Kendallの一致係数
3つ以上の水準を持つ順序データを使用する場合、Kendallの統計量を使用します。
方法の説明の中で、一般性を損なうことなく、各対象の1回の評価は各評価者によって行われ、対象ごとにk人の評価者がいると仮定します。そして、Kendallの係数を計算するには、k人の評価者は各評価者によるk回の試行を表します。
データがk x Nの表に表示されていて、各行は、特定の評価者によってN個の対象に割り当てられた順位を表すとします。
計算式
真の標準が未知の場合、Minitabでは次のようにしてKendallの係数を推定します。
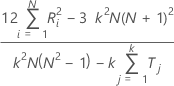
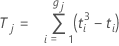
表記
| 用語 | 説明 |
|---|---|
| N | 対象数 |
| Σ Ri2 | 順位付けされたN個の対象のそれぞれの順位の和の平方の和 |
| K | 検査者の数 |
| Tj | Tjは、評価の平均を同順位の観測値に割り当てます |
| 用語 | 説明 |
|---|---|
| ti | i番目の同順位グループ内の同順位の数 |
| gj | j番目の順位セット内の同順位グループの数 |
Kendallの一致係数の有意性検定
Kendallの係数の有意性を検定するには、次の計算式を使用します。
c 2= k (N – 1) W
表記
| 用語 | 説明 |
|---|---|
| c 2 | 自由度がN-1のカイ二乗分布に従っています |
| k | 検査者の数 |
| N | 対象の数 |
| W | 計算されたKendallの係数 |
Kendallの相関係数
3つ以上の水準を持つ順序データを使用する場合、Kendallの統計量を使用します。
方法の説明の中で、一般性を損なうことなく、各対象の1回の評価は各評価者によって行われ、対象ごとにk人の評価者がいると仮定します。そして、Kendallの相関係数を計算するには、k人の評価者はすべての評価者によるk回の試行を表します。
真の標準が既知の場合、Kendallの相関係数は、各検査者と標準の間のKendallの係数の平均を計算することによって推定されます。
標準が既知の場合の試行の一致性に対するKendallの相関係数は、全試行のKendallの相関係数の平均です。
計算式
Minitabでは、次の計算式を使用して、各試行と標準の間のKendallの係数を計算します。

表記
| 用語 | 説明 |
|---|---|
| TX | Xが同じ値のペアの数 = 0.5 Σi ni+ (ni+– 1) |
| TY | Yが同じ値のペアの数 = 0.5 Σj n+j (n+j– 1) |
| C | 一致ペアの数 = Σi<kΣj<l nij nkl |
| D | 一致しないペアの数 = Σi<kΣj>l nij nkl |
| 用語 | 説明 |
|---|---|
| ni+ | i行目の観測数 |
| n+j | j列目の観測数 |
| nij | i行目でj列目のセルの観測数 |
| nkl | k行目でl列目のセルの観測数 |
| n++ | 合計観測数 |
参考文献
A. Agresti (1984). Analysis of Ordinal Categorical Data, John Wiley & Sons.
Kendallの相関係数の有意性検定
計算式
真の標準が既知の場合にKendallの係数の有意性を検定するには、次の計算式を使用します。
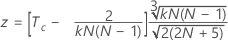
次の計算式を使用します。
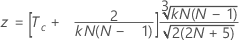
表記
| 用語 | 説明 |
|---|---|
| Tc | 各検査者と標準の間のKendallの相関係数の平均 |
| N | 対象の合計数 |
| k | 評価者数 |