場合、MinitabではF検定が実行されます。グループが3つ以上の場合は、バートレットの検定が実行されます。
F検定とバートレットの検定は、正規に分布したデータでのみ正確になります。正規性からのいかなる逸脱も不正確な検定結果の原因となる可能性があります。しかし、データが正規分布に従っている場合、F検定とバートレットの検定は、多重比較やルビーンの方法に比べて検出力は高いです。
検定におけるp値が有意水準より小さい場合、いくつかの標準偏差間の差は統計的に有意です。
検定統計量
注
多重比較検定では検定統計量は使用されません。
解釈
Minitabで検定統計量を使用して計算されるp値に基づいて、標準偏差間の差の統計的有意性を決定します。p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
十分に大きな検定統計量は、いくつかの標準偏差間の差が統計的に有意であることを示します。
その検定統計量を使用して、帰無仮説を棄却するかどうかを判断できます。とはいえ、解釈するのが容易なため、p値のほうが頻繁に使用されます。
p値
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
解釈
p値を使用し、標準偏差間の差のいずれかが統計的に有意かどうかを判断します。分散の同等性を評価する1つまたは2つの検定の結果が表示されます。p値が2つあり、それらが一致しない場合は、「検定」を参照してください。
標準偏差間の差のいずれかが統計的に有意かどうかを判断するために、p値を有意水準と比較し、帰無仮説を評価します。帰無仮説は、グループの平均がすべて等しいとします。通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際には差が存在しない場合に、差が存在すると結論付けてしまうリスクが5%であるということを示します。
- p値 > αの場合、標準偏差間の差は統計的に有意ではありません。
- p値 ≤ αの場合、いくつかの標準偏差間の差は統計的に有意です。
要約プロット
要約プロットには、等分散検定のp値と信頼区間が表示されます。Minitabによって表示される検定のタイプや区間は、オプションダイアログボックスで正規分布に基づく検定を使用するを選択したかどうかと、データに含まれるグループの数で異なります。
正規分布に基づく検定を使用するを選択しなかった場合、要約プロットには多重比較とルビーンの方法の両方のp値が表示されます。さらに多重比較区間も表示されます。データのプロパティに応じてどちらの方法を使うかを選択してください。
正規分布に基づく検定を使用するを選択して2つのグループがある場合、MinitabではF検定が実行されます。グループが3つ以上の場合は、バートレットの検定が実行されます。どちらの方法でも、ボンフェローニの信頼区間もプロットに表示されます。
P値
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
p値を使用し、標準偏差間の差のいずれかが統計的に有意かどうかを判断します。分散の同等性を評価する1つまたは2つの検定の結果が表示されます。p値が2つあり、それらが一致しない場合は、「検定」セクションでどの検定が適切かを確認してください。
標準偏差間の差のいずれかが統計的に有意かどうかを判断するために、p値を有意水準と比較し、帰無仮説を評価します。帰無仮説ではグループの標準偏差がすべて等しくなります。通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際には差が存在しない場合に、差が存在すると結論付けてしまうリスクが5%であるということを示します。
- p値 > αの場合、標準偏差間の差は統計的に有意ではありません。
- p値 ≤ αの場合、いくつかの標準偏差間の差は統計的に有意です。
多重比較区間
正規分布に基づく検定を使用するが選択されていない場合、要約プロットには多重比較区間が表示されます。
多重比較のp値を使うのが確実な場合は、多重比較信頼区間を使用して、統計的に有意な差を持つ特定のグループペアを特定することができます。2つの区間が重ならない場合、対応する標準偏差間の差は統計的に有意です。
データのプロパティから判断してルビーンの方法を使う必要がある場合は、要約プロットの信頼区間を評価しないでください。
ボンフェローニの信頼区間
正規分布に基づく検定を使用するを選択した場合、要約プロットにはボンフェローニの信頼区間が表示されます。
Bonferroniの信頼区間を使用して、カテゴリ変数の各母集団の標準偏差を推定します。各信頼区間は、対応する母集団の標準偏差が含まれる可能性が高い値の範囲です。MinitabではBonferroniの信頼区間を調整して同時信頼水準を制御します。
同時信頼水準を制御することは、多重信頼区間を評価する場合に特に重要です。同時信頼水準を制御しない場合、少なくとも1つの信頼区間に真の標準偏差が含まれない確率は、信頼区間の数に応じて増加します。
詳細については、「多重比較における個別および同時信頼水準の理解」と、「ボンフェローニの方法とは」を参照してください。
注
このボンフェローニ信頼区間からは、グループペア間の差が統計的に有意であるかどうかは判断できません。要約プロットのp値と多重比較信頼区間から、差の統計的な有意性を判断してください。
解釈
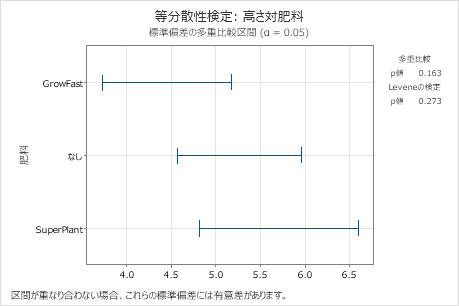
この要約プロットでは、多重比較検定のp値は有意水準0.05よりも高くなっています。グループ間の差はどれも統計的に有意ではなく、すべての多重比較区間は重なっています。
個別値プロット
個別値プロットは各サンプルに対して個別の値を表示します。個別値プロットではサンプル同士の比較が容易に行えます。各円は1つの観測値を表しています。個別値プロットは、サンプルサイズが小さい場合には特に有益です。
解釈
個別値プロットを使用して、データの広がりを調べ、潜在的な外れ値を識別します。個別値プロットは、サンプルサイズが50未満の場合に最適です。
- 歪んだデータ
-
データの広がりを検討し、データが歪んでいるかどうかを判断します。データが歪んでいる場合、ほとんどのデータがグラフの上下に位置していることになります。歪んだデータはデータが正規に分布されていない可能性を示唆しています。歪みは、個別値プロット、ヒストグラム、または箱ひげ図によって最も簡単に検出する事ができます。
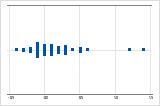
右方向の歪み
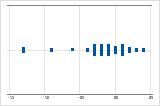
左方向の歪み
右方向に歪んだデータのある個別値プロットは、待ち時間を示します。待ち時間のほとんどは比較的短く、ごく少数の待ち時間だけが長くなります。左方向に歪んだデータのある個別値プロットは、故障寿命を示します。少数の項目が直ちに故障し、もっと多くの項目が後で故障します。
- 外れ値
-
外れ値は、他の大部分のデータから離れているデータ値のことで、分析の結果に大きな影響を及ぼします。多くの場合、外れ値は個別値プロットで容易に識別できます。
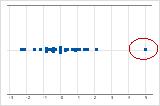
個別値プロットでは、異常に低いか、または高いデータ値によって、潜在的な外れ値が示されます。
外れ値がある場合は、その原因を特定してください。データ入力誤差や測定誤差はすべて修正します。異常な1回だけの事象(特殊原因)を示すデータ値の除外を検討してください。その後分析を繰り返します。
箱ひげ図
箱ひげ図では各サンプル分布のグラフ要約を表示します。箱ひげ図を使用すると、サンプル分布の形、中心傾向、変動性の比較が容易になります。
解釈
箱ひげ図を使用して、データの広がりを調べ、潜在的な外れ値を確認します。箱ひげ図は、サンプルサイズが20より大きい場合に最適です。
- 歪んだデータ
-
データの広がりを調べ、データが歪んでいるかどうかを判断します。データが歪んでいる場合、ほとんどのデータがグラフの上下に位置していることになります。歪んだデータはデータが正規に分布されていない可能性を示唆しています。歪みは、個別値プロット、ヒストグラム、または箱ひげ図によって最も簡単に検出する事ができます。

右方向の歪み

左方向の歪み
右方向に歪んだデータは、平均待ち時間を示します。待ち時間のほとんどは比較的短く、ごく少数の待ち時間だけが長くなります。左方向に歪んだデータは、故障率を示します。少数の項目が直ちに故障し、より多くの項目が後で故障します。
データが大きく歪んでいると、サンプルサイズが小さい場合(20未満)にp値の妥当性が影響を受けます。データが大きく歪んでいて、サンプルサイズが小さい場合はサンプルサイズを増やすことを検討します。
- 外れ値
-
外れ値は、他のデータから遠くに離れているデータ値のことで、分析の結果に大きな影響を及ぼします。多くの場合、外れ値は、箱ひげ図で容易に識別できます。
箱ひげ図では、アスタリスク(*)が外れ値を意味します。
外れ値がある場合は、その原因を特定してください。データ入力誤差や測定誤差はすべて修正します。異常な1回だけの事象(特殊原因)を示すデータ値を除外することを検討してください。それから、分析を繰り返します。