Sur ce thème
Etape 1 : déterminer si la moyenne de la population et la cible sont équivalentes
Comparez l'intervalle de confiance aux limites d'équivalence. Si l'intervalle de confiance se trouve entièrement entre les limites d'équivalence, vous pouvez affirmer que la moyenne de la population est équivalente à la cible. Si une partie de l'intervalle de confiance se trouve en dehors des limites d'équivalence, vous ne pouvez pas affirmer qu'il existe une équivalence.
Différence : moyenne(Force) - cible
| Différence | ErT | IC 95% pour équivalence | Intervalle d'équivalence |
|---|---|---|---|
| 0,28500 | 0,13831 | (0; 0,520586) | (-0,42; 0,42) |
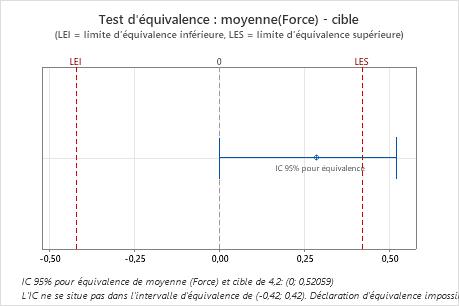
Résultats principaux : IC à 95 %, intervalle d'équivalence
Dans ces résultats, l'intervalle de confiance à 95 % dépasse la limite d'équivalence supérieure. Vous ne pouvez donc pas affirmer que la moyenne de la population équivaut à la cible.
Remarque
Si vous avez sélectionné une hypothèse alternative pour tester une inégalité, plutôt qu'une équivalence, évaluez les résultats globaux en comparant la borne inférieure à la limite inférieure ou en comparant la borne supérieure à la limite supérieure. Pour plus d'informations, reportez-vous à la rubrique Différence pour la fonction Test d'équivalence à 1 échantillon et cliquez sur "Borne inférieure" ou "Borne supérieure".
Etape 2 : rechercher les problèmes dans les données
Certains problèmes avec les données, comme la présence d'une asymétrie ou de valeurs aberrantes, risquent de nuire à vos résultats. Utilisez les graphiques pour rechercher toute asymétrie (en examinant la dispersion des données) et pour détecter d'éventuelles valeurs aberrantes.
Déterminer si les données sont asymétriques
Lorsque les données sont asymétriques, la majorité d'entre elles sont situées sur le côté supérieur ou inférieur du graphique. En général, l'asymétrie est plus facile à identifier avec un histogramme ou une boîte à moustaches.
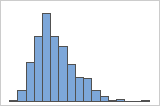
Asymétrie à droite
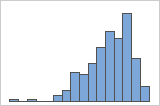
Asymétrie vers la gauche
Par exemple, l'histogramme avec des données asymétriques à droite illustre des données salariales. De nombreux employés reçoivent un salaire relativement faible et de moins en moins d'employés reçoivent un salaire élevé. L'histogramme avec des données asymétriques à gauche représente des données de taux de défaillance. Quelques éléments rencontrent une défaillance tôt, tandis que pour un nombre croissant d'entre eux, la défaillance survient plus tard.
Les données très asymétriques peuvent avoir une incidence sur la validité des résultats de test si votre échantillon est petit (moins de 20 valeurs). Si vos données sont très asymétriques et que vous avez un petit échantillon, pensez éventuellement à augmenter l'effectif d'échantillon.
Identification des valeurs aberrantes
Les valeurs aberrantes, qui sont des points de données très éloignés de la majorité des autres données, peuvent avoir une incidence importante sur les résultats. Elles sont plus faciles à repérer sur une boîte à moustaches.
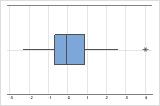
Sur une boîte à moustaches, les valeurs aberrantes sont indiquées par des astérisques (*).
Vous devez essayer de déterminer la cause de toutes les valeurs aberrantes. Corrigez les erreurs de mesure ou d’entrée des données. Supprimez les données associées à des causes spéciales et procédez à une nouvelle analyse. Pour plus d'informations sur les causes spéciales, reportez-vous à la rubrique Utilisation des cartes de contrôle pour détecter une variation due à des causes communes et une variation due à des causes spéciales.
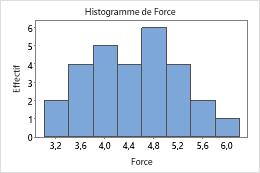
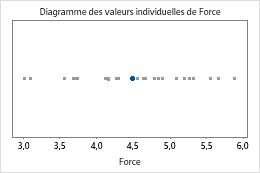
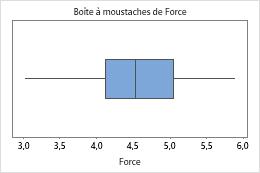
Dans ces graphiques, les données ne sont pas asymétriques et il n'existe aucune valeur aberrante.