Sur ce thème
Moyenne
La moyenne est une mesure courante du centre d'un ensemble de valeurs numériques. Il s'agit de la somme de toutes les observations divisée par le nombre d'observations (présentes).
Formule
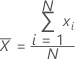
Notation
| Terme | Description |
|---|---|
| xi | ie observation |
| N | nombre d'observations présentes |
Ecart type (EcTyp)
L'écart type de l'échantillon fournit une mesure de l'étendue de vos données. Il est égal à la racine carrée de la variance de l'échantillon.
Formule
 , l'écart type de l'échantillon est :
, l'écart type de l'échantillon est :
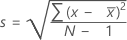
Notation
| Terme | Description |
|---|---|
| x i | ie observation |
 | moyenne des observations |
| N | nombre d'observations présentes |
N
Statistique d'Anderson-Darling (A2)
A2 mesure l'aire comprise entre la ligne ajustée (qui dépend de la loi de distribution sélectionnée) et la fonction en escalier non paramétrique (qui dépend des points relevés). Plus précisément, la statistique d'Anderson-Darling est le carré d'une distance ayant une pondération plus élevée aux extrémités de la loi de distribution. Une petite valeur d'Anderson-Darling indique que la loi correspond bien aux données.
Le test de normalité d'Anderson-Darling est défini comme suit :
H0 : Les données suivent une loi normale
H1 : Les données ne suivent pas une loi normale
Formule

Notation
| Terme | Description |
|---|---|
| F(Yi) |  , ce qui représente la fonction de répartition pour la loi normale standard. , ce qui représente la fonction de répartition pour la loi normale standard. |
| Yi | données ordonnées |
Ryan-Joiner
Le test Ryan-Joiner est un coefficient de corrélation, qui indique la corrélation entre vos données et les scores normaux de vos données. Si le coefficient de corrélation est proche de 1, vos points de données seront proches de la droite de Henry. S'il est inférieur à la valeur critique appropriée, vous pouvez rejeter l'hypothèse nulle de normalité.
Formule
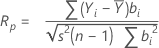
Notation
| Terme | Description |
|---|---|
| Yi | observations ordonnées |
| bi | scores normaux pour vos données ordonnées |
| s2 | variance de l'échantillon |
Kolmogorov-Smirnov
Formule
- H0 : les données suivent une loi normale
- H1 : les données ne suivent pas une loi normale

Notation
| Terme | Description |
|---|---|
| D+ | maxi {i / n – Z (i)} |
| D– | maxi {Z (i) – (i – 1) / n)} |
| Z | F(X(i)) |
| F(x) | fonction de loi de probabilité pour la loi normale |
| X(i) | statistiques de l'ordre i dans un échantillon aléatoire, 1 ≤ i ≤ n |
| n | effectif d'échantillon |
Valeur de p
La valeur de p est une autre mesure quantitative permettant d'évaluer le résultat du test de normalité. Une valeur de p faible indique que l'hypothèse nulle est fausse.
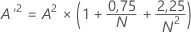
- Si 13 > A'2 > 0,600 alors p = exp(1,2937 - 5,709 * A'2 + 0,0186(A'2)2)
- Si 0,600 > A'2 > 0,340 alors p = exp(0,9177 - 4,279 * A'2 – 1,38(A'2)2)
- Si 0,340 > A'2 > 0,200 alors p = 1 – exp(–8,318 + 42,796 * A'2 – 59,938(A'2)2)
- Si A'2 <0,200 alors p = 1 – exp(–13,436 + 101,14 * A'2 – 223,73(A'2)2)
Points de diagramme
En général, plus vos points sont proches de la droite d'ajustement, meilleur est cet ajustement. Minitab propose deux mesures d'adéquation de l'ajustement pour vous aider à évaluer la façon dont la loi de distribution s'ajuste aux données.
Formule
| Loi de distribution | Coordonnée x | Coordonnée y |
|---|---|---|
| Normale | x | Φ–1 normale |
Notation
| Terme | Description |
|---|---|
| Φ–1 normale | valeur renvoyée pour p par la fonction de répartition inverse pour la loi normale standard. |
Diagrammes de probabilité
Les données d'entrée sont tracées comme valeurs de x. Minitab calcule la probabilité d'occurrence sans supposer une loi de distribution. L'échelle Y du graphique ressemble à celle d'un graphique de probabilité normal, où la courbe de probabilité est une ligne droite, comme si les données provenaient d'une loi normale.