ステップ1: データのパターンを探す
ランチャートには、工程データが収集順にプロットされます。ランチャートを使用して、特別原因による変動の存在を示すデータのパターンまたはトレンドを探します。
データのパターンは、変動の原因が特別原因にあり、調査して修正する必要があることを示します。ただし、一般原因による変動は、工程に固有の、つまり工程の性質としての変動です。特別原因ではなく、一般原因のみが工程出力に影響している場合、工程は安定します。工程に存在するのが一般原因のみの場合、データはランダム性を示します。
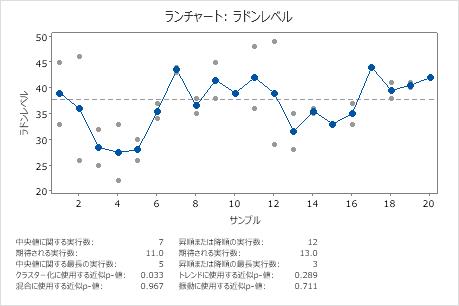
これらの結果において、データは、サンプル数が3~5の場合にある程度のクラスター化を示しています。
ステップ2: 混合とクラスターが存在するかどうか判断する
中央値付近の実行数の検定は、中央値の上下両側に見られる実行の総数に基づいています。中央値付近の連とは、中心線から見て同じ側にある1つ以上の連続する点のことです。連は、点をつなぐ線が中心線と交差するときに終わります。新しい連は、次にプロットされる点から始まります。
この検定では、混合とクラスターという2種類の非ランダムな動作を検出します。
観測される実行数が期待される実行数より多い場合は、混合の存在を示します。観測される実行数が期待される実行数より少ない場合は、クラスターが存在することを示唆します。
- クラスターパターン
- クラスターは、測定上の問題、ロット間または設定時の変動性、不良部品のグループからのサンプル抽出など、特別原因による変動があることを示唆します。クラスターとは、管理図内の1つの領域にある点の集まりです。クラスター化のp値が0.05未満の場合、データにクラスターがあることが考えれらます。
-
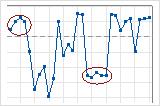
この管理図には、データのクラスターが存在する可能性が示されています。
- 混合パターン
- 混合の特徴は、中心線を頻繁に交差することです。多くの場合、混合の存在は、2つの母集団がデータに混在しているか、2つの工程が異なる水準で行われていることを示しています。混合のp値が0.05未満の場合、データに混合があることが考えれらます。
-
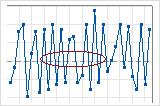
この管理図において、混合の存在は、データが異なる工程から抽出されたことを示す可能性があります。
主要な結果: クラスター化のp値、混合のp値
この例において、クラスター化のp値0.385と混合のp値0.615はα値0.05より大きくなっています。したがって、データには混合またはクラスターが存在しないと結論付けることができます。
ステップ3: トレンドと振動が存在するかどうか判断する
上昇および下降の実行数の検定は、上昇または下降の観測された実行の合計数に基づいています。上昇連は、増大する一方の連続する点による上向きの連です。下降連は、減少する一方の連続する点による下向きの連です。連は芳香(上昇または下降)が変わるときに終わります。たとえば、前の値がその次の値より小さい場合に上昇連が始まり、後続の値がその次の点の値より大きくなるまで続き、そこから下降連が始まります。
この検定では、振動とトレンドという2種類の非ランダムな動作を検出します。
観測される連数が期待される連数より多い場合は、振動が存在することを示唆します。観測される実行数が期待される実行数より少ない場合は、トレンドが存在することを示唆します。
- トレンドパターン
- データのトレンドとは、持続するデータのドリフト(上昇または下降)を指します。トレンドは、工程が間もなく管理外になることを警告するものです。トレンドの原因は、摩耗したツール、設定を維持しない機械、または作業者の時間交代などの因子です。トレンドのp値が0.05未満の場合は、データにトレンドが存在する可能性があります。
-
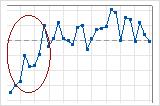
この管理図では、最初の少数のデータに上向きトレンドがあることがよくわかります。
- 振動パターン
- 振動は、データが上下変動する場合に発生し、工程が不安定であることを示します。振動のp値が0.05未満の場合は、データに振動が存在する可能性があります。
-
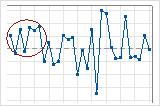
この管理図では、データが頻繁に上下に変動しているように見えます。
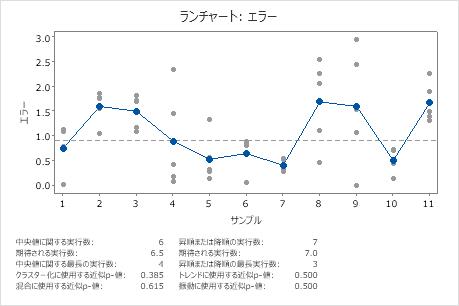
主要な結果: トレンドのp値、振動のp値
この例において、トレンドのp値0.500と振動のp値0.500はα値0.05より大きくなっています。したがって、データはトレンドまたは振動の存在を示さないと結論付けることができます。