Sur ce thème
N
L'effectif de l'échantillon (N) est le nombre d'observations total de l'échantillon. L'effectif d'échantillon a un effet sur le nombre de suites attendus et la valeur de p.
K
K est la valeur du critère de comparaison. Par défaut, K est la moyenne des données de l'échantillon. Cependant, vous pouvez également définir une autre valeur, comme la médiane. Minitab utilise K pour calculer le nombre de suites observé.
≤ K et > K
Le nombre d'observations supérieures à K est le nombre de valeurs supérieures à celle du critère de comparaison, qui est la moyenne par défaut. Le nombre d'observations inférieures à K est le nombre de valeurs inférieures ou égales à celle du critère de comparaison. Minitab utilise ces valeurs pour calculer la valeur de p.
Hypothèse nulle et hypothèse alternative
- Hypothèse nulle
- L'ordre des données est aléatoire.
- Hypothèse alternative
- L'ordre des données n'est pas aléatoire.
Nombre de suites observé et nombre de suites attendu
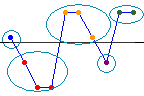
Le nombre de suites attendu est la moyenne de la distribution d'échantillonnage des suites dans une série aléatoire. Si le nombre d'essais observés est considérablement supérieur ou inférieur au nombre d'essais attendus, il est probable que les données ne soient pas dans un ordre aléatoire. Pour déterminer si l'ordre des données est aléatoire, comparez la valeur de p au seuil de signification.
Valeur de p
La valeur de p est la probabilité qui mesure le degré de certitude avec lequel il est possible d'invalider l'hypothèse nulle. Des probabilités faibles permettent d'invalider l'hypothèse nulle avec plus de certitude.
Interprétation
Vous pouvez utiliser la valeur de p pour déterminer si l'ordre des données est aléatoire.
- Valeur de p ≤ α : l'ordre des données n'est pas aléatoire (rejetez H0)
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez rejeter l'hypothèse nulle et en conclure que l'ordre des données n'est pas aléatoire.
- Valeur de p > α : il est impossible de conclure que l'ordre des données n'est pas aléatoire (impossible de rejeter H0)
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas rejeter l'hypothèse nulle. Vous ne disposez pas de suffisamment de preuves pour conclure que l'ordre des données n'est pas aléatoire.