Sur ce thème
- Statistiques
- Test d'hypothèse pour une différence de taux pour l'approximation de loi normale
- Test d'hypothèse pour une différence de taux pour la méthode exacte
- Test d'hypothèse pour une différence de taux avec la méthode des taux regroupés
- Test d'hypothèse pour une différence de moyennes pour la méthode d'approximation de loi normale
- Test hypothétique pour une différence de moyennes pour la méthode exacte
- Test d'hypothèse pour une différence de moyennes pour la méthode des moyennes regroupées
- Intervalle de confiance pour la différence de taux
- Bornes de confiance pour la différence de taux
- Intervalle de confiance pour la différence de moyennes
- Bornes de confiance pour la différence de moyennes
Statistiques
| Terme | Description |
|---|---|
| taux d'occurrence pour l'échantillon i |
 |
| Terme | Description |
|---|---|
| nombre d'occurrences de la moyenne dans l'échantillon i |
 |
Test d'hypothèse pour une différence de taux pour l'approximation de loi normale
Formule
Le test d'approximation de loi normale est basé sur la statistique Z suivante, qui est répartie approximativement selon la loi normale standard, sous l'hypothèse nulle suivante :
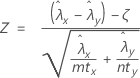
Minitab utilise les équations suivantes pour calculer les valeurs de p correspondant aux différentes hypothèses alternatives ci-dessous :
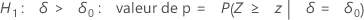
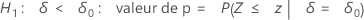

Notation
| Terme | Description |
|---|---|
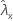 | valeur observée pour le taux de l'échantillon X |
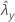 | valeur observée pour le taux de l'échantillon Y |
| ζ | valeur réelle de la différence entre les taux de population de deux échantillons |
| ζ0 | valeur hypothétisée de la différence entre les taux de population de deux échantillons |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
| tx | durée de l'échantillon X |
| ty | durée de l'échantillon Y |
Test d'hypothèse pour une différence de taux pour la méthode exacte
Formule
Lorsque la différence hypothétisée est égale à 0, Minitab teste l'hypothèse nulle suivante avec une procédure exacte :
H0 : ζ = λx – λy = 0, ou H0 : λx = λy
La procédure exacte est basée sur le fait suivant, en supposant que l'hypothèse nulle est vraie :
S | W ~ Binomiale (w, p)
où :


W = S + U


-
H1 : ζ > 0 : valeur de p = P(S ≥ s | w = s + u, p = p0)
-
H1 : ζ < 0 : valeur de p = P(S ≤ s | w = s + u, p = p0)
- H1 : ζ ≠ 0 :
- si P(S ≤ s | w = s + u, p = p0) ≤ 0,5 ou P(S ≥ s | w = s + u, p = p0) ≤ 0,5
alors la valeur de p = 2 × min {P(S ≤ s | w = s + u, p = p0), P(S ≥ s | w = s + u, p = p0)}
- sinon, valeur de p = 1,0
- si P(S ≤ s | w = s + u, p = p0) ≤ 0,5 ou P(S ≥ s | w = s + u, p = p0) ≤ 0,5
où :

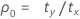
Notation
| Terme | Description |
|---|---|
 | valeur observée pour le taux de l'échantillon X |
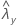 | valeur observée pour le taux de l'échantillon Y |
| λx | valeur réelle du taux de la population X |
| λy | valeur réelle du taux de la population Y |
| ζ | valeur réelle de la différence entre les taux de population de deux échantillons |
| tx | longueur de l'échantillon X |
| ty | longueur de l'échantillon Y |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
Test d'hypothèse pour une différence de taux avec la méthode des taux regroupés
Lorsque vous testez une différence de zéro avec l'hypothèse nulle ci-dessous, vous pouvez utiliser un taux regroupé pour les deux échantillons.

Formule
La procédure des taux regroupés est basée sur la statistique Z suivante, qui est répartie approximativement selon la loi normale standard, sous l'hypothèse nulle suivante :
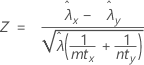
où :
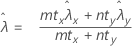
Minitab utilise les équations suivantes pour calculer les valeurs de p correspondant aux différentes hypothèses alternatives ci-dessous :



Notation
| Terme | Description |
|---|---|
 | valeur observée pour le taux de l'échantillon X |
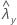 | valeur observée pour le taux de l'échantillon Y |
| λx | valeur réelle du taux de la population X |
| λy | valeur réelle du taux de la population Y |
| ζ | valeur réelle de la différence entre les taux de population de deux échantillons |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
| tx | durée de l'échantillon X |
| ty | durée de l'échantillon Y |
Test d'hypothèse pour une différence de moyennes pour la méthode d'approximation de loi normale
Formule
Le test d'approximation de loi normale est basé sur la statistique Z suivante, qui est répartie approximativement selon la loi normale standard, sous l'hypothèse nulle suivante :
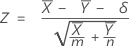
Minitab utilise les équations suivantes pour calculer les valeurs de p correspondant aux différentes hypothèses alternatives ci-dessous :
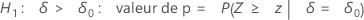
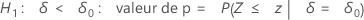

Notation
| Terme | Description |
|---|---|
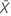 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon X |
 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon Y |
| δ | valeur réelle de la différence entre les moyennes de population de deux échantillons |
| δ 0 | valeur hypothétisée de la différence entre les moyennes de population de deux échantillons |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
Test hypothétique pour une différence de moyennes pour la méthode exacte
Formule

La procédure exacte est basée sur le fait suivant, en supposant que l'hypothèse nulle est vraie :
S | W ~ Binomiale (w, p)
où :


W = S + U
Minitab utilise les équations suivantes pour calculer les valeurs de p correspondant aux différentes hypothèses alternatives ci-dessous :
H1 : δ > 0 : valeur de p = P(S ≥ s | w = s + u, δ = 0)
H1 : δ < 0 : valeur de p = P(S ≤ s | w = s + u, δ = 0)
-
si P(S ≤ s|w = s + u, δ = 0) ≤ 0,5
ou P(S ≥ s|w = s + u, δ = 0) ≤ 0,5
alors :
- sinon, valeur de p = 1,0
Un test bilatéral n'est pas un test symétrique, sauf si m = n.
Notation
| Terme | Description |
|---|---|
| μx | valeur réelle du nombre d'occurrences moyen dans la population X |
| μy | valeur réelle du nombre d'occurrences moyen dans la population Y |
| δ | valeur réelle de la différence entre les moyennes de population de deux échantillons |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
Test d'hypothèse pour une différence de moyennes pour la méthode des moyennes regroupées
Formule

La procédure des moyennes regroupées est basée sur la valeur Z suivante, qui est répartie approximativement selon la loi normale standard, sous l'hypothèse nulle suivante :
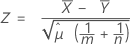
où :
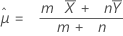
Minitab utilise les équations avec valeur p suivantes pour les hypothèses alternatives respectives :
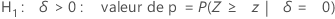

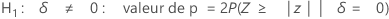
Notation
| Terme | Description |
|---|---|
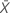 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon X |
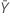 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon Y |
| µx | valeur réelle du nombre d'occurrences moyen dans la population X |
| µy | valeur réelle du nombre d'occurrences moyen dans la population Y |
| δ | valeur réelle de la différence entre les moyennes de population de deux échantillons |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
Intervalle de confiance pour la différence de taux
Formule
Un intervalle de confiance à 100(1 – α) % pour la différence entre deux taux de Poisson de populations s'obtient comme suit :
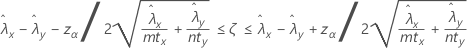
Notation
| Terme | Description |
|---|---|
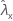 | valeur observée pour le taux de l'échantillon X |
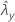 | valeur observée pour le taux de l'échantillon Y |
| ζ | valeur réelle de la différence entre les taux de population de deux échantillons |
| zx | point de percentile supérieur x de la loi normale standard, où 0 < x < 1 |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
| tx | durée de l'échantillon X |
| ty | durée de l'échantillon Y |
Bornes de confiance pour la différence de taux
Formule
Lorsque vous indiquez un test de type "supérieur à", la borne de confiance inférieure pour la différence entre deux taux de Poisson de populations, à un niveau de confiance de 100(1 – α) %, s'obtient comme suit :
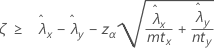
Lorsque vous indiquez un test de type "inférieur à", la borne de confiance supérieure pour la différence entre deux taux de Poisson de populations, à un niveau de confiance de 100(1 – α) %, s'obtient comme suit :
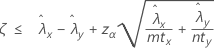
Notation
| Terme | Description |
|---|---|
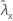 | valeur observée pour le taux de l'échantillon X |
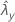 | valeur observée pour le taux de l'échantillon Y |
| ζ | valeur réelle de la différence entre les taux de population de deux échantillons |
| zx | le point percentile supérieur x de la loi normale standard, où 0 < x < 1 |
| m | effectif de l'échantillon X |
| n | Effectif de l'échantillon Y |
| tx | longueur de l'échantillon X |
| ty | longueur de l'échantillon Y |
Intervalle de confiance pour la différence de moyennes
Formule
Un intervalle de confiance à 100(1 – α) % pour la différence entre deux moyennes de Poisson de populations s'obtient comme suit :
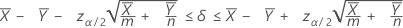
Notation
| Terme | Description |
|---|---|
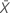 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon X |
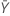 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon Y |
| δ | valeur réelle de la différence entre les moyennes de population de deux échantillons |
| zx | point de percentile supérieur x de la loi normale standard, où 0 < x < 1 |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |
Bornes de confiance pour la différence de moyennes
Formule
Lorsque vous indiquez un test de type "supérieur à", la borne de confiance inférieure pour la différence entre deux moyennes de Poisson de populations, à un niveau de confiance de 100(1 – α) %, s'obtient comme suit :
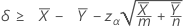
Lorsque vous indiquez un test de type "inférieur à", la borne de confiance supérieure pour la différence entre deux moyennes de Poisson de populations, à un niveau de confiance de 100(1 – α) %, s'obtient comme suit :
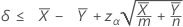
Notation
| Terme | Description |
|---|---|
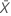 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon X |
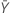 | valeur observée pour le nombre moyen d'occurrences dans l'échantillon Y |
| δ | valeur réelle de la différence entre les moyennes de population de deux échantillons |
| zx | point de percentile supérieur x de la loi normale standard, où 0 < x < 1 |
| m | effectif de l'échantillon X |
| n | effectif de l'échantillon Y |