Sur ce thème
Moyenne estimée
Formule
La moyenne de la loi de distribution de Poisson est estimée comme suit :
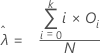
Calcul
| Données | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Catégorie (i) | Observé (Oi) | Moyenne estimée | Probabilité de Poisson (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e-2,4 = 0,090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e-2,4 * 2,4 = 0,217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e-2,4 * (2,4)2/ 2! = 0,261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e-2,4 * (2,4)3/ 3! = 0,209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3) = 0,221267 |
N = 35
Σ (i * Oi) = 84
Moyenne estimée = 
Notation
| Terme | Description |
|---|---|
| N | somme de toutes les valeurs observées (O0 + O1 + ...+ Ok) |
| k | (nombre de catégories) - 1 |
| Oi | nombre d'événements observé dans la Ie catégorie |
| pi | probabilité de Poisson |
Nombre de catégories
Minitab détermine les catégories à l'aide des méthodes itératives suivantes :
Définition de la première catégorie
Pour pi = P(X  xi )
xi )
Pour i = 1 : si N*pi  2, la première catégorie est définie comme "
2, la première catégorie est définie comme " x 1". Si N*pi < 2, augmentez i de 1 et réessayez ; si N*p 2
x 1". Si N*pi < 2, augmentez i de 1 et réessayez ; si N*p 2  2, la première catégorie est définie comme "
2, la première catégorie est définie comme " x 2". Si N*pi < 2, augmentez i de 1 et réessayez jusqu'à ce que N*pi
x 2". Si N*pi < 2, augmentez i de 1 et réessayez jusqu'à ce que N*pi  2. Arrêtez les itérations soit dès que cette condition est satisfaite, soit lorsque xi est la troisième valeur de données la plus grande, et définissez la première catégorie comme "
2. Arrêtez les itérations soit dès que cette condition est satisfaite, soit lorsque xi est la troisième valeur de données la plus grande, et définissez la première catégorie comme " xi ". Si la valeur de la première catégorie est zéro, alors celle-ci est définie comme "0", sans le signe "inférieur ou égal à". La valeur de probabilité et la valeur attendue associées à la première catégorie sont respectivement pi et N*pi . La valeur observée pour la première catégorie est le nombre total de valeurs de données
xi ". Si la valeur de la première catégorie est zéro, alors celle-ci est définie comme "0", sans le signe "inférieur ou égal à". La valeur de probabilité et la valeur attendue associées à la première catégorie sont respectivement pi et N*pi . La valeur observée pour la première catégorie est le nombre total de valeurs de données  xi .
xi .
Définition de la dernière catégorie
En théorie, la procédure de définition de la dernière catégorie est similaire à celle de la première catégorie, mais Minitab fonctionne à rebours, en commençant par la valeur de donnée la plus grande.
La dernière catégorie est " xj ", où xj est la plus grande valeur de donnée, supérieure à (1 + la valeur de donnée de la première catégorie), de sorte que la catégorie a une valeur attendue supérieure à 2. La valeur de probabilité et la valeur attendue pour la dernière catégorie sont respectivement pj et N*pj , et la valeur observée est le nombre de valeurs de données
xj ", où xj est la plus grande valeur de donnée, supérieure à (1 + la valeur de donnée de la première catégorie), de sorte que la catégorie a une valeur attendue supérieure à 2. La valeur de probabilité et la valeur attendue pour la dernière catégorie sont respectivement pj et N*pj , et la valeur observée est le nombre de valeurs de données  xj .
xj .
Définition des catégories du milieu
Après avoir déterminé les première et dernière catégories, Minitab détermine les catégories qui se trouvent entre elles. Pour "X  k" en première catégorie, et "X
k" en première catégorie, et "X  m" en dernière catégorie, si tous les entiers entre (k, m) ont la valeur attendue de
m" en dernière catégorie, si tous les entiers entre (k, m) ont la valeur attendue de  2, ils constituent tous une catégorie du milieu. Dans le cas contraire, Minitab utilise une boucle récursive pour grouper des entiers adjacents en catégories pour lesquelles les valeurs attendues
2, ils constituent tous une catégorie du milieu. Dans le cas contraire, Minitab utilise une boucle récursive pour grouper des entiers adjacents en catégories pour lesquelles les valeurs attendues  2. Dans certaines situations, comme un ensemble de données avec peu d'observations, la valeur attendue d'une catégorie sera inférieure à 2.
2. Dans certaines situations, comme un ensemble de données avec peu d'observations, la valeur attendue d'une catégorie sera inférieure à 2.
Notation
| Terme | Description |
|---|---|
| N | nombre total d'observations |
| xi | ie valeur de l'ensemble de données, après classement de la plus petite à la plus grande |
| pi | probabilité de Poisson |
Probabilité de Poisson
Formule
La probabilité de Poisson de la ie catégorie (i < k) est,

La probabilité de Poisson pour la dernière catégorie, où i = k,
pi = 1 – (p0 + p1 + ...+ pk-1)
Notation
| Terme | Description |
|---|---|
| k | nombre de catégories |
| λ | moyenne estimée d'après votre échantillon |
Chiffre attendu
Formule
Le nombre d'observations attendu dans la ie catégorie est N * pi .
Notation
| Terme | Description |
|---|---|
| N | effectif d'échantillon |
| pi | probabilité de Poisson associée à la ie catégorie |
Contribution au Khi deux
Formule
La contribution de la Ie catégorie à la valeur du Khi deux est calculée comme suit
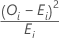
Notation
| Terme | Description |
|---|---|
| OI | nombre d'observations observé dans la Ie catégorie |
| EI | nombre d'observations attendu dans la Ie catégorie |
Statistique de test
Formule
La statistique du test d'ajustement du Khi deux se calcule comme suit,
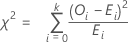
Notation
| Terme | Description |
|---|---|
| k | (nombre de catégories) - 1 |
| Oi | nombre d'observations observé dans la Ie catégorie |
| Ei | nombre d'observations attendu dans la ie catégorie |
Valeur de p et degrés de liberté
La valeur de p est :
Prob (X > statistique de test)
où X suit la loi de Khi deux avec k - 1 degrés de liberté, si vous utilisez la sous-commande MEAN (moyenne) ou k - 2 degrés de liberté si vous n'utilisez pas la sous-commande MEAN (moyenne).
Calcul
| Données | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Catégorie (i) | Observé (Oi) | Moyenne estimée | Probabilité de Poisson (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e -2,4 = 0,090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e -2,4 * 2,4 = 0,217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e -2,4 * (2,4)2/ 2! = 0,261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e -2,4 * (2,4)3/ 3! = 0,209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3 ) = 0,221267 |
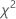 = ( 0,43492 + 0,344527 + 0,080058 + 0,985114 + 0,071545) = 1,91622
= ( 0,43492 + 0,344527 + 0,080058 + 0,985114 + 0,071545) = 1,91622
k = 5= nombre de catégories
DL = 5 - 2 = 3
valeur de p = P (X > 1,91622) = 0,590
Notation
| Terme | Description |
|---|---|
| k | nombre de catégories |
| Oi | nombre d'observations observé dans la Ie catégorie. |
| Ei | nombre d'observations attendu dans la ie catégorie. |
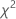 | statistique de test d'ajustement du Khi deux |
| DL | degrés de liberté |