- Lt = α Yt + (1 - α) [Lt-1 + Tt-1]
- Tt = γ[Lt - Lt-1] + (1 - γ) Tt-1
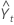 = Lt-1 + Tt-1
= Lt-1 + Tt-1
où Lt est le niveau à l'instant t, α est la pondération du niveau, Tt est la tendance à l'instant t, γ est la pondération de la tendance, Yt est la valeur des données à l'instant t et 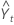 est la valeur ajustée, ou prévision anticipée, à l'instant t.
est la valeur ajustée, ou prévision anticipée, à l'instant t.
La première observation porte le numéro 1. Pour pouvoir poursuivre, les estimations de niveau et de tendance à l'instant zéro doivent ensuite être initialisées. La méthode d'initialisation utilisée pour déterminer les valeurs lissées peut être obtenue de deux façons : avec des pondérations générées par Minitab ou avec des pondérations que vous définissez.
| Pondérations ARIMA optimisées | Pondérations spécifiées |
|---|---|
|
|
Si vous spécifiez des pondérations qui correspondent à un modèle ARIMA (0,2,2) à racines égales, la méthode de Holt se rapproche de la méthode de Brown.