このトピックの内容
バランス型分散分析(ANOVA)モデル
3つ以上の因子に対するバランス型分散分析(ANOVA)モデルは、二元配置の分散分析モデルを単純に拡張させたものになります。
因子A、B、Cを持つ3因子バランス型分散分析(ANOVA)モデルは以下になります。
yijkm = μ + α i+ β j + γ k + (αβ)ij+ (αγ)ik+ (βγ)jk+ (αβγ)ijk+εijkm
固定因子の場合、 Σαi = 0、Σβj = 0、Σγk = 0、Σ(αβ)ij = 0、Σ(αγ)ik = 0、Σ(βγ)jk = 0、Σ(αβγ)ijk = 0、 εijkm は、N(0, σ2)に依存しません。
変量因子の場合、α i、 β j 、 γk、 (αβ)ij、 (αγ)ik、 (βγ)jk、 (αβγ)ijk、 εijkmは独立した確率変数です。変数は、平均0とV(αi) = σ2α、V(β j) = σ2β、V(γk) = σ2γ、V[(αβ)ij] = σ2αβ、V[(αγ)jk] = σ2αγ、V[(βγ)jk] = σ2βγ、V(εijkm) = σ2 により与えられる分散により正規に分布されています。
3因子モデルは3つ以上の因子を持つモデルに拡張することができます。
因子平均
計算式
与えられた水準での因子に対する観測値の平均です。計算式は以下です。
因子Aの平均: 
因子Bの平均: 
因子Cの平均: 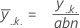
全体の平均: 
表記
| 用語 | 説明 |
|---|---|
| yi... | Aのi番目の因子水準の全観測値の合計 |
| y.j.. | Bのj番目の因子水準の全観測値の合計 |
| y..k. | Cのk番目の因子水準の全観測値の合計 |
| y.... | サンプルに含まれるすべての観測値の和 |
| a | Aの水準数 |
| b | Bの水準数 |
| c | Cの水準数 |
| n | 因子と水準の各組み合わせに含まれる観測値の数 |
平方和(SS)
距離の平方和です。全体平方和は、データ内の変動の合計です。平方和(A)、平方和(B)、平方和(C)は、全体平均から推定される因子水準平均の変動量で、処理の平方和としても知られます。平方和(AB)、平方和(AC)、平方和(BC)、平方和(ABC)は、それぞれに対応する交互作用項によって説明される変動量を表します。誤差の平方和は、適合値と実観測値間の変動量を表し、処理内誤差として知られます。これらの計算式は、完全モデルは適合されていることを前提としています。計算は次のようになります。

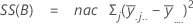

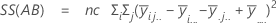
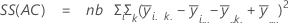


- 誤差の平方和=全体平方和 - 平方和(モデルに含まれる全項)
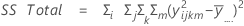
表記
| 用語 | 説明 |
|---|---|
| a | 因子Aの水準数 |
| b | 因子Bの水準数 |
| c | 因子Cの水準数 |
| n | 総試行回数 |
 | 因子Aのi番目の因子水準の平均 |
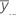 | すべての観測値の全体平均 |
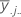 | 因子Bのj番目の因子水準の平均 |
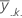 | 因子Cのk番目の因子水準の平均 |
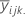 | 推定処理平均 |
自由度(DF)
モデルの各成分の自由度は以下の通りです。
| 変動要因 | 自由度(DF) |
|---|---|
| 因子 | ki – 1 |
| 共変量と共変量間の交互作用 | 1 |
| 因子を含む交互作用 | 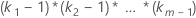 |
| 回帰 | p |
| 誤差 | n – p – 1 |
| 全体 | n – 1 |
表記
| 用語 | 説明 |
|---|---|
| ki | i番目の因子の水準数 |
| m | 因子数 |
| n | 観測値数 |
| p | 定数を含まないモデル内の係数の数 |
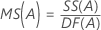
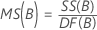
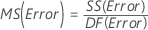
平均平方(MS)
計算式
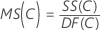
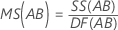

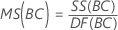
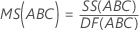
女性
すべて固定の3因子分散分析では、完全モデルの場合のF統計量は次の式で計算されます。
計算式


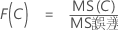




- F(A)では、自由度が分子で- 1、分母で(n - 1)abcです。
- F(B)では、自由度が分子でb - 1、分母で(n - 1)abcです。
- F(C)では、自由度が分子でc - 1、分母で(n - 1)abcです。
- F(AB)では、自由度が分子で(a - 1)(b - 1)、分母で(n - 1)abcです。
- F(AC)では、自由度が分子で(a - 1)(c - 1)、分母で(n - 1)abcです。
- F(BC)では、自由度が分子で(b - 1)(c - 1)、分母で(n - 1)abcです。
- F(ABC)では、自由度が分子で(a - 1)(b - 1)(c - 1)、分母で(n - 1)abcです。
モデルに無作為因子がある場合、各項のF比は各項の期待平均二乗によって定められます。
F値が大きいほど、帰無仮説を棄却する根拠になります。効果が統計的に有意であると結論付けることができます。
p値~分散分析表
p値は自由度(DF)が以下であるF分布から計算される確率です。
- 分子DF
- 項の自由度の和、または検定内の項
- 分母DF
- 誤差に対する自由度
計算式
1 − P(F ≤ fj)
表記
| 用語 | 説明 |
|---|---|
| P(F ≤ f) | F分布についての累積分布関数 |
| f | 検定におけるF統計量 |
S

表記
| 用語 | 説明 |
|---|---|
| 誤差の平均平方 | 誤差の平均平方 |
R二乗
R2は、決定係数とも言います。
計算式

表記
| 用語 | 説明 |
|---|---|
| yi | i番目の観測された応答値 |
 | 平均応答 |
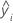 | i番目の適合された応答 |
R二乗(調整済み)
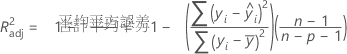
調整済みR2値に負値が算出される場合がありますが、Minitabでは0を表示します。
表記
| 用語 | 説明 |
|---|---|
 | i番目の観測された応答値 |
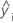 | i番目の適合された応答 |
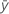 | 平均応答 |
| n | 観測値数 |
| p | モデルにおける項の数 |
分散成分
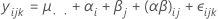
上の式で、αi、 βj 、 (αβ)ij、 および εijkはすべて独立した確率変数です。変数は、平均0とこれらの計算式により与えられる分散により正規に分布されています。
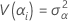



これらの分散は、分散成分です。この場合、分散成分が0に等しいという仮説を検定します。
2つの因子を持つ制約型混合モデルのモデルは次の通りです。
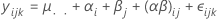
上の式で、αiは固定された効果でβjはランダム効果、(αβ)ijはランダム効果を表し、εijkはランダム誤差です。各jにおいて、Σαi = 0 および Σ(αβ)ij = 0 です。分散は、V(βj) = σ2β,V[(αβ)ij] =[(a - 1)/a]σ2αβ, and V(εijk) = σ2. σ2β, σ2αβで、σ2は分散成分です。交互作用成分を固定因子で累積すると0となり、これは制約型混合モデルであるということを示しています。
固定因子Aおよび変量因子Bを持つ無制約型混合モデルは以下の計算式で表されます。
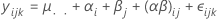
上の式で、αiは固定効果で、βj, (αβ)ijおよびεijkは平均を持たず、以下の分散を持つ無相関の確率変数です。



これらの分散は、分散成分です。各jにおいて、Σα i = 0 および Σ(αβ)ij = 0です。
この情報はバランス型モデルに適用します。アンバランス型モデルやさらに複雑なモデルに関する情報は、「モンゴメリー1」および「ニーター2」を参照してください。
- D.C. Montgomery (1991). Design and Analysis of Experiments, 第3版. John Wiley & Sons.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models, 第2版. Irwin, Inc.
平均平方の期待値

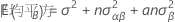


2つの因子A(固定)、B(変量)を持つ制約型混合モデルの平均平方の期待値を表す計算式は以下になります。
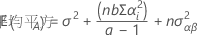



固定因子Aおよび変量因子Bを持つ無制約型混合モデルの平均平方の期待値を表す計算式は以下になります。
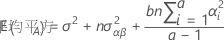
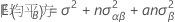


平均平方の期待値の計算に関するルール、およびアンバランス型モデルやさらに複雑なモデルに関する情報は、「モンゴメリー1」および「ニーター2」を参照してください。
- D.C. Montgomery (1991). Design and Analysis of Experiments, 第3版. John Wiley & Sons.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models, 第2版. Irwin, Inc.
表記
| 用語 | 説明 |
|---|---|
| b | 因子Bの水準数 |
| a | 因子Aの水準数 |
| n | 観測値数 |
| σ2 | モデルの推定分散 |
 | Aの推定分散 |
 | Bの推定分散 |
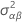 | ABの推定分散 |
 | Aの固定効果 |
変量因子を持つモデルのF統計量
分散分析の出力におけるF統計量の計算方法
各F統計量は平均平方の比です。分子は項の平均平方です。分母は分子の平均平方の期待値が分母の平均平方の期待値から対象となる効果だけ離れるように選択します。ランダム項の効果は、項の分散成分によって表されます。固定項の効果は、その項に関連付けられたモデル成分の平方和をその自由度で割ったものによって表されます。したがって、F統計量が高い場合、効果が有意であることを示します。
モデルのすべての項が固定の場合、各F統計量の分母は誤差の平均平方(MSE)です。ただし、ランダム項を含むモデルについては、MSEが常に正しい平均平方になるとは限りません。平均平方の期待値(EMS)を使用して何が分母に適しているかを判断できます。
例
| 要因 | 各項に対する平均平方の期待値 |
|---|---|
| (1)画面 | (4) + 2.0000(3) + Q[1] |
| (2)技術 | (4) + 2.0000(3) + 4.0000(2) |
| (3)画面*技術 | (4) + 2.0000(3) |
| (4)誤差 | (4) |
括弧に入った数字は、要因番号の横に記載する項に関連付けられたランダム効果を示します。(2)は技術のランダム効果を表し、(3)は画面*技術の交互作用のランダム効果を表し、(4)は誤差のランダム効果を表します。誤差のEMSは誤差項の効果です。さらに、画面*技術のEMSは誤差項の効果に画面*技術の交互作用の効果の2倍を加えたものです。
画面*技術のF統計量を計算するには、画面*技術の平均平方を誤差の平均平方で割って、分子の期待値(画面*技術のEMS = (4) + 2.0000(3))は分母の期待値(誤差のEMS = (4))から交互作用の効果(2.0000(3))だけ離れるようにします。したがって、F統計量が高い場合、画面*技術の交互作用が有意であることを示します。
Q[ ]が付いた数字は、要因番号の横に記載する項に関連付けられた固定効果を示します。たとえば、Q[1]は画面の固定効果です。画面のEMSは、誤差項の効果に画面*技術の交互作用の効果の2倍を加え、さらに画面の効果の定数倍を加えたものです。Q[1]は(b*n * sum((画面の水準の係数)**2))を(a - 1)で割ったものです。aとbはそれぞれ画面と技術の水準の数で、nは反復数です。
画面のF統計量を計算するには、画面の平均平方を画面*技術の平均平方で割って、分子の期待値(画面のEMS = (4) + 2.0000(3) + Q[1])が分母の期待値(画面*技術のEMS = (4) + 2.0000(3))から画面に起因する期待値(Q[1])だけ離れるようにします。したがって、F統計量が高い場合、画面の効果が有意であることを示します。
分散分析の出力で分散分析表のp値のそばに「x」とラベル「厳密なF検定ではありません」が表示される理由
項の正確なF検定とは、分子の平均平方の期待値が分母の平均平方の期待値から分散成分または対象の固定因子分だけ離れているものです。
ただし、こうした平均平方が計算できない場合もあります。この場合、Minitabでは近似のF検定の結果として得られる平均平方が使用され、p値のそばに「x」を表示して、F検定が正確でないことを示します。
| 要因 | 各項に対する平均平方の期待値 |
|---|---|
| (1)補助材料 | (4) + 1.7500(3) + Q[1] |
| (2)湖 | (4) + 1.7143(3) + 5.1429(2) |
| (3)補助材料*湖 | (4) + 1.7500(3) |
| (4)誤差 | (4) |
補助材料のF統計値は、補助材料の平均平方を補助材料*湖の交互作用の平均平方で割ったものです。補助材料の効果が非常に小さい場合、分子の期待値は分母の期待値と等しくなります。これは正確なF検定の例です。
ただし、湖の効果が非常に小さい場合、分子の期待値が分母の期待と等しくなるような平均平方は存在しない点に注意してください。したがって、Minitabでは近似のF検定が使用されます。この例では、湖の平均平方を補助材料*湖の交互作用の平均平方で割ります。これにより、湖の効果が非常に小さい場合、分子の期待値は分母の期待値とほぼ等しいという結果が得られます。
「F検定の分母がゼロまたは定義されていません」というメッセージについて
- 少なくとも1つの誤差に対する自由度が存在しない場合があります。
-
調整されたMS値が非常に小さく、F値やp値を表示する十分な精度に満たない場合。回避方法として、応答列を10倍にします。次に、同じ回帰モデルを実行しますが、応答にはこの新しい応答列を使用します。
注
応答値を10倍しても、Minitabで出力として表示されるF値およびp値には影響しません。ただし、それ以外の出力、具体的には逐次平方和、調整平方和、調整平均平方、適合値、適合値の標準誤差、残差列では小数点の位置が変わります。
分散分析の出力におけるF統計量の計算方法
各F統計量は平均平方の比です。分子は項の平均平方です。分母は分子の平均平方の期待値が分母の平均平方の期待値から対象となる効果だけ離れるように選択します。ランダム項の効果は、項の分散成分によって表されます。固定項の効果は、その項に関連付けられたモデル成分の平方和をその自由度で割ったものによって表されます。したがって、F統計量が高い場合、効果が有意であることを示します。
モデルのすべての項が固定の場合、各F統計量の分母は誤差の平均平方(MSE)です。ただし、ランダム項を含むモデルについては、MSEが常に正しい平均平方になるとは限りません。平均平方の期待値(EMS)を使用して何が分母に適しているかを判断できます。
例
| 要因 | 各項に対する平均平方の期待値 |
|---|---|
| (1)画面 | (4) + 2.0000(3) + Q[1] |
| (2)技術 | (4) + 2.0000(3) + 4.0000(2) |
| (3)画面*技術 | (4) + 2.0000(3) |
| (4)誤差 | (4) |
括弧に入った数字は、要因番号の横に記載する項に関連付けられたランダム効果を示します。(2)は技術のランダム効果を表し、(3)は画面*技術の交互作用のランダム効果を表し、(4)は誤差のランダム効果を表します。誤差のEMSは誤差項の効果です。さらに、画面*技術のEMSは誤差項の効果に画面*技術の交互作用の効果の2倍を加えたものです。
画面*技術のF統計量を計算するには、画面*技術の平均平方を誤差の平均平方で割って、分子の期待値(画面*技術のEMS = (4) + 2.0000(3))は分母の期待値(誤差のEMS = (4))から交互作用の効果(2.0000(3))だけ離れるようにします。したがって、F統計量が高い場合、画面*技術の交互作用が有意であることを示します。
Q[ ]が付いた数字は、要因番号の横に記載する項に関連付けられた固定効果を示します。たとえば、Q[1]は画面の固定効果です。画面のEMSは、誤差項の効果に画面*技術の交互作用の効果の2倍を加え、さらに画面の効果の定数倍を加えたものです。Q[1]は(b*n * sum((画面の水準の係数)**2))を(a - 1)で割ったものです。aとbはそれぞれ画面と技術の水準の数で、nは反復数です。
画面のF統計量を計算するには、画面の平均平方を画面*技術の平均平方で割って、分子の期待値(画面のEMS = (4) + 2.0000(3) + Q[1])が分母の期待値(画面*技術のEMS = (4) + 2.0000(3))から画面に起因する期待値(Q[1])だけ離れるようにします。したがって、F統計量が高い場合、画面の効果が有意であることを示します。
分散分析の出力で分散分析表のp値のそばに「x」とラベル「厳密なF検定ではありません」が表示される理由
項の正確なF検定とは、分子の平均平方の期待値が分母の平均平方の期待値から分散成分または対象の固定因子分だけ離れているものです。
ただし、こうした平均平方が計算できない場合もあります。この場合、Minitabでは近似のF検定の結果として得られる平均平方が使用され、p値のそばに「x」を表示して、F検定が正確でないことを示します。
| 要因 | 各項に対する平均平方の期待値 |
|---|---|
| (1)補助材料 | (4) + 1.7500(3) + Q[1] |
| (2)湖 | (4) + 1.7143(3) + 5.1429(2) |
| (3)補助材料*湖 | (4) + 1.7500(3) |
| (4)誤差 | (4) |
補助材料のF統計値は、補助材料の平均平方を補助材料*湖の交互作用の平均平方で割ったものです。補助材料の効果が非常に小さい場合、分子の期待値は分母の期待値と等しくなります。これは正確なF検定の例です。
ただし、湖の効果が非常に小さい場合、分子の期待値が分母の期待と等しくなるような平均平方は存在しない点に注意してください。したがって、Minitabでは近似のF検定が使用されます。この例では、湖の平均平方を補助材料*湖の交互作用の平均平方で割ります。これにより、湖の効果が非常に小さい場合、分子の期待値は分母の期待値とほぼ等しいという結果が得られます。
「F検定の分母がゼロまたは定義されていません」というメッセージについて
- 少なくとも1つの誤差に対する自由度が存在しない場合があります。
-
調整されたMS値が非常に小さく、F値やp値を表示する十分な精度に満たない場合。回避方法として、応答列を10倍にします。次に、同じ回帰モデルを実行しますが、応答にはこの新しい応答列を使用します。
注
応答値を10倍しても、Minitabで出力として表示されるF値およびp値には影響しません。ただし、それ以外の出力、具体的には逐次平方和、調整平方和、調整平均平方、適合値、適合値の標準誤差、残差列では小数点の位置が変わります。
適合値
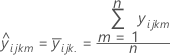
表記
3因子モデルでは次のようになります。
| 用語 | 説明 |
|---|---|
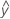 | 因子Aのi番目の水準、因子Bのj番目の水準、および因子Cのk番目の水準での観測値の適合値 |
 | 因子Aのi番目の水準、因子Bのj番目の水準、および因子Cのk番目の水準での観測値の平均値 |
| n | 因子Aのi番目の水準、因子Bのj番目の水準、および因子Cのk番目の水準での観測値数 |
残差(Resid)
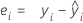
表記
| 用語 | 説明 |
|---|---|
| ei | i番目の残差 |
 | i番目の観測された応答値 |
 | i番目の適合された応答 |