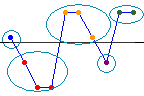
Suivez les étapes ci-dessous pour interpréter un test des suites. Les principaux résultats affichés sont le nombre de suites observé, le nombre de suites attendu et la valeur de p.
Etape 1 : Examiner la différence entre le nombre de suites observé et le nombre de suites attendu
Le nombre de suites observé est le nombre d'observations se trouvant au-dessous ou en dessous du critère de comparaison, K. La ligne représente K. Cet exemple comporte cinq suites.
Si le nombre de suites observé est sensiblement supérieur ou inférieur au nombre de suites attendu, les données ne suivent sans doute pas un ordre aléatoire. Pour déterminer si l'ordre des données est aléatoire, comparez la valeur de p au seuil de signification.
Test
Hypothèse nulle
H₀ : L'ordre des données est aléatoire
Hypothèse alternative
H₁ : L'ordre des données n'est pas aléatoire
Nombre d'essais
Observé
Attendu
Valeur de P
17
16,77
0,930
Résultats principaux : nombre de suites observé, nombre de suites attendu
Dans ces résultats, le nombre de suites observé est très proche du nombre de suites attendu
Etape 2 : Déterminer si l'ordre des données est aléatoire
Pour déterminer si l'ordre des données est aléatoire, comparez la valeur de p au seuil de signification. En général, un seuil de signification (noté alpha ou α) de 0,05 fonctionne bien. Un seuil de signification de 0,05 indique qu'il existe 5 % de risque de conclure que vos données ne sont pas aléatoires alors qu'elles le sont.
Valeur de p ≤ α : l'ordre des données n'est pas aléatoire (rejetez H0)
Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez rejeter l'hypothèse nulle et en conclure que l'ordre des données n'est pas aléatoire.
Valeur de p > α : il est impossible de conclure que l'ordre des données n'est pas aléatoire (impossible de rejeter H0)
Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas rejeter l'hypothèse nulle. Vous ne disposez pas de suffisamment de preuves pour conclure que l'ordre des données n'est pas aléatoire.
Test
Hypothèse nulle
H₀ : L'ordre des données est aléatoire
Hypothèse alternative
H₁ : L'ordre des données n'est pas aléatoire
Nombre d'essais
Observé
Attendu
Valeur de P
17
16,77
0,930
Résultat principal : valeur de p
Dans ces résultats, l'hypothèse nulle veut que l'ordre des données soit aléatoires. La valeur de p étant de 0,93, ce qui est supérieur au seuil de signification de 0,05, vous ne pouvez pas rejeter l'hypothèse nulle. Vous ne disposez pas de suffisamment de preuves pour conclure que l'ordre des données n'est pas aléatoire.