Sur ce thème
Etape 1 : Déterminer un intervalle de confiance pour la différence des moyennes de population
Considérez d'abord la différence entre les moyennes d'échantillon, puis examinez l'intervalle de confiance.
La différence est une estimation de la différence entre les moyennes de population. La différence étant calculée à partir des données d'échantillon et non de l'ensemble de la population, il est peu probable que la différence de l'échantillon soit égale à celle de la population. Pour mieux estimer la différence de la population, utilisez l'intervalle de confiance.
L'intervalle de confiance fournit une étendue de valeurs probables pour la différence entre deux moyennes de population. Par exemple, un niveau de confiance de 95 % indique que, sur 100 échantillons pris de façon aléatoire parmi la population, environ 95 de ces échantillons devraient produire des intervalles contenant la différence de population. L'intervalle de confiance vous aide à évaluer la signification pratique de vos résultats. Utilisez vos connaissances spécialisées pour déterminer si l'intervalle de confiance comporte des valeurs ayant une signification pratique pour votre situation. Si l'intervalle est trop grand pour être utile, vous devez sans doute augmenter votre effectif d'échantillon. Pour plus d'informations, reportez-vous à la rubrique Obtenir un intervalle de confiance plus précis.
Estimation de la différence
| Différence | IC à 95% pour la différence |
|---|---|
| 21,00 | (14,22; 27,78) |
Résultats principaux : estimation de la différence, intervalle de confiance à 95 % pour la différence
Dans ces résultats, l'estimation de la différence des moyennes de la population en matière d'évaluations d'hôpitaux est de 21. Vous pouvez être sûr à 95 % que la moyenne de la population pour la différence est comprise entre 14,22 et 27,78.
Etape 2 : Déterminer si la différence est statistiquement significative
- Valeur de p ≤ α : la différence entre les moyennes est statistiquement significative (Rejeter H0)
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez rejeter l'hypothèse nulle. Vous pouvez conclure que la différence entre les moyennes de population n'est pas égale à la différence hypothétisée. Si vous n'avez pas spécifié de différence hypothétisée, Minitab vérifie l'absence de différence entre les moyennes (Différence hypothétisée = 0). Utilisez vos connaissances afin de déterminer si la différence est significative dans la pratique. Pour plus d'informations, reportez-vous à la rubrique Signification statistique et pratique.
- Valeur de p > α : la différence entre les moyennes n'est pas statistiquement significative (Impossible de rejeter H0)
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas rejeter l'hypothèse nulle. Vous n'êtes pas en mesure de conclure que la différence entre les moyennes de population est statistiquement significative. Vous devez vous assurer que votre test est assez puissant pour détecter une différence qui est significative dans la pratique. Pour plus d'informations, reportez-vous à la rubrique Puissance et effectif de l'échantillon pour un test t à 2 échantillons.
Test
| Hypothèse nulle | H₀ : μ₁ - µ₂ = 0 |
|---|---|
| Hypothèse alternative | H₁ : μ₁ - µ₂ ≠ 0 |
| Valeur de T | DL | Valeur de P |
|---|---|---|
| 6,31 | 32 | 0,000 |
Résultat principal : valeur de p
Dans ces résultats, l'hypothèse nulle indique que la différence de taux moyen entre deux hôpitaux est de 0. Comme la valeur de p est inférieure à 0,00, ce qui est inférieur au seuil de signification de 0,05, il faut rejeter l'hypothèse nulle et conclure que les taux des hôpitaux sont différents.
Etape 3 : rechercher les problèmes dans les données
Certains problèmes avec les données, comme la présence d'une asymétrie ou de valeurs aberrantes, risquent de nuire à vos résultats. Utilisez les graphiques pour rechercher toute asymétrie (en examinant la dispersion de chaque échantillon) et pour détecter d'éventuelles valeurs aberrantes.
Examinez la dispersion des données pour déterminer si elles semblent asymétriques.
Lorsque les données sont asymétriques, la majorité d'entre elles sont situées sur le côté supérieur ou inférieur du graphique. En général, l'asymétrie est plus facile à détecter avec un histogramme ou une boîte à moustaches.
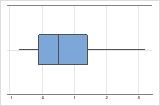
Asymétrie à droite
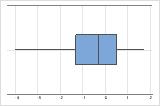
Asymétrie vers la gauche
La boîte à moustaches avec des données asymétriques à droite illustre des temps d'attente. La plupart des temps d'attente sont relativement courts, seuls certains sont longs. La boîte à moustaches avec des données asymétriques à gauche représente des données de temps de défaillance. Quelques éléments rencontrent une défaillance immédiatement, mais pour bien plus d'entre eux, elle survient plus tard.
Les données qui sont très asymétriques peuvent avoir une incidence sur la validité de la valeur de p si vos échantillons sont petits (l'un des échantillons contient moins de 15 valeurs). Si vos données sont très asymétriques et que vous avez un petit échantillon, pensez éventuellement à augmenter l'effectif d'échantillon.
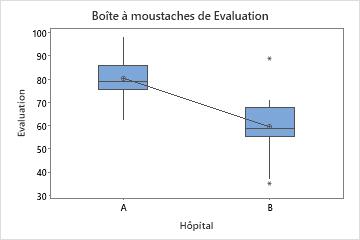
Résultats d'échantillon
Dans ces boîtes à moustaches, les données de l'hôpital B semblent sérieusement asymétriques.
Identification des valeurs aberrantes
Les valeurs aberrantes, qui sont des valeurs de données très éloignées des autres valeurs de données, peuvent avoir une incidence importante sur les résultats de votre analyse. En général, les valeurs aberrantes sont plus faciles à repérer sur une boîte à moustaches.
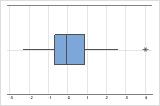
Sur une boîte à moustaches, les astérisques (*) indiquent les valeurs aberrantes.
Essayez de déterminer la cause de toutes les valeurs aberrantes. Corrigez les erreurs de mesure ou d’entrée des données. Supprimez éventuellement les valeurs de données associées à des événements anormaux et uniques (aussi appelés causes spéciales). Ensuite, répétez l'analyse. Pour plus d'informations, reportez-vous à la rubrique Identification des valeurs aberrantes.
Résultats d'échantillon
Dans ces boîtes à moustaches, les données de l'hôpital B ont 2 valeurs aberrantes.