ステップ1:応答と項の関連が統計的に有意かどうかを判断する
- p値 ≤ α:関連性は統計的に有意です
- p値が有意水準以下の場合は、応答変数と項の間に統計的に有意な関連性が存在すると結論付けることができます。
- p値 > α:その関連性は統計的に有意ではありません
- p値が有意水準より大きい場合は、応答変数と項の間に統計的に有意な関連性があると結論付けることはできません。項を持たないモデルを再適合したいと考えるかもしれません。
- 固定因子が有意な場合は、すべての水準平均が等しいとは限らないと結論付けることができます。
- 変量因子が有意な場合は、その因子が応答の変動量に寄与していると結論できます。
- 交互作用項が有意な場合は、因子と応答の間の関係はその項の他の因子に依存します。こうしたケースでは、交互作用の影響を考慮せずに主要な影響を解釈すべきではありません。
- 共変量が統計的に有意な場合、その共変量の値の変化は平均応答値の変化と関連すると結論付けることができます。
- 多項式項が有意な場合は、データに曲面性が含まれると結論付けることができます。
係数
| 項 | 係数 | 係数の標準誤差 | t値 | p値 | VIF |
|---|---|---|---|---|---|
| 定数 | -4969 | 191 | -25.97 | 0.000 | |
| 温度 | 83.87 | 3.13 | 26.82 | 0.000 | 301.00 |
| ガラス種別 | |||||
| 1 | 1323 | 271 | 4.89 | 0.000 | 3604.00 |
| 2 | 1554 | 271 | 5.74 | 0.000 | 3604.00 |
| 温度*温度 | -0.2852 | 0.0125 | -22.83 | 0.000 | 301.00 |
| 温度*ガラス種別 | |||||
| 1 | -24.40 | 4.42 | -5.52 | 0.000 | 15451.33 |
| 2 | -27.87 | 4.42 | -6.30 | 0.000 | 15451.33 |
| 温度*温度*ガラス種別 | |||||
| 1 | 0.1124 | 0.0177 | 6.36 | 0.000 | 4354.00 |
| 2 | 0.1220 | 0.0177 | 6.91 | 0.000 | 4354.00 |
主要な結果:p値、係数
これらの結果で、ガラスの種類と温度に対する主効果は、有意水準0.05において統計的に有意です。この結果から、これらの変数の変化は応答変数の変化に関連付けられていると結論付けることができます。
実験で使用した3種類のガラスのうち、出力では2種類のガラスに対する係数が表示されています。デフォルトでは完全な多重共線性を避けるために1つの因子水準が削除されます。-1、0、+1のコード化スキームで分析されているため、主効果の係数は各水準毎の平均と全体平均の差を表します。たとえば、ガラス種類1は全体平均より1323単位強い光出力と関連付けられています。
このモデルにおいては温度が共変量となります。主効果の係数は、共変量の1単位分の増加に対する平均応答の変化を表し、モデル内の他の全ての項は固定されます。温度が1度上がる毎に、平均光出力は83.87単位ずつ増加します。
ガラスの種類と温度は共に統計的に有意な高次の項に含まれています。
ガラスの種類と温度に対する二元交互作用と三元交互作用の項は統計的に有意です。これらの交互作用は各変数と応答の関係は他の変数に依存することを示しています。たとえば、ガラスの種類が光出力に与える影響力は温度に依存します。
多項式項、温度*温度は、温度と光出力の関係における曲面性が統計的に有意であることを示しています。
交互作用効果や曲面性を考慮することなしに主効果を解釈しないでください。モデルにおける主効果、交互作用効果、および曲面性に関してより理解を深めるには、因子プロットと応答の最適化機能を参照してください。
ステップ2:データに対するモデルの適合度を判断する
データに対するモデルの適合度を判断するために、モデル要約表の適合度統計量を調査します。
- S
-
Sを使い、モデルがどの程度良好に応答を表示するか判断します。R2統計量のかわりにSを使い、定数を持たないモデルの適合を比較します。
Sは応答変数の単位で測定され、データ値と適合値の間の距離を表します。Sの値が小さければ小さいほど、モデルによる応答の記述が良好になります。ただし、Sの値が小さいだけでは、そのモデルが仮定を満たしているとは言い切れません。残差プロットを確認して仮定を検証する必要があります。
- R二乗
-
R2値が大きくなるほど、モデルのデータへの適合度は上がります。R2は常に0~100%の間の値になります。
R2はモデルに新しい予測変数を追加すると必ず大きくなります。たとえば、最適な5予測変数モデルのR2は必ず、最適な4予測変数モデルと少なくとも同じ大きさになります。したがって、R2値は同じ大きさのモデルの比較に最も便利です。
- R二乗(調整済み)
-
異なる数の予測変数を持つモデルを比較する場合は、調整済みR2を使用します。R2はモデルに予測変数を追加すると、それがモデルを改善しないとしても必ず大きくなります。調整済みR2値にはモデルに含まれる予測変数の数が組み入れられるため、正しいモデルの選択に役立ちます。
- R二乗(予測)
-
予測R2を使用して、モデルが新しい観測値に対する応答をどの程度良好に予測するかを判断します。予測R2値が大きいモデルの予測能力は優れています。
R2よりも大幅に低い予測R2は、モデルの過剰適合を示している可能性があります。過剰適合は、母集団には重要でない項を追加した場合に起こります。そのモデルはサンプルデータに即してしまい、母集団の予測に適さなくなる可能性があります。
予測R2は、モデル計算に含まれていない観測値によって計算されるため、モデルを比較する場合は調整済みR2より便利です。
- AICcとBIC
- ステップワイズ法の各ステップの詳細を表示するとき、または分析結果を拡大表示するとき、さらに2つの統計量が表示されます。これらの統計量は補正赤池情報量基準(AICc)およびベイズ情報量規準(BIC)です。異なるモデルを比較する際はこれらの統計量を使用します。どちらの統計量でも、小さい値が好ましいと考えられます。変量因子がデータに含まれている場合はこれらの統計量は表示されず、ステップワイズ法も実行されません。
-
サンプルサイズが小さい場合、応答と予測との間の関係の強さが正確に推定されません。たとえば、より正確なR2が必要な場合、サンプルサイズを大きくする必要があります(40以上が一般的です)。
-
適合度統計量は、データに対するモデルの適合度を測る1つの測度に過ぎません。モデルに望ましい値がある場合でも、残差プロットを確認してモデルが仮定を満たしているかを検証する必要があります。
モデル要約
| S | R二乗 | R二乗 (調整済み) | R二乗 (予測) |
|---|---|---|---|
| 19.1185 | 99.73% | 99.61% | 99.39% |
主要な結果:S、R二乗、R二乗(調整済み)、R二乗(予測)
この結果でモデルは、フェースプレートガラスのサンプルにおける99.73%の光出力の変動を説明しています。これらのデータで、R2値はモデルが良好にデータに適合していることを示しています。新しいモデルが別の予測変数と適合する場合は、調整済みR2値と予測R2値を使ってモデルの適合度を比較してください。
ステップ3:モデルが分析の仮説を満たすかどうか判断する
残差プロットを使用して、モデルが適切か、分析の仮定が満たされているかどうかを判断しやすくします。仮定を満たさない場合、そのモデルはデータにあまり適合しない可能性があり、結果の解釈は慎重に行う必要があります。
残差プロットのパターンを処理する方法の詳細は一般線形モデルの適合の残差プロットを参照し、ページ上部にある一覧の中から残差プロット名をクリックしてください。
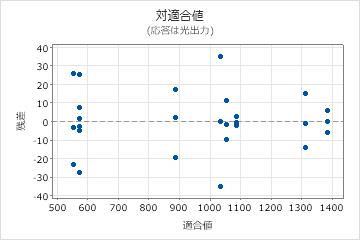
残差対適合値プロット
残差対適合値プロットを使用して、残差はランダムに分布し、均一な分散が存在するという仮定を検証します。点に特徴的なパターンがなく、0の両側にランダムにくるのが理想的です。
| パターン | パターンが示す意味 |
|---|---|
| 残差が適合値周辺に扇状または不均等に分散している | 不均一分散 |
| 曲線 | 高次の項の欠損 |
| ゼロから遠い点 | 外れ値 |
| ある点が他の点からX軸方向に遠く離れている | 影響力のある点 |
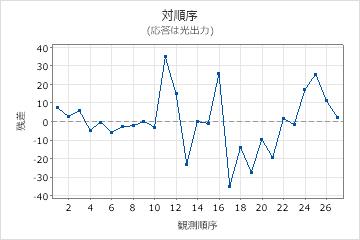
残差対順序プロット
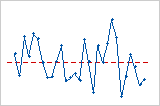
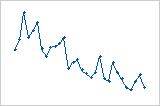
トレンド
シフト
周期
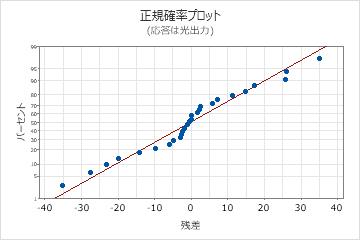
残差の正規確率プロット
残差の正規確率プロットを使用して、残差が正規分布に従うという仮定を検証します。残差の正規確率プロットは、ほぼ直線になります。
| パターン | パターンが示す意味 |
|---|---|
| 直線ではない | 非正規性 |
| 直線から離れた点 | 外れ値 |
| 変化する傾き | 未確認の変数 |