推定法
制約型最尤法(REML)または最尤法(ML)のいずれかを選択することができます。REMLによる分散成分推定はほぼ不偏で、MLによる推定は偏るため、通常は制約型最尤法(REML)を選択します。ただし、サンプルサイズが大きくなると偏りは小さくなります。
どちらのモデルにも同数のランダム項と同じ誤差の分散構造がある場合に、固定効果項の数が少ない枝分かれしたモデルが、対応する固定効果項の数が多い参照モデルと同程度に良好かどうかを検定する必要がある場合は、最尤法(ML)を使用します。具体的には、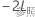 が完全モデルから得られる-2対数尤度で、
が完全モデルから得られる-2対数尤度で、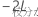 が小さいモデルから得られる-2対数尤度であるとします。
が小さいモデルから得られる-2対数尤度であるとします。
帰無仮説の下で、漸近的に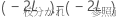 は、自由度が参照モデルと枝分かれモデルの固定効果項のパラメータ数の差に等しい、カイ二乗分布に従います。尤度比検定を使用して、固定効果項のサブセットを参照モデルから取り除くことができるかどうかを評価することができます。
は、自由度が参照モデルと枝分かれモデルの固定効果項のパラメータ数の差に等しい、カイ二乗分布に従います。尤度比検定を使用して、固定効果項のサブセットを参照モデルから取り除くことができるかどうかを評価することができます。
混合効果モデルにおける固定パラメータの尤度比検定に関する詳細は、『B. T. West, K.B. Welch, and A.T. Gałecki (2007). Linear Mixed Models: A Practical Guide Using Statistical Software, 第1版. Chapman and Hall/CRC (34–36頁)』を参照してください。
固定効果の検定方法
計算には、小さいサンプルサイズに起因する偏りを低減する調整が含まれるため、通常はKenward-Roger近似を使用します。Satterthwaite近似を使用することもできます。一般的に、サンプルサイズが大きいほど2つの手法の差は小さくなります。
重み
重みにすべての応答値の、重みの数値列を入力します。応答値に含まれるランダム誤差の分散が定数でない場合は、重みを使用します。そのかわり、各応答値において分散は、対応する重みが定数を乗じた値の逆数と等しくなります。
重みは0以上の数でなければなりません。重み列の行数と応答列の行数は同じでなければなりません。
全区間の信頼水準
出力内のすべての信頼区間の信頼水準を入力します。
通常、95%の信頼水準が適切です。95%の信頼水準は、対象のパラメータの母集団から100個のランダムサンプルを採取した場合、サンプルのうちおよそ95個の信頼区間に未知のパラメータの真の値が含まれることを示しています。与えられたデータセットにおいて、信頼水準の値を低くすると信頼区間が狭くなり、信頼水準を高くすると信頼区間が広くなります。
注
信頼区間を表示するには、結果サブダイアログボックスに移行し、結果の表示から拡張表を選択します。
信頼区間のタイプ
両側区間か、片側限界かを選択できます。信頼水準が同じ場合、区間よりも限界の方が点推定に近くなります。上限は、下限になる可能性のある値をもたらしません。下限は、上限になる可能性のある値をもたらしません。
- 両側
-
- 両側信頼区間を使用して、対象のパラメータの上限値と下限値になる可能性のある値を推定します。
- 下限
-
- 下側信頼境界値を使用して、対象のパラメータの下限値となる可能性のある値を推定します。
- 上限
-
- 上側信頼境界値を使用して、対象のパラメータの上限値となる可能性のある値を推定します。
平均
出力には、主効果の適合平均、二元交互作用、またはモデルに含まれる全項を表示することができます。あるいは、これらの項のサブセットの平均を表示したり、全く表示させないこともできます。
指定した項を選択した場合、項ボタンにはI = 項の平均値の計算を使い、項を特定します。リストから項を選択し、ボタンを押します。Iは項の平均が表示されることを示しています。目的の項がリストに表示されていない場合は、モデルに追加してください。