データ可視化
グラフビルダー
グラフビルダー を使用してデータを視覚化し、グラフの代替案を検討します。入力に基づいて、 グラフビルダー 使用可能なグラフ候補のプレビューが表示されます。グラフ ギャラリーを探索しながら、グラフの候補を選択し、選択したグラフのオプションを設定して、変更の影響をリアルタイムで確認できます。
主なエリア
- 1:列セット列セレクターパネル
- アクティブなワークシートの列の一覧。
- 2:列セットソースデータパネル
- 選択したグラフに関連付けられている使用可能な入力フィールドと表示オプション。
- 3:列セット候補リスト
- 使用可能なすべてのグラフの完全なリスト。
- 4:列セットカンバス
- Minitabでグラフのプレビューを表示する領域。
ヒント
- マウスで変数を入力するには、列セレクターパネルで変数をクリックし、ソースデータパネルの入力フィールドにドラッグします。
- キーボードで変数を入力するには、入力フィールドをクリックするか、Tab キーで入力フィールドに移動し、入力する変数の列名または列番号 ( C1 や Flawsなど) を入力します。
- グラフ上の変数の順序を並べ替えるには、入力フィールド内の変数をクリックし、同じフィールド内の新しい場所またはソースデータパネル内の別のフィールドにドラッグします。
- ソースデータパネルから変数を削除するには、
 をクリックするか、変数を選択して 削除 キーを押します。
をクリックするか、変数を選択して 削除 キーを押します。
ヒストグラム
ヒストグラムを使用して、データの形状と広がりを調べます。ヒストグラムは、サンプルサイズが少なくとも20の場合に最適です。
連続変数
グラフ化する数値列を 1 つ以上入力します。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。
Yスケール
- 度数
- 各バーの高さは、ヒストグラムのビン内にある観測値の数を表します。
- パーセント
- バーごとの高さは、ビン内に分布するサンプル観測値のパーセントを表します。パーセントスケールを持つヒストグラムは相対度数ヒストグラムと呼ばれることがあります。異なるサイズのサンプルを比較する場合はパーセントスケールを使用します。
確率プロット
確率プロットを使用して、データに対する分布の適合度を評価し、百分位数を推定し、サンプル分布を比較します。確率プロットには、各値と、サンプル内でそのデータ点以下の値のパーセントが適合分布線に沿って表示されます。適合分布が直線を形成するように、Y軸が変換されます。
連続変数
グラフ化する数値列を 1 つ以上入力します。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。
分布
箱ひげ図
箱ひげ図を使用して、サンプル分布の形、中心傾向、変動性を評価、比較し、外れ値を探すことができます。箱ひげ図は、サンプルサイズが少なくとも20の場合に最適です。
連続変数
グラフ化する数値列を 1 つ以上入力します。
カテゴリ(分類)変数 (オプション)
グループを定義するカテゴリ データの列を最大 5 つまで入力します。最初の変数がスケールの一番外側に、最後の変数が一番内側になります。
ひげと外れ値
- ジッター外れ値
- グラフ上のデータ値が同じなら、外れ値のシンボルが互いに隠れてしまうことがあります。このオプションを選択すると、シンボルが少し移動して重なり合うポイントが表示されます。
カスタムパーセンタイル
大規模なデータセットでは、外れ値がよく使われる場合、外れ値の代わりにカスタムパーセンタイルを表示して、より多くの情報を収集できます。カスタムパーセンタイルは四分位ボックスの外側で発生し、通常は分布の裾で発生します。さらに、線は最小値と最大値に配置されます。デフォルトでは、これらのパーセンタイル値は 0.5、2.5、10、90、97.5、99.5 ですが、追加、削除、または変更できます。
Yスケール
- 元の単位
- 数値変数には元の測定単位を使用します。
- 標準化された単位
- 異なる測定単位を標準単位に変換して、数値変数を比較できるようにします。
変数の表示順序
Minitabでは、「一番内側」と「一番外側」という言葉を使用して、グラフに表示されるグループの複数の水準のスケールの相対位置を示します。水平スケールでは、一番外側はグラフの底面のスケールを指し、一番内側は底面から最も離れている(水平軸に最も近い)スケールを指します。垂直スケールでは、一番外側はグラフの一番左のスケールを指し、一番内側は垂直軸に最も近いスケールを指します。
- カテゴリ変数が最初に、Yの下
- グラフ変数は最も外側のグループで、カテゴリ変数は最も内側のグループです。
- Yの最初の、以下のカテゴリ変数
- グラフ変数は最も内側のグループで、カテゴリ変数は最も外側のグループです。
区間プロット
区間プロットを使用して、グループの平均の信頼区間を評価および比較します。区間プロットは各グループの平均に対して95%信頼区間を示しています。区間プロットはサンプルサイズがグループあたり、少なくとも10の場合に最適です。通常、サンプルサイズが大きいほど信頼区間は小さく、より正確になります。
連続変数
グラフ化する数値列を 1 つ以上入力します。
カテゴリ(分類)変数 (オプション)
グループを定義するカテゴリ データの列を最大 5 つまで入力します。最初の変数がスケールの一番外側に、最後の変数が一番内側になります。
信頼区間
信頼区間の設定を指定します。
- 信頼水準
- 信頼区間の信頼水準を入力します。通常、95%の信頼水準が適切です。95%の信頼水準は、母集団から100個のランダムサンプルを採取した場合、サンプルのうちおよそ95個の信頼区間に母数が含まれることを示しています。
- ボンフェローニ法を使用する
- 信頼区間のセット全体に対する同時信頼水準を制御する方法です。母集団のパラメータが含まれない信頼区間が少なくとも1つある確率は、単一の区間よりも複数の区間の方が高くなるため、複数の信頼区間を調べる場合には同時信頼水準を考慮することが重要です。高い過誤率に対処するには、ボンフェローニの方法を使用してそれぞれの個別信頼区間の信頼水準を調整し、同時信頼水準を指定した値と等しくします。
- 両側
- 両側信頼区間を用いて、平均値の下限値と上限値の両方を推定します。
- 上方片側
- 下側信頼限界を使用して、平均の可能性が高い低い値を推定します。
- 下方片側
- 上側信頼限界を使用して、平均の可能性が高い高い値を推定します。
- 併合標準偏差を使用する
- すべての母集団に等分散があると仮定できる場合に選択します。
Yスケール
- 元の単位
- 数値変数には元の測定単位を使用します。
- 標準化された単位
- 異なる測定単位を標準単位に変換して、数値変数を比較できるようにします。
変数の表示順序
Minitabでは、「一番内側」と「一番外側」という言葉を使用して、グラフに表示されるグループの複数の水準のスケールの相対位置を示します。水平スケールでは、一番外側はグラフの底面のスケールを指し、一番内側は底面から最も離れている(水平軸に最も近い)スケールを指します。垂直スケールでは、一番外側はグラフの一番左のスケールを指し、一番内側は垂直軸に最も近いスケールを指します。
グループを持つ複数の Y 変数がある場合は、次のいずれかのオプションを選択します。
- カテゴリ変数が最初に、Yの下
- グラフ変数は最も外側のグループで、カテゴリ変数は最も内側のグループです。
- Yの最初の、以下のカテゴリ変数
- グラフ変数は最も内側のグループで、カテゴリ変数は最も外側のグループです。
個別値プロット
個別値プロットを使用して、サンプルデータの分布を評価および比較します。個別値プロットには、グループ内の各オブザベーションの実際の値を表すドットが表示されるため、外れ値を見つけやすくなり、分布の広がりを簡単に確認できます。
連続変数
グラフ化する数値列を 1 つ以上入力します。
カテゴリ(分類)変数 (オプション)
グループを定義するカテゴリ データの列を最大 5 つまで入力します。
ジッター個別シンボル
グラフ上のデータ値が同じなら、個々のシンボルが互いに隠れてしまうことがあります。このオプションを選択すると、シンボルが少し移動して重なり合うポイントが表示されます。
Yスケール
- 元の単位
- 数値変数には元の測定単位を使用します。
- 標準化された単位
- 異なる測定単位を標準単位に変換して、数値変数を比較できるようにします。
変数の表示順序
Minitabでは、「一番内側」と「一番外側」という言葉を使用して、グラフに表示されるグループの複数の水準のスケールの相対位置を示します。水平スケールでは、一番外側はグラフの底面のスケールを指し、一番内側は底面から最も離れている(水平軸に最も近い)スケールを指します。垂直スケールでは、一番外側はグラフの一番左のスケールを指し、一番内側は垂直軸に最も近いスケールを指します。
- カテゴリ変数が最初に、Yの下
- グラフ変数は最も外側のグループで、カテゴリ変数は最も内側のグループです。
- Yの最初の、以下のカテゴリ変数
- グラフ変数は最も内側のグループで、カテゴリ変数は最も外側のグループです。
変動図
周期的な変動や因子間の交互作用などのデータの変動を調査するには、予備ツールとして変動図を使用します。変動図は、因子と応答の関係を示します。各管理図に最大8因子が表示されます。データの考慮事項、例、および解釈については、 変動チャートの概要を参照してください。
応答変数
測定データを含む数値列を入力してください。
因子
因子の水準を含む列を入力します。最初の変数がスケールの一番外側に、最後の変数が一番内側になります。最大8つの因子を持つことができます。。
データ表現
- 個別のデータ点
- 個々のデータ点を、変動成分グラフのある平均応答にプロットします。
- 1つのセルの範囲
- 因子水準の各組み合わせの最小データポイントおよび最大データポイントを接続する、すべての範囲バーを表示します。
- セルの平均結線
- 因子の水準組み合せの平均値を接続する線を追加します。
- 全平均
- 全体平均の横線を、変動成分グラフのある平均応答に表示します。
- 因子の平均
- 変動付き平均応答チャートの因子の平均に水平線を表示します。
尺度
- ログ変換: Y スケール
-
同じ距離がスケール全体の異なる値の変化を表すため、対数スケールは軸を変えることで対数関係を直線化します。たとえば、変換されていない Y スケールの散布図では、関数は線形ではありません。Y スケールを対数基数 e に変換すると、データの形式は線形になります。

変形されていないYスケール

変換された Y スケール (log base 10 変換)
折れ線グラフ
折れ線グラフ を使用して、関数または系列の応答パターンを比較します。比較したいグループ数や系列の長さに応じて、記号ありまたは記号なしの線図を作成できます。
要約変数
折れ線グラフのポイントを定義する列を入力します。
関数から、要約変数の関数を選択します。たとえば、「 最大」を選択した場合、Minitabでは、集計された変数の最大値に基づいてグラフの色が定義されます。要約変数にテキスト列を入力する場合、選択できるのは 指定した値と等しいパーセント、 非欠損値の数、または 欠損値の数のみです。
- パーセンタイル
- パーセンタイルを選択する場合は、パーセント値:に値を入力する必要があります。値は0~100の範囲で指定します。Minitabでは、入力した値を使用してグラフの色のグラデーションが定義されます。たとえば、「50」と入力すると、50パーセンタイルを使用してグラフ上の各点の色のグラデーションが定義されます。
- 2 つ値の間のパーセント
- 2 つ値の間のパーセントを選択した場合は、 最初の値 と 2 番目の値で数値を入力する必要があります。最初の値に入力する値は、2 番目の値に入力した値以下である必要があります。Minitabでは、2つの値の間にある観測値のパーセンテージに基づいて、グラフの色のグラデーションを定義します。
- 指定した値と等しいパーセント
- 指定した値と等しいパーセントを選択する場合は、値に1つ以上の値を入力する必要があります。値は、要約変数で入力した列と同じ種類のデータである必要があります。Minitabでは、入力する値に等しい観測値のパーセンテージに基づいて、グラフのカラーグラデーションを定義します。
カテゴリ変数
x 軸を定義するカテゴリ変数を入力します。
凡例グループ
複数の 要約変数を入力すると、複数の集計変数が同じグラフにオーバーレイされます。カテゴリフォームの凡例グループ を選択すると、 連続変数 のグループが凡例を形成し、 要約変数 で指定した列が X 軸を形成します。要約された変数は、凡例グループを形成する を選択すると、 要約変数 で指定した列が凡例を形成し、 連続変数 のグループが X 軸を形成します。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。
シンボルの表示
選択すると、X 軸上の各点に記号が表示されます。このオプションを選択しない場合、グラフには線のみが表示されます。
関数を合計のパーセントで表示
このオプションを選択すると、Y スケールのタイプがパーセントに変更されます。
パレート図
パレート図 を使用して、最も頻繁な欠陥、欠陥の最も一般的な原因、または顧客からの苦情の最も頻繁な原因を特定します。パレート図を使用すると、もっとも効果のある部分に改善努力を集中させることができます。
欠陥データまたは属性データ
生データまたはサマリーデータを含む列を入力します。生データの列が1つだけの場合は、その列を入力します。要約データがある場合は、欠陥の名前が含まれている列を入力します。
テキストデータを使用する場合は、確実に最初の15文字内で欠陥名が明確に区別されるようにします。
要約変数 (オプション)
サマリー・データのカウントを含む数値列を入力します。
この累積パーセント後に残った欠陥を結合します
Minitabでは、累積パーセントが指定するパーセントを上回るまで、欠陥カテゴリの棒を生成します。次に、残りの欠陥が「その他」ラベルのカテゴリに分類されます。
パーセントスケールと累積線を表示
このオプションを選択すると、累積パーセント シンボル、接続ライン、およびパーセント スケールが表示されます。
棒グラフ
バーチャートを使って、グループやカテゴリーを表すバーを使ってカウント、平均、その他の要約統計を比較できます。バーの高さは、グループのカウント関数または変数関数のいずれかを示します。
カテゴリ(分類)変数
グラフ化する数値列を 1 つ以上入力します。
要約変数 (オプション)
棒グラフの棒を定義する数値列またはテキスト列を入力します。
関数
関数から、要約変数の関数を選択します。たとえば、「 最大」を選択すると、各棒の集計変数の最大値に基づいて棒グラフの色が定義されます。要約変数にテキスト列を入力する場合、選択できるのは 指定した値と等しいパーセント、 非欠損値の数、または 欠損値の数のみです。
- パーセンタイル
- パーセンタイルを選択する場合は、パーセント値:に値を入力する必要があります。値は0~100の範囲で指定します。Minitabでは、入力した値を使用して、棒グラフの色のグラデーションが定義されます。たとえば、「50」と入力すると、50パーセンタイルを使用して、棒グラフの各長方形の色のグラデーションが定義されます。
- 2 つ値の間のパーセント
- 2 つ値の間のパーセントを選択した場合は、 最初の値 と 2 番目の値で数値を入力する必要があります。最初の値に入力する値は、2 番目の値に入力した値以下である必要があります。Minitabでは、2つの値の間にある観測値のパーセンテージに基づいて、棒グラフの色のグラデーションを定義します。
- 指定した値と等しいパーセント
- 指定した値と等しいパーセントを選択する場合は、値に1つ以上の値を入力する必要があります。値は、要約変数で入力した列と同じ種類のデータである必要があります。Minitabでは、入力した値と等しい観測値のパーセンテージに基づいて、棒グラフの色のグラデーションが定義されます。
オーバーレイ
複数のカテゴリ変数を選択し、グラフをオーバーレイすることを選択した場合は、オーバーレイされたバーの表示方法を選択できます。
- 均等に配置されたバーでオーバーレイ
- デフォルトでは、バーは軸に沿って均等に表示されます。カテゴリ グループは、 カテゴリ(分類)変数に表示される順序で軸に沿ってさまざまなレベルに表示されます。
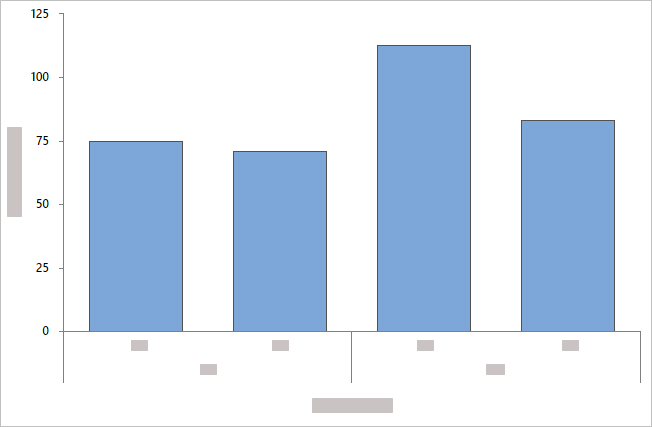
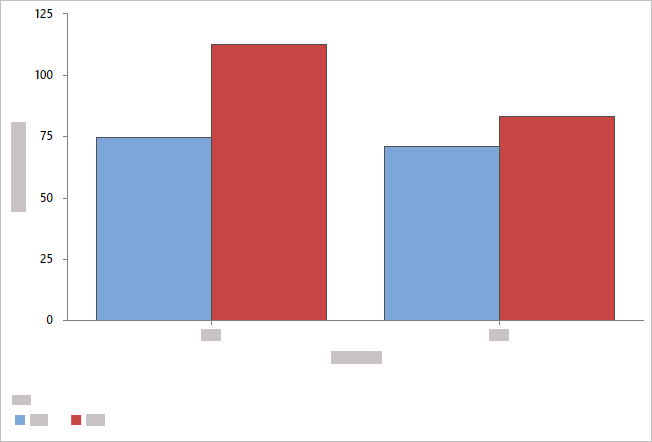
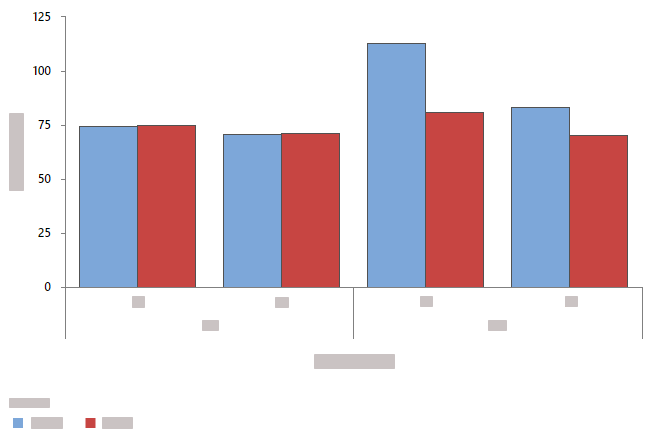
- クラスター化されたバーでオーバーレイ
- Minitabでは、カテゴリグループがクラスター化された棒として表示され、凡例が含まれます。カテゴリ(分類)変数内の変数を並べ替えてグループ化を変更したり、 クラスター分析-変数から別の変数を選択したりできます。
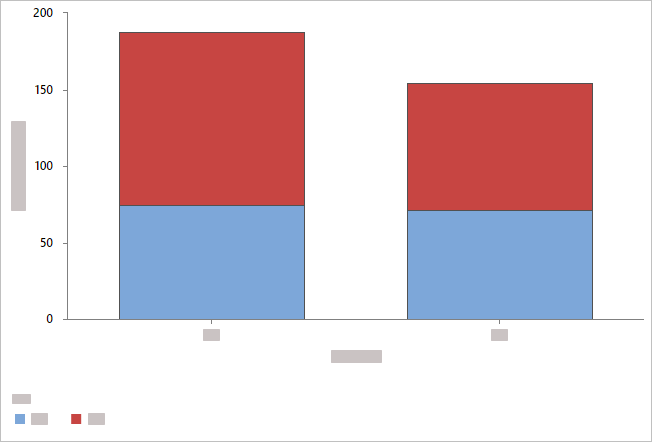
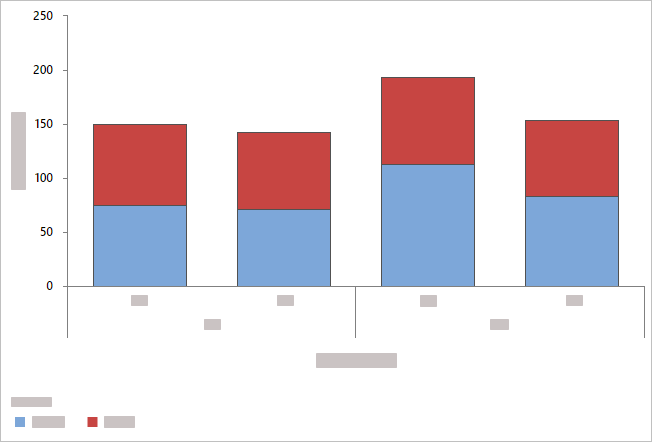
- 積み上げバーでオーバーレイ
- Minitabでは、カテゴリグループが積み上げ棒として表示され、凡例も表示されます。カテゴリが表示されるレベルを変更するには、 カテゴリ(分類)変数内の変数を並べ替えたり、 クラスター分析-変数から別の変数を選択したりできます。
注
集計された変数が複数あり、グラフをオーバーレイすることを選択した場合、集計された変数によってバーをクラスター化または積み上げるオプションがあります。
集計変数によるクラスター化
要約された変数による積み上げ
バーの順序
- デフォルト
- デフォルトでは、一意の値の度数または変数の関数をグラフ化すると、バーはカテゴリ名で昇順に並べられます(たとえば、次のようになります)。グループ1、グループ2、グループ3)。
- Yの昇順
- Y 値に基づいて昇順でバーを配置します。
- Yの降順
- バーを Y 値に基づいて降順で配置します。
合計のパーセントとしてカウントを表示
要約変数を入力しない場合は、このオプションを選択して、Yスケールタイプをカウントからパーセントに変更します。
関数を合計のパーセントで表示
要約変数を入力するときに、このオプションを選択して Y スケール タイプをパーセントに変更します。
同じYスケール
Yスケールを複数のグラフで同じにします。
変数の表示順序
Minitabでは、「一番内側」と「一番外側」という言葉を使用して、グラフに表示されるグループの複数の水準のスケールの相対位置を示します。水平スケールでは、一番外側はグラフの底面のスケールを指し、一番内側は底面から最も離れている(水平軸に最も近い)スケールを指します。垂直スケールでは、一番外側はグラフの一番左のスケールを指し、一番内側は垂直軸に最も近いスケールを指します。
- カテゴリ変数が最初に、Yの下
- グラフ変数は最も外側のグループで、カテゴリ変数は最も内側のグループです。
- Yの最初の、以下のカテゴリ変数
- グラフ変数は最も内側のグループで、カテゴリ変数は最も外側のグループです。
円グラフ
円グラフ を使用して、各カテゴリまたはグループのデータの割合を比較します。円グラフは、各カテゴリの観測値の割合を表すためにセグメント (「スライス」) に分割された円 (「円」) です。
カテゴリ(分類)変数
グラフ化するカテゴリデータの列を 1 つ以上入力します。
要約変数 (オプション)
グラフ化する集計値の列を 1 つ以上入力します。
ディスプレイの種類
- 円
-
- ドーナツ
- 半円
円分割の順序
- デフォルト
- カテゴリ(分類)変数のみを入力すると、スライスはアルファベット順に表示されます。要約変数も入力すると、ワークシートに カテゴリ(分類)変数 が表示されるのと同じ順序でスライスが表示されます。デフォルトの動作を変更するには、 カテゴリ(分類)変数の値の順序を設定します。テキスト列の値の順序を変更するには、Minitab出力でのテキスト値の表示順序の変更を参照してください。
- 面積の増加
- :分割を最小から最大に並べます。
- 面積の減少
- :分割を最大から最小に並べます。
このパーセント以下の分割を組み合わせる
個別のスライスの最小パーセンテージを入力します。このパーセントよりも小さいカテゴリは、Other(その他)という名前の分割にグループ化されます。
散布図
散布図を使用して、連続変数のペア間の関係を調査します。散布図では、座標平面のX変数とY変数のペアを順番通りに表示します。
変数
x変数とy変数を個々のペアとしてグラフ化することも、x-y変数のすべての組み合わせをグラフ化することもできます。y変数は、説明または予測する変数です。x 変数は、y 変数の変化を説明または予測する可能性のある対応する変数です。すべての列は数値で、各X-Y変数のペアは行数が同じでなければなりません。
まず、次のいずれかのオプションを選択します。
- 各Y対各X
- 選択すると、入力する x 変数と y 変数の可能な組み合わせごとに個別のグラフが表示されます。
- XYペア
- 選択すると、入力する x 変数と y 変数のペアごとに個別のグラフが表示されます。各 x-y 変数ペアは、同じ行数を持つ必要があります。
次に、変数を入力します。
- Y変数
- 説明または予測する変数を選択します。
- X変数
- Y 変数の変化を説明または予測する可能性のある変数を選択します。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。
ログ変換
- ログ変換: Y スケール
- 対数底10を使用してYスケールを変換する場合に選択します。
- ログ変換: X スケール
- Xスケールを対数10で変換する場合に選択します。
ビン分割散布図
ビン化散布図を使用して、データセットに多数の観測値が含まれている場合に、連続変数のペア間の関係を調査します。
変数
y変数は、説明または予測する変数です。x 変数は、y 変数の変化を説明または予測する可能性のある対応する変数です。すべての列は数値で、各X-Y変数のペアは行数が同じでなければなりません。
- Y変数
- 説明または予測する変数を選択します。
- X変数
- Y 変数の変化を説明または予測する可能性のある変数を選択します。
平均で定義されたグラデーション
3番目の変数の値でグラデーションスケールを定義する場合に選択します。
グラデーションの種類
ビンのカラースケールを選択します。
- 発散
- 値が高いビンは赤色で、値が低いビンは青色です。[ 値の周りのグラデーション対称] に値を入力して、勾配スケールをビン化データの周波数の中心ではなく、特定の値に中心にします。
-

- 低から高に順次
- 値が高いビンは濃い青、低いビンはライトブルーとライトグレーです。このオプションを使用すると、生産性の高いビンを強調表示したり、収益を最大化することができます。

- 高から低に順次
- 値の低いビンは濃い青、高い値のビンは薄青と淡い灰色です。このオプションを使用して、欠陥率の低いビンを強調表示したり、コストを最小限に抑えたりすることができます。

ログ変換
- ログ変換: Y スケール
- 対数底10を使用してYスケールを変換する場合に選択します。
- ログ変換: X スケール
- Xスケールを対数10で変換する場合に選択します。
バブルプロット
バブルプロットを使用して、各シンボルまたはバブルのサイズが3番目の変数のサイズを表す2つの変数間の関係を調べます。
変数
y変数は、説明または予測する変数です。x 変数は、y 変数の変化を説明または予測する可能性のある対応する変数です。すべての列は数値で、各X-Y変数のペアは行数が同じでなければなりません。
- Y変数
- 説明または予測する変数を選択します。
- X変数
- Y 変数の変化を説明または予測する可能性のある変数を選択します。
バブルサイズ
バブルのサイズ (面積) を決定する列を入力します。
レイアウト
レイアウトオプションを選択します。
- 各 XY ペアのグラフを分けて表示する
- XYペアごとに個別の散布図を作成します。
- オーバーレイ XY ペア
- 各XYペアは、1つの散布図にオーバーレイされます。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。
ログ変換
- ログ変換: Y スケール
- 対数底10を使用してYスケールを変換する場合に選択します。
- ログ変換: X スケール
- Xスケールを対数10で変換する場合に選択します。
行列散布図
行列散布図を使用して、複数の変数ペアの関連性を一度に評価します。行列散布図とは、散布図の配列です。変数の可能な組み合わせごとに 1 つのプロットを作成する プロットの行列 を選択できます。または、「 各 Y 対各 X 」を選択して、可能な xy の組み合わせごとにプロットを作成することもできます。
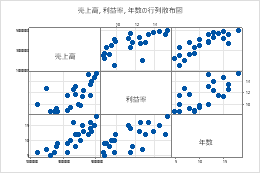
プロット行列
連続変数に、同じ行数の数値データの列を入力します。Minitabは、変数の組み合わせごとに散布図を表示します。
このワークシートでは、 収益率、 売上高、 および年が グラフ変数です。グラフは、グラフ変数の可能な各組み合わせ間の関係を示します。
| C1 | C2 | C3 |
|---|---|---|
| 収益率 | セールス | 月日 |
| 15.4 | 50400200 | 18 |
| 11.3 | 42100650 | 15 |
| 9.9 | 39440420 | 12 |
| ... | ... | ... |
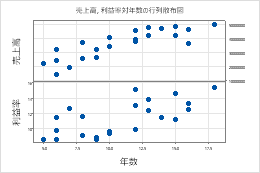
各Y対各X
Y変数に、説明または予測する数値データの列を入力します。「 X変数」に、Y 変数の変更を説明する可能性のある数値データの列を入力します。
このワークシートでは、 収益率 と 売上高 がY変数で、 年 がX変数です。グラフには、Y変数とX変数ごとの関係が表示されます。
| C1 | C2 | C3 |
|---|---|---|
| 収益率 | セールス | 月日 |
| 15.4 | 50400200 | 18 |
| 11.3 | 42100650 | 15 |
| 9.9 | 39440420 | 12 |
| ... | ... | ... |
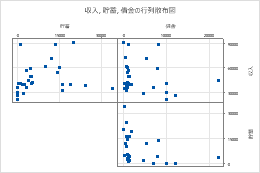
レイアウト
完全なマトリックス を選択すると、マトリックスの左下部分と右上部分の両方が表示されます。2 つの部分には、軸が逆の同じデータが表示されます。たとえば、行列の左下の x 軸に表示される変数は、右上の部分の y 軸に表示されます。
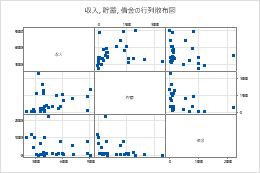
完全なマトリックス
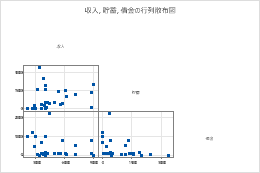
左下
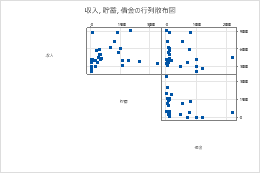
右上
グループ変数
グループを定義する変数を入力します。グループは、異なる色と記号で表されます。たとえば、次の行列プロットは、 変数「収益率」、「 売上 」、 および「年」の各可能な組み合わせ間の関係を3つのグループに分けて示しています。
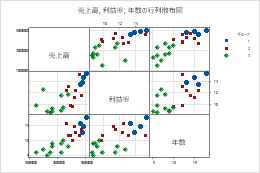
変数ラベル配置
対角
境界
尺度
複数のグラフで同じスケールを使用します。
- 同じYスケール
- すべてのグラフで同じYスケールを使用します。
- 同じXスケール
- すべてのグラフで同じXスケールを使用します。
コレログラム
コレログラム を使用して、変数のペア間の線形関係 (相関) の強度と方向を視覚化し、比較します。
連続変数
データを含む列を入力します。数値データを少なくとも2列含める必要があります。各列の行数は同じでなければなりません。
グラデーションの種類
ビンのカラースケールを選択します。
- 自動
- 自動を選択すると、グラデーションのタイプはピアソン相関係数の計算に依存します。
- 係数が正と負の場合、グラデーションの種類は0を中心に対称に発散です。
- 係数がすべて正の場合、グラデーションの種類は低から高に順次です。
- 係数がすべて負の場合、グラデーションの種類は高から低に順次です。
- 発散
- 値が高いビンは赤色で、値が低いビンは青色です。[ 値の周りのグラデーション対称] に値を入力して、勾配スケールをビン化データの周波数の中心ではなく、特定の値に中心にします。
-
- 低から高に順次
- 値が高いビンは濃い青、低いビンはライトブルーとライトグレーです。このオプションを使用すると、生産性の高いビンを強調表示したり、収益を最大化することができます。
- 高から低に順次
- 値の低いビンは濃い青、高い値のビンは薄青と淡い灰色です。このオプションを使用して、欠陥率の低いビンを強調表示したり、コストを最小限に抑えたりすることができます。
相関値の表示
グラフの長方形内に各ピアソン相関係数の値を表示する場合に選択します。
平行座標プロット
平行座標プロットを使用して、複数の変数の平行座標で多数の系列または系列のグループを視覚的に比較します。
変数
少なくとも 2 列の数値データを入力します。
行ラベル
各系列のラベルを含む列を入力します。Minitabでは、カーソルを使用してプロットにカーソルを合わせると、この列を使用してプロットに系列のラベルを付けます。グループ変数を入力しない場合Minitabではラベル列を使用して、平行プロットの説明文を作成します。
レイアウト
次のいずれかのレイアウトオプションを選択します。
- 個人シリーズ
- ワークシート内のすべての行の系列を表示する平行プロットを作成します。ワークシートには、数値データを少なくとも2列含める必要があります。
- グループ別の個別シリーズ
- ワークシート内のすべての行の系列を表示し、グループ化変数の各レベルに同じ色を使用する平行プロットを作成します。ワークシートには、少なくとも2つの数値データ列と、グループを含む列が1つ含まれている必要があります。
- 要約グループ
- ワークシート内のすべての行ではなく、各グループの各シリーズの平均を表示する平行プロットを作成します。ワークシートには、少なくとも2つの数値データ列と、グループを含む列が1つ含まれている必要があります。
グループ変数
グループを定義する変数を入力します。グループラベルはグラフの凡例に表示されます。グループ別の個別シリーズまたは要約グループを選択する場合は、列を入力する必要があります。
Yスケール
Y スケールの表示方法を選択します。
- 範囲のパーセント
-
選択すると、各変数が一意のYスケールでプロットされます。各変数の最小値または最大値をすべて含むシリーズは、水平になります
線。
- 標準単位
-
選択すると、各変数が一意のYスケールでプロットされます。各スケールの最小値と最大値は、各変数のスケールに変換された入力したすべてのデータのZスコアの合計値と最大スコア値です。
たとえば、最初の変数の最大値はZスコアが2で、他の2つの変数の最大値はzスコアが1です。各変数のyスケールの最大値は、zスコア2に対応する値です。
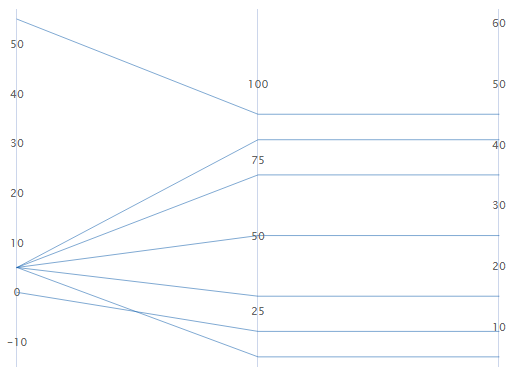
- 元のデータ
-
各変数に対して繰り返される1つのYスケールを選択して使用します。スケールの最小値と最大値は、入力したすべてのデータの合計最小値と最大値です。
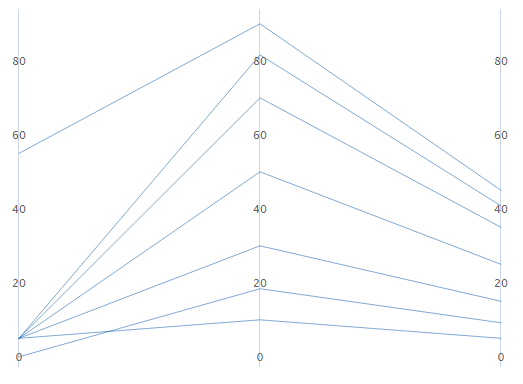
ラインの最大変動から最小変動の順で変数を並べ替える
標準単位または元のデータを選択すると、変動に基づいて変数を並べ替えることができます。これは、多くの変数があり、どれが最も系列を分離しているかを確認する場合に便利です。このオプションを選択しない場合、変数ダイアログボックスに入力した列と同じ順序で列が並べ替えされます。
並べ替えなし
並べ替え
ヒートマップ
ヒートマップ を使用して、平均値やその他の要約統計量を色のグラデーションで比較し、異なるグループの影響を表します。
カテゴリ行変数
カテゴリがヒートマップ上の行として表される列を最大 5 つ入力します。
カテゴリー列変数
カテゴリがヒートマップ上の列として表される列を最大 5 つ入力します。
要約変数 (オプション)
ヒートマップ内の長方形の色のグラデーションを定義する数値列またはテキスト列を入力します。複数の列を入力すると、入力する変数ごとに個別のヒートマップが生成されます。
関数
関数から、要約変数の関数を選択します。たとえば、 最大を選択すると、各長方形の要約変数の最大値に基づいて、ヒートマップの色のグラデーションが定義されます。要約変数にテキスト列を入力する場合、選択できるのは 指定した値と等しいパーセント、 非欠損値の数、または 欠損値の数のみです。
- パーセンタイル
- パーセンタイルを選択する場合は、パーセント値:に値を入力する必要があります。値は0~100の範囲で指定します。Minitabでは入力した値を使用して、ヒートマップのカラーグラデーションを定義します。たとえば、50と入力すると、50番目の百分位数が使用され、ヒートマップの各長方形のカラーグラデーションが定義されます。
- 2 つ値の間のパーセント
- 2 つ値の間のパーセントを選択した場合は、 最初の値 と 2 番目の値で数値を入力する必要があります。最初の値に入力する値は、2 番目の値に入力した値以下である必要があります。Minitabでは、2つの値の間にある観測値のパーセンテージに基づいて、ヒートマップのカラーグラデーションを定義します。
- 指定した値と等しいパーセント
- 指定した値と等しいパーセントを選択する場合は、値に1つ以上の値を入力する必要があります。値は、要約変数で入力した列と同じ種類のデータである必要があります。Minitabでは、入力する値に等しい観測値のパーセンテージに基づいて、ヒートマップのカラーグラデーションを定義します。
グラデーションの種類
- 発散
- 値が高いビンは赤色で、値が低いビンは青色です。[ 値の周りのグラデーション対称] に値を入力して、勾配スケールをビン化データの周波数の中心ではなく、特定の値に中心にします。
-
- 低から高に順次
- 値が高いビンは濃い青、低いビンはライトブルーとライトグレーです。このオプションを使用すると、生産性の高いビンを強調表示したり、収益を最大化することができます。
- 高から低に順次
- 値の低いビンは濃い青、高い値のビンは薄青と淡い灰色です。このオプションを使用して、欠陥率の低いビンを強調表示したり、コストを最小限に抑えたりすることができます。
ウエハープロット
ウエハープロット を使用して平均やその他の要約統計量を比較するには、応答変数の変化を表す色のグラデーションを使用します。データの考慮事項、例、解釈については、 ウェハープロットの概要をご覧ください。
Y座標
ウェーハプロットのy軸を表すデータを含む数値列を入力します。
X座標
ウェーハプロットのx軸を表すデータを含む数値列を入力します。
応答変数
ウェーハプロットの長方形の色のグラデーションを定義する数値列を入力します。関数から、応答変数の関数を選択します。たとえば、「 最大」を選択した場合、Minitabでは、各長方形の応答変数の最大値に基づいて、ウェーハプロットの色のグラデーションが定義されます。
- パーセンタイル
- パーセンタイルを選択する場合は、パーセント値:に値を入力する必要があります。値は0~100の範囲で指定します。Minitabでは、入力した値を使用して、ウェーハプロットの色のグラデーションが定義されます。たとえば、「50」と入力すると、50パーセンタイルを使用して、ウェーハプロットの各長方形の色のグラデーションが定義されます。
- 2 つ値の間のパーセント
- 2 つ値の間のパーセントを選択した場合は、 最初の値 と 2 番目の値で数値を入力する必要があります。最初の値に入力する値は、2 番目の値に入力した値以下である必要があります。Minitabでは、2つの値の間にある観測値のパーセンテージに基づいて、ウェーハプロットの色のグラデーションを定義します。
- 指定した値と等しいパーセント
- 指定した値と等しいパーセントを選択する場合は、値に1つ以上の値を入力する必要があります。値は、応答変数で入力した列と同じ種類のデータである必要があります。Minitabでは、入力した値と等しい観測値のパーセンテージに基づいて、ウェーハプロットの色のグラデーションを定義します。
グループ変数
グループ変数 にグループ化変数を入力して、グループ化変数の水準ごとに個別のウェーハプロットを作成します。入力する列は、 X座標 と Y座標の列と同じ長さにする必要があります。
グラデーションの種類
- 発散
- 値が高い長方形は赤色で、値が低い長方形は青色です。値の周りのグラデーション対称に値を入力して、グラデーションスケールを選択した関数の中心ではなく、特定の値の中央に配置します。たとえば、事業主は、複数の店舗にまたがる複数の製品の利益の平均によって定義されるグラデーションを選択します。所有者は 値の周りのグラデーション対称 として 0 を入力すると、利益を上げた製品の長方形は、損失を出した長方形とは異なる色になります。
-
- 低から高に順次
- 値が高い長方形は濃い青色、低値の長方形は薄い青と淡い灰色です。このオプションを使用すると、生産性の高い長方形を強調表示したり、収益を最大化することができます。
- 高から低に順次
- 値の低い長方形は濃い青色、値が高い長方形は薄い青と薄い灰色です。このオプションを使用して、欠陥率の低い長方形を強調表示したり、コストを最小限に抑えたりすることができます。
- さまざまな色のグラデーション
- 5種類の別カラーグラデーションから選ぶことができます。

勾配範囲
注
関数に 2 つ値の間のパーセント または 指定した値と等しいパーセント を指定した場合、ウェーハ プロットでは勾配にパーセンテージ スケールが使用されます。このような場合、 最小 と 最大 に入力する値は 0 から 1 の間である必要があります。
集計統計量
集計統計量 は、1 つ以上のカテゴリ変数によって分類されたデータがある場合に使用します。2つ以上のカテゴリー変数にわたるカテゴリーの組み合わせについて、さまざまな統計量を決定できます。
変数
- カテゴリ行変数に、テーブルの行を定義するカテゴリを含む最大 3 つの列を入力します。
- カテゴリー列変数に、テーブルの列を定義するカテゴリを含む列を 2 つまで入力します。
-
要約変数 (オプション) に、集計する関連変数を含む列を入力します。関連変数とはカテゴリ変数によってグループ化される連続変数です。
デフォルトでは、平均はテーブルに表示される唯一の統計量です。追加の統計を表示するには、変数名の横にあるドロップダウンから 要約統計量 を選択します。一部の統計では、追加の値を入力する必要があります。- パーセンタイル
- パーセント値:に 0 から 100 までの値を入力します。たとえば、「50」と入力すると、50番目の百分位数が表示されます。
- 2 つ値の間のパーセント
- 数値は 最初の値 と 2 番目の値で入力する必要があります。最初の値 は 2 番目の値以下である必要があります。Minitabでは、2つの値と等しい、または2つの値の間にある観測値のパーセントが表示されます。これには、2 つの値に等しい観測値が含まれます。
- 指定した値と等しいパーセント
- 値に、 要約変数に入力した列と同じタイプのデータである 1 つ以上の値を入力します。Minitabでは、入力した値と等しい観測値のパーセントが表示されます。
テーブル・レイアウトに関する詳細は、 出力テーブルの配置を参照してください。
| C1 | C2 | C3 |
|---|---|---|
| 強度 | 機械 | 作業者 |
| 38 | 1 | 1 |
| 40 | 2 | 2 |
| 63 | 3 | 3 |
| 59 | 4 | 1 |
| 76 | 1 | 2 |
| ... | ... | ... |
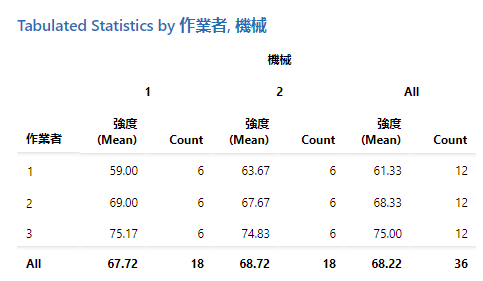
カテゴリ変数の要約統計量
- 計数
- それぞれの行と列の変数の組み合わせで観測度数を表示します。
- 行パーセント
- 各セルが表の行の観測値の合計に占める百分率を表示します。
- 列パーセント
- 各セルが表の列の観測値の合計に占める百分率を表示します。
- 総パーセント
- 各セルが表のすべての観測値に占める百分率を表示します。
表示オプション
- 周辺統計量を表示する
- 周辺統計を表示する場合に選択します。周辺統計は、合計など、テーブルの行と列に関する情報を提供します。
- 欠損値を表示する
- 欠損値を表示する場合に選択します。Minitabでは、欠損データを含めない限り、欠損変数のあるすべての行が除外されます。欠損値を計算に含めるには、[ 表示された欠損値を計算に含む ] を選択します。詳細は、 テーブル内の欠損値を解釈する方法を参照してください。
時系列プロット
時系列プロットを使用して、トレンドや季節要因パターンなどの時系列データのパターンを調べます。
連続変数
グラフ化する時系列数値データの 1 つ以上の列を入力します。
タイムスケールラベル (オプション)
X 軸に、スケールの日付/時刻、数値、またはテキスト値を含む列の値をラベル付けします。たとえば、次の時系列プロットでは、列にシフトと日を指定します。
| C1-T |
|---|
| シフトと日 |
| S1D1 |
| S2D1 |
| S3D1 |
| ... |
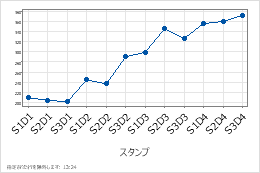
レイアウト
次のレイアウト オプションを設定します。
- パネル連続変数
- 連続変数 入力フィールドの列は、すべての変数が 1 つの X 軸を共有し、各連続変数がそれぞれのパネルに表示される 1 つの時系列プロットに表示されます。
- 連続変数のオーバーレイ
- 連続変数 入力フィールドの列は、1 つの時系列プロットにオーバーレイされます。
Yスケール
Y スケールの表示方法を選択します。
- 元のデータ
- 各変数に対して繰り返される1つのYスケールを選択して使用します。スケールの最小値と最大値は、入力したすべてのデータの合計最小値と最大値です。
- 範囲のパーセント
- 選択すると、各変数が一意のYスケールでプロットされます。各変数の最小値または最大値をすべて含む系列は、水平線になります。
- ログスケール
- 同じ距離がスケール全体の異なる値の変化を表すため、対数スケールは軸を変えることで対数関係を直線化します。このオプションは、ポジティブデータでのみ使用できます。
積み上げ領域グラフ
積み上げ領域グラフ を使用して、グループの累積合計を時間順にプロットし、各グループが全体にどのように寄与しているかを評価します。面グラフでは、各シェーディングされた領域は、その変数とその下の変数の累積合計を表します。たとえば、次の面グラフは、2 年間で 3 店舗での主要小売チェーンの月次売上を示しています。1月の3つのグループの売上は約1000でした。
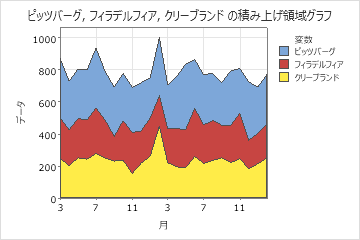
連続変数
グラフ化する時系列数値データの 1 つ以上の列を入力します。
タイムスケールラベル (オプション)
X 軸に、スケールの日付/時刻、数値、またはテキスト値を含む列の値をラベル付けします。たとえば、次の時系列プロットでは、列にシフトと日を指定します。
| C1-T |
|---|
| シフトと日 |
| S1D1 |
| S2D1 |
| S3D1 |
| ... |
積み上げ順序
グラフを作成するときに、変数が積み重なっている順序を変更できます。
- エントリの順序(最初が先頭)
- 変数をダイアログボックスに入力した順序で積み重ねられます。最初に入力した変数は上部にあり、2 番目の変数は最初の変数の下に置かれます。
- 変動の程度(最大が先頭)
- 変数を変動の度合いによって積み重ねる。最大変動の変数が上部にあり、2 番目に大きいバリエーションを持つ変数が最初の変数の下に置かれます。
ログ変換: Y スケール
対数底10を使用してYスケールを変換する場合に選択します。同じ距離がスケール全体の異なる値の変化を表すため、対数スケールは軸を変えることで対数関係を直線化します。これらのオプションは、正のデータに対してのみ使用できます。
KPI
- あなたのデータを含む データ接続 を選択してください。
- 変数では、 KPI 測度を指定します。
- 平均、和、最大などの 関数を選びます。
- タイトルは任意で変更可能です。
また、ダッシュボード上の KPI の表示方法を変更するための他のオプションもカスタマイズ可能です。 自動 ボタンを切り切り、変数のフォーマットを自分で指定してください。
値の書式設定
- カスタム小数点位置
- 変数の小数点以下数を指定します。小数点以下の桁数は最大12桁です。
- 規模とレイアウト
- 変数のサイズとアラインメントを指定します。
- タイトルポジション
- 変数の上または下にタイトルを表示するように指定してください。
- テキストの色
- 変数の色と不透明度を指定します。不透明度は0から100までの任意の数でいられます。数値が低いほど変数はより透明になります。
条件付き書式
- 条件付き書式 タブを選択します。
- 追加を選択します。
- 演算子で条件を明記してください。例えば、KPIの値がある値 より大きい ときにフォーマットを適用したい場合などです。
- ここで数値 値が登場します。
- 条件付きテキスト (任意)では、変数が条件を満たすと表示するテキストを タイトル の横に表示します。
- 条件付きテキストカラーでは、条件を満たす変数の色と不透明度を指定します。不透明度は0から100までの任意の数でいられます。数値が低いほど変数はより透明になります。
複数の条件を追加できます。KPI変数が複数の条件を満たす場合、ダッシュボードはリストの最も下位の条件を適用します。省略記号は選択できます![]() リスト上の条件を上下に移動させるために。
リスト上の条件を上下に移動させるために。
テーブル
- タイトルの変更または抑制
- 表示する特定の列を選択します
- 最初の列に行カウンターを追加します
- テキストカラムのラップ
ヘッダーセルの端をドラッグすると、列幅を調整できます。

降順を示します
