Sur ce thème
- Error
- Période
- Prévision
- Diagramme de décomposition de série chronologique
- Analyse de composante
- Analyse saisonnière
- Histogramme des valeurs résiduelles
- Droite de Henry des valeurs résiduelles
- Valeurs résiduelles en fonction des valeurs ajustées
- Valeurs résiduelles en fonction de l'ordre
- Valeurs résiduelles en fonction des variables
Longueur
Nombre d'observations dans la série chronologique.
Nombre de valeurs manquantes
Nombre de valeurs manquantes dans la série chronologique.
Equation de tendance ajustée
Utilisez l'équation de tendance ajustée pour calculer la composante de tendance correspondant à une période spécifique. L'équation de tendance ajustée est une représentation algébrique de la ligne de tendance. L'équation de tendance ajustée se présente sous la forme Yt = b0 + (b1 * t).
- yt est la variable
- b0 est la constante
- b1 est la pente
- t est la valeur de l'unité de temps
Minitab utilise l'équation de tendance ajustée et les indices saisonniers pour calculer les valeurs prévues.
Interprétation
Minitab utilise l'équation de tendance ajustée pour calculer la composante de tendance, qui est utilisée avec les indices saisonniers afin de calculer les données prévues. Par exemple, si l'équation de tendance ajustée est la suivante :
Yt = 173,06 + 2,111*t
La composante de tendance correspondant à la troisième période est 173,06 + 2,11*3 = 182,45
Minitab calcule également les données débarrassées de la tendance, soit en les divisant par la composante de tendance (modèle multiplicatif), soit en leur soustrayant cette composante de tendance (modèle additif).
Saisonnalité et indices saisonniers
Les indices saisonniers (également nommés Saisonnalité dans le tableau contenant les données initiales) représentent les effets de saisonnalité à l'instant t. Minitab utilise ces indices pour désaisonnaliser les données, soit en les divisant par les indices saisonniers (modèle multiplicatif), soit en leur soustrayant ces indices (modèle additif). Minitab utilise également l'équation de tendance ajustée et les indices saisonniers pour calculer les valeurs prévues.
MAPE
La valeur MAPE (pourcentage d'erreur absolu moyen) exprime l'exactitude sous la forme d'un pourcentage de l'erreur. A ce titre, elle peut être plus facile à comprendre que les autres statistiques de mesure de l'exactitude. Par exemple, si la valeur MAPE est de 5, en moyenne, la prévision est erronée de 5 %.
Cependant, vous pouvez parfois constater une valeur MAPE élevée alors que le modèle semble correctement ajusté aux données. Dans ce cas, étudiez le diagramme pour savoir si des valeurs de données sont proches de 0. Etant donné que la statistique MAPE divise l'erreur absolue par les données réelles, les valeurs proches de 0 peuvent la faire augmenter de manière importante.
Interprétation
Utilisez cet outil pour comparer les valeurs ajustées de différents modèles de série chronologique. Plus les valeurs sont faibles, meilleur est l'ajustement. Si aucun même modèle ne réunit les valeurs les plus basses pour les 3 mesures d'exactitude, la statistique MAPE est généralement celle qui est privilégiée.
Les mesures d'exactitude reposent sur les valeurs résiduelles obtenues à partir de la période précédente. A chaque point dans le temps, le modèle est utilisé pour prévoir la valeur Y pour la prochaine période. La différence entre les valeurs prévues (valeurs résiduelles) et la valeur Y réelle est égale aux valeurs résiduelles obtenues à partir de la période précédente. De ce fait, les mesures de l'exactitude fournissent une indication de l'exactitude à attendre lorsque vous effectuez une prévision pour une période à partir de la fin des données. Ainsi, elles n'indiquent pas l'exactitude des prévisions au-delà d'une période. Si vous comptez utiliser le modèle pour effectuer des prévisions, vous ne devez pas vous fier uniquement aux mesures d'exactitude pour prendre une décision. Vous devez également examiner l'ajustement du modèle pour vous assurer qu'il suit étroitement les données, notamment à la fin de la série, et qu'il en est de même pour les prévisions.
MAD
L'écart absolu moyen (MAD) exprime l'exactitude dans les mêmes unités que les données, ce qui aide à conceptualiser l'importance de l'erreur. Les valeurs aberrantes ont moins d'effet sur le MAD que sur le MSD.
Interprétation
Utilisez cet outil pour comparer les valeurs ajustées de différents modèles de série chronologique. Plus les valeurs sont faibles, meilleur est l'ajustement.
Les mesures d'exactitude reposent sur les valeurs résiduelles obtenues à partir de la période précédente. A chaque point dans le temps, le modèle est utilisé pour prévoir la valeur Y pour la prochaine période. La différence entre les valeurs prévues (valeurs résiduelles) et la valeur Y réelle est égale aux valeurs résiduelles obtenues à partir de la période précédente. De ce fait, les mesures de l'exactitude fournissent une indication de l'exactitude à attendre lorsque vous effectuez une prévision pour une période à partir de la fin des données. Ainsi, elles n'indiquent pas l'exactitude des prévisions au-delà d'une période. Si vous comptez utiliser le modèle pour effectuer des prévisions, vous ne devez pas vous fier uniquement aux mesures d'exactitude pour prendre une décision. Vous devez également examiner l'ajustement du modèle pour vous assurer qu'il suit étroitement les données, notamment à la fin de la série, et qu'il en est de même pour les prévisions.
MSD
Le MSD (écart moyen quadratique), mesure l'exactitude des valeurs ajustées des séries chronologiques. Les valeurs aberrantes ont un effet plus important sur le MSD que sur le MAD.
Interprétation
Utilisez cet outil pour comparer les valeurs ajustées de différents modèles de série chronologique. Plus les valeurs sont faibles, meilleur est l'ajustement.
Les mesures d'exactitude reposent sur les valeurs résiduelles obtenues à partir de la période précédente. A chaque point dans le temps, le modèle est utilisé pour prévoir la valeur Y pour la prochaine période. La différence entre les valeurs prévues (valeurs résiduelles) et la valeur Y réelle est égale aux valeurs résiduelles obtenues à partir de la période précédente. De ce fait, les mesures de l'exactitude fournissent une indication de l'exactitude à attendre lorsque vous effectuez une prévision pour une période à partir de la fin des données. Ainsi, elles n'indiquent pas l'exactitude des prévisions au-delà d'une période. Si vous comptez utiliser le modèle pour effectuer des prévisions, vous ne devez pas vous fier uniquement aux mesures d'exactitude pour prendre une décision. Vous devez également examiner l'ajustement du modèle pour vous assurer qu'il suit étroitement les données, notamment à la fin de la série, et qu'il en est de même pour les prévisions.
Tendance
Les valeurs de tendance sont les composantes de tendance calculées à l'aide de l'équation de tendance ajustée.
Interprétation
La composante de tendance pour une période donnée est calculée en indiquant les valeurs de temps correspondant à chaque observation de l'ensemble de données dans l'équation de tendance ajustée. Par exemple, si l'équation de tendance ajustée est Yt = 5 + 10*t, la valeur de tendance à l'instant 2 est 25 (25 = 5 + 10(2)).
Retrait de la tendance
Les valeurs sans tendance sont les données dont la composante de tendance a été supprimée. Les valeurs sans tendance représentent la différence entre les valeurs observées et les valeurs de tendance (modèle additif) ou le quotient des valeurs observées sur les valeurs de tendance (modèle multiplicatif).
Désaisonnalisation
Les valeurs désaisonnalisées sont les données dont la composante de saisonnalité a été supprimée. Les valeurs désaisonnalisées représentent la différence entre les valeurs observées et les valeurs de saisonnières (modèle additif) ou le quotient des valeurs observées sur les valeurs saisonnières (modèle multiplicatif).
Prévoir
Les valeurs prévues sont aussi appelées valeurs ajustées. Les valeurs prévues sont des estimations ponctuelles de la variable à l'instant (t).
Les observations dont les valeurs prévues sont très différentes de la valeur observée peuvent être des valeurs aberrantes ou influentes. Essayez de déterminer la cause de toutes les valeurs aberrantes. Corrigez les erreurs de mesure ou d’entrée des données. Envisagez de supprimer les valeurs de données associées à des événements anormaux et uniques (causes spéciales). Ensuite, répétez l'analyse.
Error
Les valeurs d'erreur sont aussi appelées valeurs résiduelles. Les valeurs résiduelles correspondent aux différences entre les valeurs observées et les valeurs prévues.
Interprétation
Tracez un graphique des valeurs d'erreur pour déterminer si votre modèle est adapté. Ces valeurs peuvent fournir des informations utiles sur l'ajustement du modèle aux données. En règle générale, les valeurs d'erreur doivent être distribuées de manière aléatoire autour de 0 sans aucun schéma clair ni aucune valeur aberrante.
Période
Minitab affiche la période lorsque vous générez des prévisions. La période est l'unité de temps de la prévision. Par défaut, les prévisions commencent à la fin des données.
Prévision
Les prévisions sont les valeurs ajustées obtenues à partir du modèle de série chronologique. Minitab affiche le nombre de prévisions que vous indiquez. Les prévisions commencent soit à la fin des données, soit au point d'origine que vous avez indiqué.
Interprétation
Utilisez les prévisions pour prévoir la valeur d'une variable pour une période donnée. Par exemple, la responsable d'un entrepôt peut modéliser la quantité de produit qu'elle a besoin de commander pour les 3 mois à venir, en fonction des 60 derniers mois de commande.
La décomposition utilise des indices saisonniers et une ligne de tendance fixes. De ce fait, vous devez uniquement utiliser la décomposition pour effectuer des prévisions quand la tendance et la saisonnalité sont cohérentes. Il est notamment très important de vérifier que les valeurs ajustées correspondent aux valeurs réelles à la fin de la série chronologique. Si le schéma saisonnier ou la tendance ne correspond pas aux valeurs ajustées à la fin des données, utilisez Méthode de Winters.
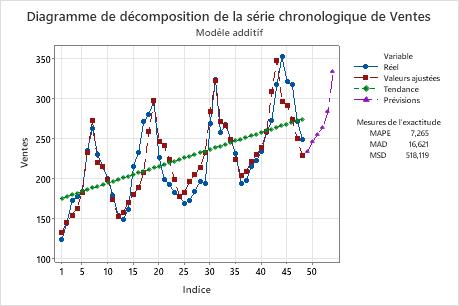
Sur ce diagramme, le modèle sous-estime les données à la fin de la série. Cela indique que la tendance ou le schéma saisonnier n'est pas constant. Si vous souhaitez créer des prévisions pour ces données, vous devez utiliser la méthode de Winters pour déterminer si elle fournit un meilleur ajustement aux données.
Diagramme de décomposition de série chronologique
Ce diagramme affiche les observations en fonction du temps. Il inclut la ligne de tendance, les valeurs ajustées calculées à partir des composantes de tendance et de saisonnalité, les prévisions et les mesures d'exactitude.
Interprétation
- Si le modèle est ajusté aux données, vous pouvez utiliser la fonction Méthode de Winters et comparer les deux modèles.
- La décomposition utilise une tendance linéaire constante. Si la tendance présente une courbure, la décomposition ne fournira pas un ajustement correct. Utilisez la fonction Méthode de Winters.
- Si le modèle n'est pas ajusté aux données, recherchez une absence de saisonnalité. S'il n'existe pas de schéma saisonnier, vous devez utiliser une autre analyse de série chronologique. Pour plus d'informations, reportez-vous à la rubrique Quelle analyse de série chronologique dois-je utiliser ?.
Sur ce diagramme, les valeurs ajustées suivent étroitement les données, ce qui indique que le modèle est ajusté aux données.
Analyse de composante
- Données initiales
- Diagramme de série chronologique des données initiales
- Données sans tendance
- Les valeurs sans tendance sont les données dont la composante de tendance a été supprimée. Les valeurs sans tendance représentent la différence entre les valeurs observées et les valeurs de tendance (modèle additif) ou le quotient des valeurs observées sur les valeurs de tendance (modèle multiplicatif). Si le diagramme des données sans tendance est différent des données initiales, vous pouvez en conclure qu'il existe une composante de tendance dans les données.
- Données saisonnières ajustées
- Les valeurs désaisonnalisées sont les données dont la composante de saisonnalité a été supprimée. Les valeurs désaisonnalisées représentent la différence entre les valeurs observées et les valeurs de saisonnières (modèle additif) ou le quotient des valeurs observées sur les valeurs saisonnières (modèle multiplicatif). Si le diagramme des données ajustées de manière saisonnière est différent des données initiales, vous pouvez en conclure qu'il existe une composante de saisonnalité dans les données.
- Données sais. ajust. et ss tend.
- Les valeurs désaisonnalisées et sans tendance sont également appelées valeurs résiduelles. Les valeurs résiduelles sont les différences entre les valeurs observées et les valeurs prévues. Examinez le diagramme pour déterminer si votre modèle est adapté. Les valeurs résiduelles doivent être distribuées de manière aléatoire sans aucun schéma clair ni aucune valeur aberrante.
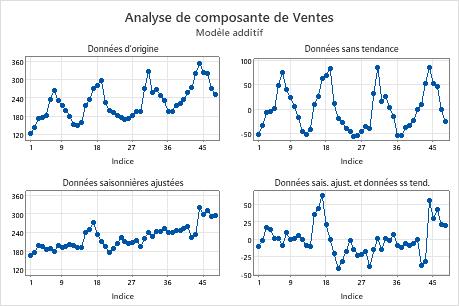
Dans ce diagramme, les données sans tendance et les données désaisonnalisées ont un aspect différent des observations initiales. Vous pouvez en conclure qu'il existe une composante de tendance et une composante de saisonnalité dans les données. Les importantes valeurs résiduelles positives à la fin des données indiquent que le modèle sous-estime ces périodes.
Analyse saisonnière
- Indices saisonniers
- Les indices saisonniers représentent les effets saisonniers à l'instant t. Utilisez le diagramme pour déterminer la direction de l'effet saisonnier.
- Données sans tendance par saison
- Les données sans tendance correspondent aux données dont la composante de tendance a été supprimée. Utilisez les boîtes à moustaches pour déterminer les périodes saisonnières qui présentent respectivement le plus et le moins de variation.
- Variation en pourcentage par saison
- Le diagramme indique le pourcentage de variation pour chaque saison. Utilisez le diagramme pour quantifier la variation de chaque période saisonnière.
- Valeurs résiduelles par saison
- Les valeurs résiduelles sont les différences entre les valeurs observées et les valeurs prévues. Utilisez le diagramme pour déterminer s'il existe un effet saisonnier sur les valeurs résiduelles.
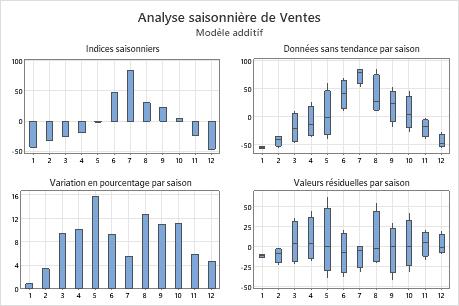
Sur ce diagramme, les indices saisonniers indiquent des mouvements descendants moyens au cours des 5 premiers mois et les 2 derniers mois de la saison, ainsi que des mouvements principalement ascendants du 6e au 10e mois. Le diagramme de la variation des pourcentages par saison montre que les 1er et 5e mois présentent respectivement le moins et le plus de variation. Les boîtes à moustaches des données sans tendance par saison montrent que les mois où la valeur absolue de l'effet saisonnier est élevée tendent à présenter moins de variation que les mois où l'effet saisonnier est moindre. Le diagramme des valeurs résiduelles par saison n'indique pas d'effet saisonnier clair sur les valeurs résiduelles.
Histogramme des valeurs résiduelles
L'histogramme des valeurs résiduelles présente la loi de distribution des valeurs résiduelles pour toutes les observations. Si le modèle est correctement ajusté aux données, les valeurs résiduelles doivent être réparties de manière aléatoire avec une moyenne de 0. Par conséquent, l'histogramme doit être a peu près symétrique autour de 0.
Droite de Henry des valeurs résiduelles
La droite de Henry des valeurs résiduelles affiche les valeurs résiduelles en fonction de leurs valeurs attendues lorsque la loi de distribution est normale.
Interprétation
Utilisez la droite de Henry des valeurs résiduelles pour déterminer si les valeurs résiduelles sont normalement distribuées. Notez cependant que cette analyse ne requiert pas que les valeurs résiduelles soient distribuées normalement.
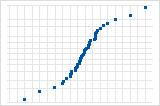
Une courbe S implique une distribution aux extrémités allongées.
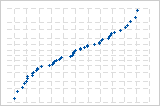
Une courbe S inversée implique une distribution aux extrémités écourtées.

Une courbe descendante implique une loi asymétrique à droite.

Quelques points situés loin de la ligne impliquent une distribution comportant des valeurs aberrantes.
Valeurs résiduelles en fonction des valeurs ajustées
Le diagramme des valeurs résiduelles en fonction des valeurs ajustées affiche les valeurs résiduelles sur l'axe des Y et les valeurs ajustées sur l'axe des X.
Interprétation
Utilisez le diagramme des valeurs résiduelles en fonction des valeurs ajustées pour déterminer si les valeurs résiduelles ne sont pas biaisées et ont une variance constante. Idéalement, les points doivent être répartis de façon aléatoire de chaque côté de 0, sans schéma visible.
| Schéma | Ce que le schéma indique |
|---|---|
| Eparpillement ou répartition déséquilibrée des valeurs résiduelles en fonction des valeurs ajustées | Variance non constante |
| Curviligne | Un terme d'ordre supérieur manquant |
| Un point très éloigné de zéro | Une valeur aberrante |
Si vous constatez une variance non constante ou des schémas dans les valeurs résiduelles, vos prévisions risquent de ne pas être exactes.
Valeurs résiduelles en fonction de l'ordre
Le diagramme des valeurs résiduelles en fonction de l'ordre affiche les valeurs résiduelles dans l'ordre dans lequel elles ont été collectées.
Interprétation
Utilisez le diagramme des valeurs résiduelles en fonction de l'ordre pour déterminer l'exactitude des valeurs ajustées par rapport aux valeurs observées au cours de la période d'observation. Si les points suivent un schéma particulier, il se peut que le modèle ne soit pas ajusté aux données. Idéalement, les valeurs résiduelles sur le diagramme doivent être réparties de façon aléatoire autour de la ligne ajustée.
| Schéma | Ce que le schéma indique |
|---|---|
| Une tendance contante à long terme | Le modèle n'est pas ajusté aux données |
| Une tendance à court terme | Un décalage ou une modification dans le schéma |
| Un point très éloigné des autres | Une valeur aberrante |
| Un brusque décalage entre les points | Le schéma sous-jacent des données a changé |
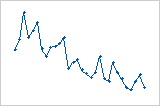
Les valeurs résiduelles diminuent systématiquement alors que l'ordre des observations augmente de gauche à droite.
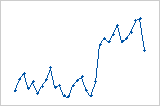
Il existe une variation soudaine des valeurs résiduelles entre les valeurs faibles (à gauche) et élevées (à droite).
Valeurs résiduelles en fonction des variables
Le diagramme des valeurs résiduelles en fonction des variables affiche les valeurs résiduelles en fonction d'une autre variable.
Interprétation
Utilisez le diagramme pour déterminer si la variable a systématiquement un effet sur la réponse. Si les valeurs résiduelles présentent des schémas, les autres variables sont associées à la réponse. Vous pouvez utiliser cette information comme fondement pour des études supplémentaires.