サンプルサイズと限界距離
サンプルサイズ、n、限界距離、kの計算は、指定された規格限界の数と標準偏差が明らかかどうかによって変わります。
単一規格限界と既知の標準偏差
サンプルサイズは以下で求められます。
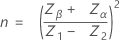
限界距離は以下で求められます。

ここで、
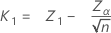
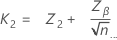
表記
| 用語 | 説明 |
|---|---|
| Z1 | 標準正規分布の (1 – p1)* 100 百分位数 |
| p1 | 合格品質水準(AQL) |
| Z2 | 標準正規分布の 1 – p2) * 100 百分位数 |
| p2 | 不合格となる品質水準(RQL) |
| Zα | 標準正規分布の(1 – α) * 100百分位数 |
| α | 生産者リスク |
| Zβ | 標準正規分布の(1 – β) * 100百分位数 |
| β | 消費者リスク |
単一規格限界と未知の標準偏差
表記は単一規格限界と既知の標準偏差と同じです。サンプルサイズは以下で求められます。
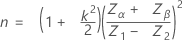
限界距離は以下で求められます。
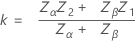
二重規格限界と既知の標準偏差
以下で定義されていない表記は単一規格限界と既知の標準偏差のケースと同じです。まずzが計算されます。
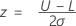
その後、右肩あがりの領域として標準正規分布からp値を見つけます。これは規格限界の範囲外の最小の不良率です。
サンプルサイズと限界距離の計算に使用する方法はp*のこの値によって変わります。
p1 = AQL、p2 = RQLとします
- 2p* ≤ (p1/ 2)の場合、2つの規格はかなり離れており、計算は単一の規格計画に従います。
- 1/ 2 < 2p* ≤ p1の場合、2つの規格はあまり離れていないもののそれほど近くにあるわけでもないので、不良率の最小値は特定の平均値付近にあります。Minitabでは反復を繰り返して、サンプルサイズと限界距離を見つけます。
次のように定義します。
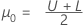
μ = μ0+ m * h、ここで h = σ/100
m = 1, 2, ...300と仮定します。各μの計算は次のとおりです。

ここでΦは、標準正規分布の累積分布関数です。Prob (X<L) + Prob (X>U)は限りなくp1に近く、Prob (X<L)とProb (X>U)のうち、大きい方の値を使用して、サンプルサイズと合格数を見つけます。
Prob (X<L)の値が大きいとする場合、pL = Prob (X<L)と仮定します。
サンプルサイズは以下で求められます。
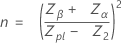
限界距離は以下で求められます。

ここで、

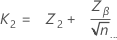
標準正規分布のZpL = the (1 – pL) * 100百分位数
すべてのmの値をすでに使用している一方で対応する確率にp1が含まれていない場合はp1が大きすぎ、測定値の平均は区間[L, U]の中点から離れています。こうしたケースでは、単一規格限界およびZpL = Z1の方法を使用できます。Z1の定義は、単一規格限界のケースと同じです。
- p1 < 2p* < p2の場合、2つの規格限界と標準偏差によって決まる最小不良確率は最小値合格品質水準p1を上回るので、計画の規格を再検討する必要があります。ロットを不合格にするか、p1よりも不良率が若干大きい計画を検討することができます。
- 2p* ≥ p22の場合、ロットを不合格にする必要があります。2つの規格限界と標準偏差によって決まる最小不良確率が、拒否品質水準を上回ります。製品を検査せずにロットを不合格にできます。
表記
| 用語 | 説明 |
|---|---|
| L | 下側規格限界 |
| U | 上側規格限界 |
| σ | 既知の標準偏差 |
二重規格限界と未知の標準偏差(デフォルト手順)
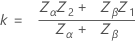
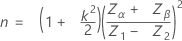
- 次のように定義します。
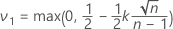
- ここで、
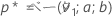
 .
. -
- ここで、

-

-

n ≤ 2の場合、最大標準偏差(MSD)は計算できません。
二重規格限界と未知の標準偏差(Wallis手順)
表記は前のセクションと同じです。手順はSchillingの書籍を参照できます。2
第1限界距離が、2つの異なる片側限界計画があるケースで設定される値であると仮定します。
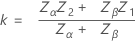
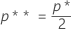
次に、標準正規分布からの右肩あがりの領域 p* を、k に対応する百分位数として検出し、p* / 2の右肩あがりの領域に対応する標準正規分布からの百分位数 Zp** を検出します。
最大標準偏差(MSD)は次の方法で指定されます。
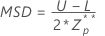
標準偏差の推定値は次のように求められます。
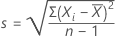
Minitabでは、推定標準偏差 s がMSD以下であるかどうかをテストします。
推定標準偏差 s がMSD以下の場合、サンプルサイズは次の値で指定されます。
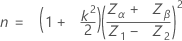
推定標準偏差 s が MSD以上の場合、標準偏差が大きすぎて受入基準と一致しないため、ロットを不合格にする必要があります。
表記
| 用語 | 説明 |
|---|---|
| Xi | i番目の測定値 |
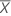 | 実測値の平均 |
合格確率
pを、OC曲線上の点のx値である不良率と仮定します。
単一規格限界と既知の標準偏差
- 単一の下側規格限界と既知の標準偏差
- Prob (X < L) = p.
-

- 単一の上側規格限界と既知の標準偏差
- Prob (X > L) = p.
-

単一規格限界と未知の標準偏差
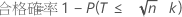
二重規格限界と既知の標準偏差
まずzが計算されます。

その後、右肩あがりの領域としてzに応じて標準正規分布からp値を見つけます。これは規格限界の範囲外の最小の不良率です。
合格確率に使用する方法はp*のこの値によって変わります。
p1 = AQL、p2 = RQLと仮定
- 2p* ≤ (p1/ 2)の場合、2つの規格はかなり離れており、サンプルサイズと限界距離の計算は単一の規格計画に従います。
- p1/ 2 < 2p* ≤ p1の場合、2つの規格はあまり離れていないもののそれほど近くにあるわけでもないので、不良率の最小値は特定の平均値付近にあります。
pが任意の場合、グリッド検索アルゴリズムを使用して測定値の平均(μ)を見つけます。
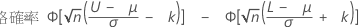
二重規格限界と未知の標準偏差
上側規格限界と下側規格限界の両方があるものの標準偏差がわからない場合、単一限界計画のOC曲線を使用して二重規格限界のケースに近似させます。指定されたp1、p2、α、βを持つ単一限界計画から導き出されたOC曲線は、同じp1、p2、α、βを持つ両側規格計画のOC曲線の区間の下側限界であり、最も実践的なケースでは、両側計画のOC曲線と見なすこともできます。ダンカン1を参照してください。
- Duncan(1986年)『Quality Control and Industrial Statistics』第5版
表記
| 用語 | 説明 |
|---|---|
| n | サンプルサイズ |
| k | 限界距離 |
| σ | 既知の標準偏差 |
| Zp | 標準正規分布の第(1 - p)百分位数 |
| Φ | 標準正規分布の累積分布関数 |
| T |
は自由度 = n - 1および次の非心パラメータを使用した非心t分布です。 |
| L | 下側規格限界 |
| U | 上側規格限界 |

不合格確率
不合格確率(Pr)は、特定の抜取計画と入不良比率に基づいて特定のロットを不合格と判定する確率を示します。単純に、1から合格確率を引いた値となります。
Pr = 1 – Pa
ここで、
Pa = 合格確率
平均出検品質(AOQ)
平均出検品質は、検査後の製品の品質水準を表します。平均出検品質は、入不良率の変化に伴って変化します。
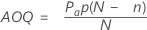
表記
| 用語 | 説明 |
|---|---|
| Pa | 合格確率 |
| p | 入不良率 |
| N | ロットサイズ |
| n | サンプルサイズ |
平均検査数(ATI)
平均検査数は、特定の入検品質水準と合格確率について検査する平均単位数を表します。

表記
| 用語 | 説明 |
|---|---|
| Pa | 合格確率 |
| N | ロットサイズ |
| n | サンプルサイズ |
合格領域(AR) - デフォルトの手順
合格領域は、両方の仕様が与えられ、標準偏差が不明である場合にのみ計算されます。サンプルサイズと臨界距離のセクションに進み、それぞれn と kの定義を見つけ、方程式の表記を確認します。
合格領域プロットでは、X軸がサンプル平均で、Y軸がサンプル標準偏差です。合格領域は、最大標準偏差(MSD)に加え、サンプル標準偏差およびサンプル平均の3つの関数で構成されています。サンプル標準偏差の値がMSDを越える場合のサンプル平均の値では、合格領域の上側境界がMSDになります。
上側規格限界または下側規格限界の近辺では、合格領域は、次の2の関数で境界が区切られています。
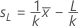

- 次のように定義します。
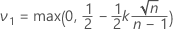 .
.
- 次に、
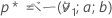 ここでベータは、形状パラメータaおよびbを持つベータ分布の累積分布関数です。ここで、
ここでベータは、形状パラメータaおよびbを持つベータ分布の累積分布関数です。ここで、 .
.
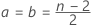
- p02 + p01 = p* を満たす比 p01 および p02のペアを定義します。
- 次に、


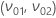 、平均と標準偏差の座標の式は以下の通りです。
、平均と標準偏差の座標の式は以下の通りです。
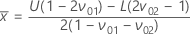
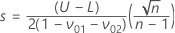
合格領域(AR) - Wallis 手順
以下の計算は、分析に両方の仕様があるが、標準偏差が不明である場合のものです。手順はSchillingの書籍を参照できます。2
 ) Y軸は標準偏差の値を示します。X軸と組み合わせて、以下の線のように合格三角形を形成します。
) Y軸は標準偏差の値を示します。X軸と組み合わせて、以下の線のように合格三角形を形成します。


破線と x 軸は、より正確な領域を形成します。破線を描くには以下の手順を行います。
- p* を標準正規分布からの右肩あがりの領域にし、臨界距離をパーセンタイルとします。 P(Z > k).
- p02 + p01 = p* を満たす p01および p02の値を選択します。
- p01 = (p* / 100) * h
- p02 = (p* / 100) * (100 - h)
ここで h は 1から00までの値を取ります。
- X座標とY座標を定義するには、次の式を使用します。
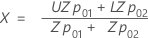
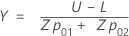
表記
| 用語 | 説明 |
|---|---|
| L | 下側規格 |
| U | 上側規格 |
| k | 限界距離 |
| Zp01 | 標準正規分布の (1 - p01)* 100 百分位数 |
| Zp02 | 標準正規分布の (1 - p02)* 100 百分位数 |
| p01 | (p* / 100) * h |
| p02 | (p* / 100) * (100 – h) |