Sur ce thème
α (alpha)
Le seuil de signification (dénoté par alpha ou α) est le niveau maximal acceptable du risque de rejet de l'hypothèse nulle lorsqu'elle est vraie (erreur de type I). Alpha correspond également à la valeur de puissance du test lorsque l'hypothèse nulle (H0) est vraie. En général, vous choisissez le seuil de signification avant d'analyser les données. Le seuil de signification par défaut est 0,05.
Interprétation
Le seuil de signification permet de minimiser la valeur de puissance du test lorsque l'hypothèse nulle (H0) est vraie. Des valeurs plus élevées du seuil de signification donnent au test davantage de puissance, mais augmentent également les chances de faire une erreur de type I, c'est-à-dire de rejeter à tort l'hypothèse nulle alors qu'elle est vraie.
Longueur d'observation
La longueur d'observation représente l'ampleur, la durée ou la taille de chaque période d'observation.
Interprétation
Elle vous permet d'exprimer le taux d'occurrence de la façon la mieux adaptée à votre situation.
Par exemple, si chaque observation d'un échantillon compte le nombre d'événements survenant dans une année, une longueur de 1 représenterait un taux d'occurrence annuel, alors qu'une longueur de 12 représenterait un taux d'occurrence mensuel.
- Pour la ligne d'assemblage A, le nombre total d'occurrences est de 112, car ils ont relevé 112 défauts. Il est de 132 pour la ligne d'assemblage B car ils ont relevé 132 défauts.
- L'effectif de l'échantillon (N) est de 50 pour les deux lignes d'assemblage car ils ont collecté des échantillons dans 50 paquets de chacune des deux lignes.
- Pour déterminer le nombre de défauts par serviette, les inspecteurs utilisent une longueur d'observation de 10 pour la ligne d'assemblage A car un paquet contient 10 serviettes. La longueur d'observation est de 15 pour la ligne d'assemblage B.
- Pour la ligne d'assemblage A, le taux d'occurrence est égal à : (nombre total d'occurrences / N) / (longueur d'observation) = (112/50) / 10 = 0,224. Pour la ligne d'assemblage B, il est égal à : (132/50) / 15 = 0,176. Ainsi, chaque serviette comporte en moyenne 0,244 défaut pour la ligne d'assemblage A et 0,176 défaut pour la ligne d'assemblage B.
- Comme les inspecteurs entrent une longueur d'observation autre que 1, Minitab calcule également le nombre moyen d'occurrences. Pour la ligne d'assemblage A, le nombre moyen d'occurrences est égal à : (nombre total d'occurrences/N) = 112/50 = 2,24. Pour la ligne d'assemblage B, le nombre moyen d'occurrences est égal à : 132/50 = 2,64. En d'autres termes, le nombre moyen d'occurrences décrit le nombre moyen de défauts par paquet. Toutefois, comme les paquets ne contiennent pas tous le même nombre de serviettes, le taux d'occurrence est plus utile.
Taux de comparaison
Le taux de comparaison désigne la valeur à comparer au taux de référence.
Interprétation
Minitab calcule le taux de comparaison. La différence entre le taux de comparaison et le taux de référence est la différence minimale pour laquelle vous pouvez atteindre le niveau de puissance indiqué pour chaque effectif de l'échantillon. Des effectifs d'échantillons plus grands permettent au test de détecter de plus petites différences. Vous voulez détecter la plus petite différence ayant des conséquences pratiques pour votre application.
Pour examiner plus en détail la relation entre l'effectif de l'échantillon et le taux de comparaison à une puissance donnée, utilisez la courbe de puissance.
Effectif échantillon
L'effectif de l'échantillon correspond au nombre total d'observations dans l'échantillon.
Interprétation
Utilisez l'effectif de l'échantillon pour déterminer le nombre d'observations nécessaires pour obtenir une certaine valeur de puissance pour le test d'hypothèse à une différence spécifique.
Minitab calcule l'effectif d'échantillon nécessaire pour un test avec la puissance que vous avez saisie pour détecter la différence entre le taux de référence et le taux de comparaison. Etant donné que les effectifs d'échantillons sont des nombres entiers, la puissance réelle du test peut être légèrement supérieure à la valeur de puissance que vous avez indiquée.
Si vous augmentez l'effectif de l'échantillon, la puissance du test augmente également. L'échantillon doit contenir suffisamment d'observations pour atteindre une puissance adéquate. Toutefois, si l'effectif de l'échantillon est trop grand, vous risquez de gaspiller du temps et de l'argent sur un échantillonnage inutile ou de détecter des différences non significatives sur le plan statistique.
Pour examiner plus en détail la relation entre l'effectif de l'échantillon et la différence à une puissance donnée, utilisez la courbe de puissance.
Puissance
La puissance d'un test d'hypothèse est la probabilité du test de rejeter l'hypothèse nulle à raison. Elle est affectée par l'effectif de l'échantillon, la différence, la variabilité des données et le seuil de signification du test.
Pour plus d'informations, reportez-vous à la rubrique Qu'est-ce que la puissance ?.
Interprétation
Minitab calcule la puissance du test en fonction de l'effectif d'échantillon et du taux de comparaison spécifiés. La valeur de puissance 0,9 est généralement appropriée. Une valeur de 0,9 indique que vous avez 90 % de chances de détecter une différence entre les taux des populations lorsqu'elle existe réellement. Si un test a une faible puissance, vous pouvez ne pas réussir à détecter une différence et conclure à tort qu'il n'en existe aucune. En général, plus la différence ou l'effectif d'échantillon est faible, moins le test est puissant pour détecter une différence.
Si vous indiquez un taux de comparaison et une valeur de puissance pour le test, Minitab calcule l'effectif d'échantillon nécessaire. Minitab calcule également la puissance réelle du test pour cet effectif d'échantillon. Etant donné que les effectifs d'échantillons sont des nombres entiers, la puissance réelle du test peut être légèrement supérieure à la valeur de puissance que vous avez indiquée.
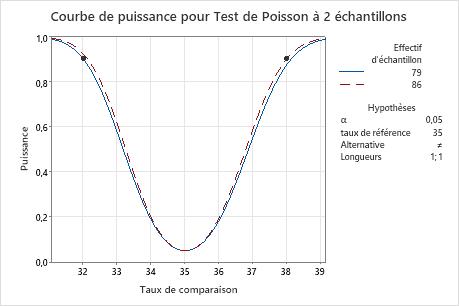
Courbe de la puissance
La courbe de puissance trace la puissance du test en fonction du taux de comparaison.
Interprétation
La courbe de puissance vous permet d'évaluer la puissance ou l'effectif d'échantillon adapté pour le test.
La courbe de puissance représente toutes les combinaisons de puissance et de taux de comparaison pour chaque effectif de l'échantillon lorsque le seuil de signification reste constant. Chaque symbole sur la courbe de puissance représente une valeur calculée en fonction des valeurs saisies. Par exemple, si vous entrez un effectif d'échantillon et une valeur de puissance, Minitab calcule la proportion de comparaison correspondante et affiche la valeur calculée sur le graphique.
Examinez les valeurs sur la courbe pour déterminer la différence entre le taux de comparaison et le taux de référence, pouvant être détectée à une valeur de puissance et un effectif d'échantillon spécifiques. La valeur de puissance 0,9 est généralement appropriée. Toutefois, certains spécialistes considèrent que la valeur 0,8 est adéquate. Si un test d'hypothèse offre une puissance inférieure, il se peut que vous ne puissiez pas détecter une différence significative sur le plan pratique. Si vous augmentez l'effectif de l'échantillon, la puissance du test augmente également. L'échantillon doit contenir suffisamment d'observations pour atteindre une puissance adéquate. Toutefois, si l'effectif de l'échantillon est trop grand, vous risquez de gaspiller du temps et de l'argent sur un échantillonnage inutile ou de détecter des différences non significatives sur le plan statistique. Lorsque vous réduisez la taille de la différence à détecter, la puissance diminue également.
Dans ce graphique, la courbe de puissance montre que pour détecter un taux de comparaison de 32 avec une puissance de 0,9, l'effectif de l'échantillon doit être 79. Pour détecter un taux de comparaison de 38 avec une puissance de 0,9, l'effectif de l'échantillon doit être 86. Lorsque le taux de comparaison se rapproche du taux de référence (35, dans ce graphique), la puissance du test diminue et se rapproche de α (également appelé seuil de signification), qui est de 0,05 pour cette analyse.