Sur ce thème
Statistique d'Anderson-Darling (A2)
A2 mesure l'aire comprise entre la ligne ajustée (qui dépend de la loi de distribution sélectionnée) et la fonction en escalier non paramétrique (qui dépend des points relevés). Plus précisément, la statistique d'Anderson-Darling est le carré d'une distance ayant une pondération plus élevée aux extrémités de la loi de distribution. Une petite valeur d'Anderson-Darling indique que la loi correspond bien aux données.
Le test de normalité d'Anderson-Darling est défini comme suit :
H0 : Les données suivent une loi normale
H1 : Les données ne suivent pas une loi normale
Formule

Notation
| Terme | Description |
|---|---|
| F(Yi) |  , ce qui représente la fonction de répartition pour la loi normale standard. , ce qui représente la fonction de répartition pour la loi normale standard. |
| Yi | données ordonnées |
Valeur de P pour le test de normalité d'Anderson‑Darling
La valeur de p est une autre mesure quantitative pour reporter le résultat du test de normalité d'Anderson-Darling. Une valeur de p faible indique que l'hypothèse nulle est fausse.
Si vous connaissez A2, vous pouvez calculer la valeur de p.
Soit
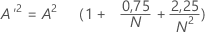
- Si 13 > A'2 > 0,60 alors p = exp(1,2937 - 5,709 * A'2 + 0,0186(A'2)2)
- Si 0,60 > A'2 > 0,34 alors p = exp(0,9177 - 4,279 * A'2 – 1,38(A'2)2)
- Si 0,34 > A'2 > 0,20 alors p = 1 – exp(–8,318 + 42,796 * A'2 – 59,938(A'2)2)
- Si A'2 < 0,200 alors p = 1 – exp(–13,436 + 101,14 * A'2 – 223,73(A'2)2)
Nombre de valeurs présentes (N)
Nombre de valeurs présentes dans votre échantillon.
Ecart type (EcTyp)
L'écart type de l'échantillon fournit une mesure de l'étendue de vos données. Il est égal à la racine carrée de la variance de l'échantillon.
Formule
 , l'écart type de l'échantillon est :
, l'écart type de l'échantillon est :
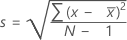
Notation
| Terme | Description |
|---|---|
| x i | ie observation |
 | moyenne des observations |
| N | nombre d'observations présentes |
Variance
La variance mesure le degré de dispersion des données autour de leur moyenne. Elle est égale à l'écart type au carré.
Formule
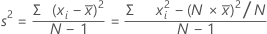
Notation
| Terme | Description |
|---|---|
| xi | ie observation |
 | moyenne des observations |
| N | nombre d'observations présentes |
Asymétrie
Il s'agit d'une mesure de l'asymétrie. Une valeur négative indique une asymétrie vers la gauche, tandis qu'une valeur positive indique une asymétrie vers la droite. Une valeur nulle n'indique pas forcément une symétrie.
Formule
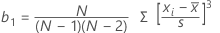
Notation
| Terme | Description |
|---|---|
| xi | ie observation |
 | moyenne des observations |
| N | nombre d'observations présentes |
| s | écart type de l'échantillon |
Aplatissement
L'aplatissement est une mesure de la différence d'une loi distribution par rapport à une loi normale. Une valeur positive indique généralement que la loi a un pic plus aigu que la distribution normale. Une valeur négative indique que la loi a un pic moins aigu que la distribution normale.
Formule

Notation
| Terme | Description |
|---|---|
| xi | ie observation |
 | moyenne des observations |
| N | nombre d'observations présentes |
| s | écart type de l'échantillon |
Moyenne
La moyenne est une mesure courante du centre d'un ensemble de valeurs numériques. Il s'agit de la somme de toutes les observations divisée par le nombre d'observations (présentes).
Formule
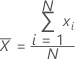
Notation
| Terme | Description |
|---|---|
| xi | ie observation |
| N | nombre d'observations présentes |
Minimum
Plus petite valeur de votre ensemble de données.
Maximum
Plus grande valeur de votre ensemble de données.
1er quartile (Q1)
25 % de vos observations d'échantillon sont inférieures ou égales à la valeur du 1er quartile. Donc, le 1er quartile est également le 25e percentile.
Formule

Notation
| Terme | Description |
|---|---|
| y | valeur d'entier tronqué de w |
| w | 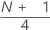 |
| z | composant de fraction de w tronqué |
| xj | je observation de la liste de données d'échantillon, classées de la plus petite à la plus grande |
Remarque
Lorsque x est un entier, y = w, z = 0 et Q1 = xy.
Médiane
La médiane de l'échantillon se trouve au milieu des données : au moins la moitié des observations lui est inférieure ou égale, et au moins la moitié lui est supérieure ou égale.
Supposez qu'une colonne contient N valeurs. Pour calculer la médiane, vous devez d'abord classer vos valeurs de données de la plus petite à la plus grande. Si N est impair, la médiane de l'échantillon est la valeur centrale. Si N est pair, la médiane de l'échantillon est la moyenne des deux valeurs centrales.
Par exemple, lorsque N = 5 et que vous avez les données x1, x2, x3, x4 et x5, la médiane est = x3.
Lorsque N = 6 et que vous avez classé les données x1, x2, x3, x4, x5 et x6 :
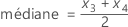
où x3 et x4 sont les troisième et quatrième observations.
3e quartile (Q3)
75 % de vos observations d'échantillon sont inférieures ou égales à la valeur du troisième quartile. Donc, le troisième quartile est également le 75e percentile.
Formule

Notation
| Terme | Description |
|---|---|
| y | valeur tronquée de w |
| w |
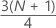 |
| z | composant de fraction de w tronqué |
| xj | je observation de la liste de données d'échantillon, classées de la plus petite à la plus grande |
Remarque
Lorsque w est un entier, y = w, z = 0 et Q3 = xy.
Intervalle de confiance de la moyenne
Formule

Notation
| Terme | Description |
|---|---|
 | moyenne |
| s | écart type de l'échantillon |
| N | nombre de valeurs présentes |
| t N, α | probabilité cumulée inverse d'une distribution en t avec N - 1 degrés de liberté à 1 – α / 2 ; α = 1 – niveau de confiance / 100 |
Intervalle de confiance pour la médiane
Minitab utilise l'interpolation linéaire pour calculer l'intervalle de confiance pour la médiane réelle 1. Cette méthode est une excellente approximation pour un grand nombre de lois symétriques, notamment la loi normale, la loi de Cauchy et la loi uniforme. Des exemples de loi asymétrique montrent des résultats adéquats qui sont toujours plus précis qu'une interpolation linéaire.
Intervalle de confiance pour l'écart type
Minitab calcule un intervalle de confiance à (1 – α) 100 % pour l'écart type de la population σ. L'intervalle de confiance est très sensible à l'hypothèse de normalité des données. Même un écart mineur par rapport à la normalité peut entraîner un intervalle de confiance trompeur.
Formule
L'intervalle de confiance s'étend de :

Notation
| Terme | Description |
|---|---|
| s | écart type |
| N | nombre de valeurs présentes |
| χ2N, α | probabilité cumulée inverse de χ2 avec N degrés de liberté à 1 – α / 2 ; α = 1 – niveau de confiance / 100 |