Sur ce thème
Etape 1 : Envisager d’autres modèles
Le tableau Sélection du modèle affiche les critères de chaque modèle dans la recherche. Le tableau affiche l’ordre des termes où p est le terme autorégressif, d est le terme de différenciation et q est le terme de la moyenne mobile. Les termes saisonniers utilisent des lettres majuscules et les termes non saisonniers utilisent des lettres minuscules.
Utilisez les valeurs AIC, AICc et BIC pour comparer différents modèles. Les valeurs faibles sont les valeurs souhaitables. Cependant, le modèle avec la valeur la plus faible pour un ensemble de termes ne correspond pas nécessairement bien aux données. Utilisez des tests et des graphiques pour évaluer dans quelle mesure le modèle s’adapte aux données. Par défaut, les résultats ARIMA sont pour le modèle avec la meilleure valeur d’AICc.
Sélectionnez Sélectionner un autre modèle cette option pour ouvrir une boîte de dialogue qui inclut un tableau Sélection de modèle. Comparez les critères pour étudier des modèles ayant des performances similaires.
Utilisez la sortie ARIMA pour vérifier que les termes du modèle sont statistiquement significatifs et que le modèle répond aux hypothèses de l’analyse. Si aucun des modèles du tableau ne correspond bien aux données, considérez les modèles avec différents ordres de différenciation.
- Les coefficients peuvent sembler non significatifs, même lorsqu'une relation significative existe entre le prédicteur et la réponse.
- Les coefficients de prédicteurs fortement corrélés varieront considérablement d'un échantillon à un autre.
- Lorsque des termes d'un modèle sont fortement corrélés, la suppression de l'un de ces termes aura une incidence considérable sur les coefficients estimés des autres. Les coefficients des termes fortement corrélés peuvent même présenter le mauvais signe.
Sélection du modèle
| Modèle (d = 1) | LogVraisemblance | AICc | AIC | BIC |
|---|---|---|---|---|
| p = 0; q = 2* | -197,052 | 400,878 | 400,103 | 404,769 |
| p = 1; q = 2 | -196,989 | 403,311 | 401,978 | 408,199 |
| p = 1; q = 0 | -201,327 | 407,029 | 406,654 | 409,765 |
| p = 2; q = 0 | -200,239 | 407,251 | 406,477 | 411,143 |
| p = 1; q = 1 | -200,440 | 407,655 | 406,880 | 411,546 |
| p = 2; q = 1 | -201,776 | 412,884 | 411,551 | 417,773 |
| p = 0; q = 1 | -204,584 | 413,542 | 413,167 | 416,278 |
| p = 0; q = 0 | -213,614 | 429,350 | 429,229 | 430,784 |
Principaux résultats : AICc, BIC et AIC
L’ARIMA(0, 1, 2) a la meilleure valeur d’AICc. Les résultats ARIMA qui suivent concernent le modèle ARIMA(0, 1, 2). Si le modèle ne correspond pas suffisamment aux données, considérez d’autres modèles ayant des performances similaires, tels que le modèle ARIMA(1, 1, 2) et le modèle ARIMA (1, 1, 1). Si aucun des modèles ne correspond suffisamment aux données, demandez-vous s’il faut utiliser un autre type de modèle.
Etape 2 : Déterminer si chaque terme du modèle est significatif
- ≤ α de la valeur P : Le terme est statistiquement significatif
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez en conclure que le coefficient est statistiquement significatif.
- > α de la valeur P : Le terme n’est pas statistiquement significatif
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas conclure que le coefficient est statistiquement significatif. Il est sans doute nécessaire de réajuster le modèle sans le terme.
Estimations finales des paramètres
| Type | Coeff | Coef ErT | Valeur de T | Valeur de p |
|---|---|---|---|---|
| AR 1 | -0,504 | 0,114 | -4,42 | 0,000 |
| Constante | 150,415 | 0,325 | 463,34 | 0,000 |
| Moyenne | 100,000 | 0,216 |
Principaux résultats : P, Coef
Le terme autorégressif a une valeur de p inférieure au seuil de signification de 0,05. Vous pouvez en conclure que le coefficient du terme autorégressif est statistiquement significatif : vous devez conserver le terme dans le modèle.
Etape 3 : Déterminer si votre modèle respecte l'hypothèse de l'analyse
- Statistiques du Khi deux de Ljung-Box
- Pour déterminer si les valeurs résiduelles sont indépendantes, comparez la valeur de p au seuil de signification pour chaque statistique du Khi deux. En général, un seuil de signification (noté alpha ou α) de 0,05 fonctionne bien. Si la valeur de p est supérieure au seuil de signification, vous pouvez en conclure que les valeurs résiduelles sont indépendantes et que le modèle respecte l'hypothèse.
- Fonction d'autocorrélation des valeurs résiduelles
- Si aucune corrélation significative n'est présente, vous pouvez en conclure que les valeurs résiduelles sont indépendantes. Toutefois, vous pouvez relever 1 ou 2 corrélations significatives pour des décalages d'ordre supérieur qui ne sont pas des décalages de saisonnalité. Ces corrélations sont en général dues à l'erreur aléatoire et ne signifient pas que l'hypothèse n'est pas respectée. Dans un tel cas, vous pouvez conclure que les valeurs résiduelles sont indépendantes.
Box-Pierce (Ljung-Box) modifiée Statistique du Khi deux
| Décalage | 12 | 24 | 36 | 48 |
|---|---|---|---|---|
| Khi deux | 4,05 | 12,13 | 25,62 | 32,09 |
| DL | 10 | 22 | 34 | 46 |
| Valeur de p | 0,945 | 0,955 | 0,849 | 0,940 |
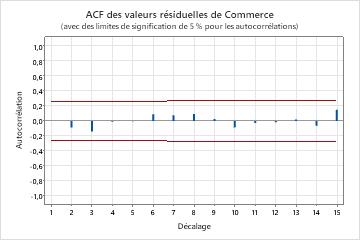
Résultats principaux : valeur de p, ACF des valeurs résiduelles
Dans ces résultats, les valeurs de p pour les statistiques du Khi deux de Ljung-Box sont supérieures à 0,05 et aucune des corrélations de la fonction d'autocorrélation des valeurs résiduelles n'est significative. Vous pouvez en conclure que le modèle respecte l'hypothèse selon laquelle les valeurs résiduelles sont indépendantes.