許容限界区間の方法
Minitabでは、パラメトリックおよびノンパラメトリック許容限界区間を計算します。パラメトリック許容限界区間の計算では、サンプルの親分布は正規に分布していると仮定しています。ノンパラメトリック許容限界区間の計算では、親分布は連続分布であるということのみを前提としています。
一般定義
X 1、X 2、...X n は、ある連続的な分布から取られたサイズnのランダムなサンプルに基づく順序付け統計量であるとします。
次元が1以上の任意のパラメータ空間におけるΩの分布関数をF(x,θ)とします。
L < Uは、与えられる任意の値αおよびP(0 < α < 1および0 < P < 1)について、Ωにおけるすべてのθで以下が成り立つようなサンプルに基づいています。

すると、区間[L, U]はコンテンツ=P x 100%、信頼水準=100(1 – α)%の両側許容限界区間になります。このような区間は、両側(1 – α, P)の許容限界区間と呼ばれます。たとえば、α = 0.10およびP = 0.85とすると、導出される区間は、両側(90% , 0.85)の許容限界区間と呼びます。
L = –∞、およびU < +∞である場合、区間(-∞, U]は片側(1 – α, P)の上側許容限界と呼びます。L > -∞、およびU = +∞である場合、区間[L, +∞)は、片側(1 – α, P)の下側許容限界と呼びます。
- 片側(1 - α、P)の下側許容境界は、片側(α, 1 – P)の上側許容限界でもあります。
- データ分布の(1 - P)番目の百分位の片側(1 - α)100%の下側信頼限界は、片側(1 - α、P)の下側許容限界でもあります。同じように、データ分布のP番目の百分位の片側(1 - α)100%の上側許容境界は、片側(1 - α、P)の上側許容限界でもあります。
- LとUが片側(1 – α/2 、 (1 + P )/2)の下側および上側許容限界であるならば、[ L, U ]は近似両側(1 – α、 P)許容限界区間になります。この方法は、両側許容限界区間を直接得られない場合に使用されることがあります。得られる両側許容限界区間は通常、保守的な結果となります。ギュンター1と、ハーンおよびミーカー2を参照してください。
- Guenther, W. C. (1972). Tolerance intervals for univariate distributions. Naval Research Logistics, 19: 309–333.
- Hahn G. J. and Meeker W. Q. (1991). Statistical Intervals: A Guide for Practitioners John Wiley & Sons, New York.
正規分布での正確な許容限界区間

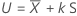
片側区間の許容限界因子
片側区間の正確な許容限界因子は次の等式で求められます。
ここで、tn-1,1-α(δ)は、自由度がn – 1で非心パラメータがδの非心t分布の第1 – α百分位数で、この百分位数は次の式で求められます。

両側区間の許容限界因子
両側区間の正確な許容限界因子は、kに関する次の等式を解くことで得られます。クリシュナムーシーとマシュー1を参照してください。
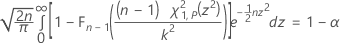
ここで、Fn – 1は、自由度がn – 1のカイ二乗分布とχ21の累積分布関数であり、pは、自由度が1で非心パラメータがz2の非心カイ二乗分布の第P百分位数です。等式の左側は次のように書き換えることができます。

ここで、
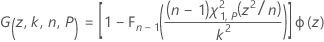
ここで、Φ(z)は標準正規分布の確率密度関数です。Minitabでは、36点のガウス-ルジャンドル積分を使用して、I(k, n, P)を評価します。
表記
| 用語 | 説明 |
|---|---|
| 1 - α | 許容限界区間の信頼水準 |
| p値 | 許容限界区間のカバー範囲(区間内の母集団の目標最小パーセント) |
| L | 許容限界区間の下側限界 |
| U | 許容限界区間の上側限界 |
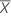 | サンプルの平均 |
| k | 許容限界因子(k因子とも呼ばれる) |
| S管理図 | サンプルの標準偏差 |
| n | サンプルに含まれる観測値の数 |
| ZP | 標準正規分布の第P百分位数 |
- Krishnamoorthy, K. and Mathew, T. (2009). Statistical Tolerance Regions: Theory, Applications, and Computation. Wiley, Hoboken, NJ.
連続分布での正確なノンパラメトリック許容限界区間
Minitabでは、正確な(1 - α, P)ノンパラメトリック許容限界区間(1 - αは信頼水準、Pは許容限界区間のカバー範囲(区間内の母集団の目標最小パーセント))が計算されます。許容限界区間のノンパラメトリック法は分布無しの方法です。つまり、ノンパラメトリックな許容限界区間はサンプルの親母集団に依存しないということです。Minitabでは、片側区間と両側区間の両方の厳密法が使用されます。
X 1、X 2、...、X nは、ある連続的に分布する母集団F(x;θ)から取られたランダムサンプルの順序付け統計量であるとします。すると、ウィルクス1, 2とロビンズ3の結果に基づき、次のように表すことができます。

ここでBは、パラメータがa = rとb = n – s + 1のベータ分布の累積分布関数を表します。したがって、(Xr、Xs)は分布なしの許容限界区間です。これは、この区間のカバー範囲に、親母集団F(x;θ)の分布から独立した既知のパラメータ値を使用したベータ分布が含まれるからです。
片側区間
kは以下を満たす最大の整数であるとします。

ここでYは、パラメータがnおよび1 - Pの二項ランダム変数です。片側(1 – α, P)の下側許容限界は、Xk として与えられます(クリシュナマーシーおよびマシュー4を参照)。同じように、片側(1 – α, P)の上側許容限界は、X n - k +1として与えられます。どちらの場合でも、実際または有効なカバー範囲は、P(Y > k)で与えられます。
両側区間
kは、以下を満たす最小の整数であるとします。

ここでVは、パラメータがnおよびPの二項ランダム変数です。したがって、
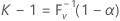
ここでF V -1(x)は、Vの逆累積分布関数です。両側(1 – α, P)の許容限界区間は、(Xr , Xs )として与えられます(クリシュナマーシーおよびマシュー4を参照)。Minitabでは、s = n - r + 1を選択し、r = (n – k + 1) / 2が成り立つようにしています。rとsは、どちらも直近の整数に切り捨てられます。実際の、すなわち有効なカバー範囲は、P(V < k – 1)で与えられます。
表記
| 用語 | 説明 |
|---|---|
| 1 – α | 許容限界区間の信頼水準 |
| P | 許容限界区間のカバー範囲(区間内の母集団の目標最小パーセント) |
| n | サンプルに含まれる観測値の数 |
- Wilks, S. S. (1941). Sample size for tolerance limits on a normal distribution. The Annals of Mathematical Statistics, 12, 91–96.
- Wilks, S. S. (1941). Statistical prediction with special reference to the problem of tolerance limits. The Annals of Mathematical Statistics, 13, 400–409.
- Robbins, H. (1944). On distribution-free tolerance limits in random sampling. The Annals of Mathematical Statistics, 15, 214–216.
- Krishnamoorthy, K. and Mathew, T. (2009). Statistical Tolerance Regions: Theory, Applications, and Computation. Wiley, Hoboken, NJ.