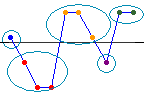
Step 1: Examine the difference between the observed number of runs and the expected number of runs
The observed number of runs is the number of groups of observations that are above or below the comparison criterion, K. The line represents K. This example contains five runs.
If the number of observed runs is substantially greater than or less than the number of expected runs, it is likely that the data are not in random order. To determine whether the order of your data is random, compare the p-value to the significance level.
Test
Null hypothesis
H₀: The order of the data is random
Alternative hypothesis
H₁: The order of the data is not random
Number of Runs
Observed
Expected
P-Value
17
16.77
0.930
Key Results: Observed number of runs, Expected number of runs
In these results, the value for the observed number of runs is very close to the value for the expected number of runs.
Step 2: Determine whether the order of your data is random
To determine whether the order of your data is random, compare the p-value to the significance level. Usually, a significance level (denoted as α or alpha) of 0.05 works well. A significance level of 0.05 indicates a 5% risk of concluding that the order of your data is not random when it actually is random.
P-value ≤ α: The order of the data is not random (Reject H0)
If the p-value is less than or equal to the significance level, the decision is to reject the null hypothesis and conclude that the order of the data is not random.
P-value > α: Cannot conclude the order of the data is not random (Fail to reject H0)
If the p-value is greater than the significance level, the decision is to fail to reject the null hypothesis. You do not have enough evidence to conclude that the order of the data is not random.
Test
Null hypothesis
H₀: The order of the data is random
Alternative hypothesis
H₁: The order of the data is not random
Number of Runs
Observed
Expected
P-Value
17
16.77
0.930
Key Result: P-Value
In these results, the null hypothesis states that the order of the data is random. Because the p-value is 0.930, which is greater than the significance level of 0.05, the decision is to fail to reject the null hypothesis. You do not have enough evidence to conclude that the order of the data is not random.