方法表のすべての統計量の定義と解釈について解説します。
方法表を使い、分析で正しい方法が選択されているかを確認します。
- 分散推定
-
REMLによる分散成分推定はほぼ不偏で、最尤法による推定は偏るため、通常は制約型最尤法(REML)を選択します。ただし、サンプルサイズが大きくなると偏りは小さくなります。
どちらのモデルにも同数のランダム項と同じ誤差の分散構造がある場合に、固定効果項の数が少ない枝分かれしたモデルが、対応する固定効果項の数が多い参照モデルと同程度に良好かどうかを検定する必要がある場合は、最尤法(ML)を使用します。具体的には、
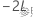 が完全モデルから得られる-2対数尤度で、
が完全モデルから得られる-2対数尤度で、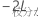 が小さいモデルから得られる-2対数尤度であるとします。
が小さいモデルから得られる-2対数尤度であるとします。帰無仮説の下で、漸近的に
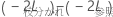 は、自由度が参照モデルと枝分かれモデルの固定効果項のパラメータ数の差に等しい、カイ二乗分布に従います。尤度比検定を使用して、固定効果項のサブセットを参照モデルから取り除くことができるかどうかを評価することができます。
は、自由度が参照モデルと枝分かれモデルの固定効果項のパラメータ数の差に等しい、カイ二乗分布に従います。尤度比検定を使用して、固定効果項のサブセットを参照モデルから取り除くことができるかどうかを評価することができます。混合効果モデルでの固定パラメータの尤度比検定に関する詳細は、West、WelchおよびGaleck(1)を参照してください。
- 固定効果の自由度
-
計算には小さなサンプルの偏りを低減する、応答値の共分散行列の調整済み推定が使用されるため、通常はKenward-Roger近似を使用します。Satterthwaite近似を使用することもできます。一般的に、サンプルサイズが大きいほど2つの手法の差は小さくなります。
1 B. T. West, K.B. Welch, and A.T. Gałecki (2007). Linear Mixed Models: A Practical Guide Using Statistical Software, First Edition. Chapman and Hall/CRC (34–36)