このトピックの内容
ステップ1:すべての応答から平均の等性を検定する
- p値 ≤ α:平均値の間の差は統計的に有意です
- p値が有意水準以下の場合は、平均値間の差は統計的に有意であると結論付けることができます。
- p値 > α:平均値の間の差は統計的に有意ではありません
- p値が有意水準より大きい場合は、平均値間の差は統計的に有意であると結論付けることができません。項を持たないモデルを再適合したいと考えるかもしれません。
- 主効果が有意である場合、その因子の水準平均は、モデルでのすべての応答において相互に有意に異なります。
- 交互作用が有意である場合、各因子の効果はモデル内のすべての応答にわたって、他の因子の各水準に対して異なります。このため、より高次の有意な交互作用に含まれる項の個々の効果を分析しないようにしてください。
方法に対する多変量分散分析の検定
| 自由度 | |||||
|---|---|---|---|---|---|
| 基準 | 検定統計量 | F値 | NUM | Denom (分母) | p値 |
| Wilksの | 0.63099 | 16.082 | 2 | 55 | 0.000 |
| Lawley-Hotelling | 0.58482 | 16.082 | 2 | 55 | 0.000 |
| Pillaiの | 0.36901 | 16.082 | 2 | 55 | 0.000 |
| Royの | 0.58482 | ||||
工場に対する多変量分散分析の検定
| 自由度 | |||||
|---|---|---|---|---|---|
| 基準 | 検定統計量 | F値 | NUM | Denom (分母) | p値 |
| Wilksの | 0.89178 | 1.621 | 4 | 110 | 0.174 |
| Lawley-Hotelling | 0.11972 | 1.616 | 4 | 108 | 0.175 |
| Pillaiの | 0.10967 | 1.625 | 4 | 112 | 0.173 |
| Royの | 0.10400 | ||||
方法*工場に対する多変量分散分析の検定
| 自由度 | |||||
|---|---|---|---|---|---|
| 基準 | 検定統計量 | F値 | NUM | Denom (分母) | p値 |
| Wilksの | 0.85826 | 2.184 | 4 | 110 | 0.075 |
| Lawley-Hotelling | 0.16439 | 2.219 | 4 | 108 | 0.072 |
| Pillaiの | 0.14239 | 2.146 | 4 | 112 | 0.080 |
| Royの | 0.15966 | ||||
主要な結果: P
生産法のp値は有意水準0.10のときに統計的に有意です。製造工場のp値は、どんな検定でも、有意水準0.10のときに有意にはなりません。生産法と製造工場の交互作用のp値は、有意水準0.10のときに統計的に有意です。交互作用は統計的に有意であるので、生産法の効果は製造工場によって変動します。
ステップ2:各因子に対して、どちらの応答平均の差が大きいかを特定する
固有分析を使用すると、異なるモデル項の水準間で応答平均がどのように異なるかを評価できます。高い固有値に対応する固有ベクトルに重点を置いてください。固有分析を表示するには、に移行し、 固有値分析で結果の表示を選択します。
方法に対するEIGEN (固有値) 分析
| 固有値 | 0.5848 | 0.00000 |
|---|---|---|
| 比率 | 1.0000 | 0.00000 |
| 累積 | 1.0000 | 1.00000 |
| 固有ベクトル | 1 | 2 |
|---|---|---|
| 有用性評価 | 0.144062 | -0.07870 |
| 品質評価 | -0.003968 | 0.13976 |
主要な結果:固有値と固有ベクトル
これらの結果では、方法の第1固有値(0.5848)は第2固有値(0.00000)よりも大きくなっています。よって、第1固有ベクトルの方が重要であるということが分かります。方法の第1固有ベクトルは、0.144062、-0.003968となっています。このベクトル内の最も高い絶対値はユーザビリティ評価のものです。これは、ユーザビリティの平均値は方法の因子水準間においてその差が最大であるということを示しています。これは、平均表を評価する際の有益な情報になります。
ステップ3:グループ平均間の差を評価する
平均表を使い、データ内の因子水準間の統計的に有意な差を把握します。各グループの平均値は、各母平均の推定値です。項のグループ平均値間の統計的に有意な差を探します。
主効果として、表は各因子内のグループとその平均値が表示されます。交互作用効果としては、可能性のある全てのグループの組み合わせが表示されます。交互作用項が統計的に有意な場合は、主効果の解釈では必ず交互作用効果も考慮してください。
平均を表示させるには、から単変量分散分析を選択し、項に対応した最小二乗平均を表示に項を追加します。
応答の最小二乗平均
| 有用性評価 | 品質評価 | |||
|---|---|---|---|---|
| 平均 | 平均の標準誤差 | 平均 | 平均の標準誤差 | |
| 方法 | ||||
| 方法1 | 4.819 | 0.165 | 5.242 | 0.193 |
| 方法2 | 6.212 | 0.179 | 6.026 | 0.211 |
| 工場 | ||||
| 工場A | 5.708 | 0.192 | 5.833 | 0.226 |
| 工場B | 5.493 | 0.232 | 5.914 | 0.273 |
| 工場C | 5.345 | 0.206 | 5.155 | 0.242 |
| 方法*工場 | ||||
| 方法1 工場A | 4.667 | 0.272 | 5.417 | 0.319 |
| 方法1 工場B | 4.700 | 0.298 | 5.400 | 0.350 |
| 方法1 工場C | 5.091 | 0.284 | 4.909 | 0.334 |
| 方法2 工場A | 6.750 | 0.272 | 6.250 | 0.319 |
| 方法2 工場B | 6.286 | 0.356 | 6.429 | 0.418 |
| 方法2 工場C | 5.600 | 0.298 | 5.400 | 0.350 |
主要な結果:平均
これらの結果では、平均表は平均ユーザビリティと品質の評価が、方法、工場、方法*工場の交互作用でそれぞれどのように変わるかを示しています。方法と交互作用項は水準0.10のときに統計的に有意です。表は、方法1と方法2はそれぞれ平均ユーザビリティ評価の4.819と6.212に関連付けられていることを示しています。これらの平均間の差は、それに対応する品質評価の平均よりも大きくなっています。これにより、固有分析の解釈が裏付けられました。
しかし、方法*工場の交互作用項も統計的に有意なため、交互作用効果を考慮することなしに主効果を解釈しないでください。たとえば、交互作用項の表では、方法が1の場合、工場Cが最も高いユーザビリティ評価と最も低い品質評価に関連付けられてることを示しています。一方で、方法が2の場合は工場Aが最も高いユーザビリティ評価と最も高い品質評価の値と同等に近い評価に関連付けられています。
ステップ4:単変量の結果を評価して個別の応答を調べる
一般多変量分散分析を実行する場合、単変量統計量を計算して、個々の応答を調べることができます。単変量の結果はデータの関係性をより直観的に表してくれます。ただし、単変量の結果は多変量の結果とは異なる可能性があります。
単変量の結果を表示するには、に移行し、結果の表示で、単変量分散分析を選択します。
- p値 ≤ α:関連性は統計的に有意です
- p値が有意水準以下の場合は、応答変数と項の間に統計的に有意な関連性が存在すると結論付けることができます。
- p値 > α:その関連性は統計的に有意ではありません
- p値が有意水準より大きい場合は、応答変数と項の間に統計的に有意な関連性があると結論付けることはできません。項を持たないモデルを再適合したいと考えるかもしれません。
- カテゴリ因子が有意な場合は、すべての水準平均が等しいとは限らないと結論付けることができます。
- 交互作用項が有意な場合は、因子と応答の間の関係はその項の他の因子に依存します。こうしたケースでは、交互作用の影響を考慮せずに主要な影響を解釈すべきではありません。
- 共変量が統計的に有意な場合、その共変量の値の変化は平均応答値の変化と関連すると結論付けることができます。
- 多項式項が有意な場合は、データに曲面性が含まれると結論付けることができます。
有用性評価の分散分析、検定に調整平方和を使用
| 要因 | 自由度 | 逐次平方和 | 調整平方和 | 調整平均平方 | F値 | p値 |
|---|---|---|---|---|---|---|
| 方法 | 1 | 31.264 | 29.074 | 29.0738 | 32.72 | 0.000 |
| 工場 | 2 | 1.366 | 1.499 | 0.7495 | 0.84 | 0.436 |
| 方法*工場 | 2 | 7.099 | 7.099 | 3.5494 | 3.99 | 0.024 |
| 誤差 | 56 | 49.754 | 49.754 | 0.8885 | ||
| 合計 | 61 | 89.484 |
品質評価の分散分析、検定に調整平方和を使用
| 要因 | 自由度 | 逐次平方和 | 調整平方和 | 調整平均平方 | F値 | p値 |
|---|---|---|---|---|---|---|
| 方法 | 1 | 8.8587 | 9.2196 | 9.2196 | 7.53 | 0.008 |
| 工場 | 2 | 6.7632 | 7.0572 | 3.5286 | 2.88 | 0.064 |
| 方法*工場 | 2 | 0.7074 | 0.7074 | 0.3537 | 0.29 | 0.750 |
| 誤差 | 56 | 68.5900 | 68.5900 | 1.2248 | ||
| 合計 | 61 | 84.9194 |
主要な結果:P
これらの結果では、方法の主効果のp値と、方向*工場の交互作用効果は、ユーザビリティ評価のモデルの水準0.10において統計的に有意です。方法と工場両方の主効果は、品質評価のモデルにおいて統計的に有意です。この結果から、これらの変数の変化は応答変数の変化に関連付けられていると結論付けることができます。
ステップ5:モデルが分析の仮説を満たすかどうか判断する
残差プロットを使用して、モデルが適切か、分析の仮定が満たされているかどうかを判断しやすくします。仮定を満たさない場合、そのモデルはデータにあまり適合しない可能性があり、結果の解釈は慎重に行う必要があります。
一般多変量分散分析を実行した場合、モデルに含まれる全ての応答変数に対して残差プロットが表示されます。モデルが仮定を満たしていることを全ての応答変数に対する残差プロットが示しているかどうかを判断する必要があります。
残差プロットのパターンを処理する方法の詳細は一般多変量分散分析の残差プロットを参照し、ページ上部にある一覧の中から残差プロット名をクリックしてください。
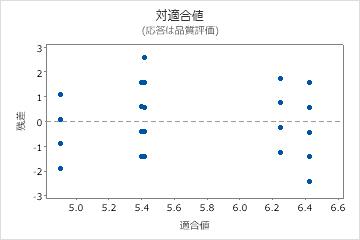
残差対適合値プロット
残差対適合値プロットを使用して、残差はランダムに分布し、均一な分散が存在するという仮定を検証します。点に特徴的なパターンがなく、0の両側にランダムにくるのが理想的です。
| パターン | パターンが示す意味 |
|---|---|
| 残差が適合値周辺に扇状または不均等に分散している | 不均一分散 |
| 曲線 | 高次の項の欠損 |
| ゼロから遠い点 | 外れ値 |
| ある点が他の点からX軸方向に遠く離れている | 影響力のある点 |
残差対順序プロット
トレンド
シフト
周期
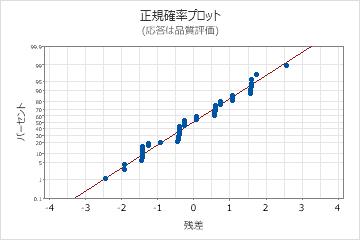
残差の正規確率プロット
残差の正規確率プロットを使用して、残差が正規分布に従うという仮定を検証します。残差の正規確率プロットは、ほぼ直線になります。
| パターン | パターンが示す意味 |
|---|---|
| 直線ではない | 非正規性 |
| 直線から離れた点 | 外れ値 |
| 変化する傾き | 未確認の変数 |