Sur ce thème
Etape 1 : Déterminer l'ajustement du modèle à vos données
- Valeur de p ≤ α : Le modèle s'ajuste relativement bien aux données.
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez en conclure qu'il existe une différence statistiquement significative entre les modèles. Vous devez examiner si l’un des termes est statistiquement significatif et vous assurer que le modèle satisfait à l’hypothèse des dangers proportionnels.
- Valeur de p > α : Il n'existe pas assez de preuves pour conclure que l'effet présente une différence significative.
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas en conclure que la différence de conditions modifie la réponse. Il est sans doute nécessaire de réajuster le modèle sans le terme.
Tests d'adéquation de l'ajustement
| Test | DL | Khi deux | Valeur de p |
|---|---|---|---|
| Rapport de vraisemblance | 4 | 18,31 | 0,001 |
| Wald | 4 | 21,15 | 0,000 |
| Score | 4 | 24,78 | 0,000 |
Principaux résultats : Valeur de P
Dans ces résultats, les valeurs de p pour les 3 tests sont inférieures à 0,05, vous pouvez donc conclure que le modèle correspond bien aux données.
Étape 2 : Déterminer si l'association entre la réponse et le terme est statistiquement significative
- Valeur de p ≤ α : l'association est statistiquement significative
- Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez conclure qu'il existe une association statistiquement significative entre la variable de réponse et le terme.
- Valeur de p > α : l'association n'est pas statistiquement significative
- Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas conclure qu'il existe une association statistiquement significative entre la variable de réponse et le terme. Il est sans doute nécessaire de réajuster le modèle sans le terme.
- Si un facteur aléatoire est significatif, vous pouvez en conclure qu'il contribue à la variation dans la réponse.
- Si une covariable est statistiquement significative, vous pouvez en conclure qu'une variation de la valeur de la covariable entraîne une variation de la valeur de réponse moyenne.
- Si un terme d'interaction est significatif, la relation entre l'un des facteurs et la réponse dépend des autres facteurs du terme. Dans ce cas, vous ne devez pas interpréter les effets principaux sans prendre en compte l'effet d'interaction.
- Si un terme polynomial est significatif, vous pouvez en conclure que les données contiennent une courbure.
Analyse de la variance
| Test de Wald | |||
|---|---|---|---|
| Source | DL | Khi deux | Valeur de p |
| Âge | 1 | 1,78 | 0,182 |
| Scène | 3 | 17,92 | 0,000 |
Principaux résultats : Valeur de P
Dans ces résultats, la valeur p pour le stade est significative à un niveau de 0,05. Par conséquent, vous pouvez conclure que le stade du cancer a un effet statistiquement significatif sur la survie du patient. Cependant, la valeur de p pour l’âge est de 0,182, de sorte que l’effet de l’âge n’est pas significatif à un niveau de α de 0,05.
Étape 3 : Déterminer les risques relatifs des prédicteurs
- Variable de catégorie
-
Dans le tableau Risques relatifs pour les prédicteurs catégoriels, Minitab étiquette deux niveaux de la variable catégorielle comme étant le niveau A et le niveau B. Le risque relatif décrit le taux d’occurrence de l’événement pour le niveau A par rapport au niveau B. Par exemple, dans les résultats suivants, le risque de subir l’événement pour les patients au stade IV est 5,5 fois plus élevé que le risque pour les patients au stade I.
- Variable continue
- Dans le tableau Risques relatifs pour les prédicteurs continus, Minitab affiche l’unité de changement et le risque relatif. Le risque relatif décrit la variation du taux de danger pour chaque unité de variation de la valeur du prédicteur. Par exemple, dans les résultats suivants, un patient est 1,02 fois plus susceptible de subir l’événement pour chaque augmentation de 1 an jusqu’à son âge.
Vous pouvez utiliser l’intervalle de confiance pour déterminer si le risque relatif est statistiquement significatif. Habituellement, si l’intervalle de confiance contient 1, vous ne pouvez pas conclure que le risque relatif est statistiquement significatif.
Risques relatifs pour les prédicteurs continus
| Incrément | Risque relatif | IC à 95 % | |
|---|---|---|---|
| Âge | 1 | 1,0192 | (0,9911; 1,0481) |
Risques relatifs pour les prédicteurs de catégorie
| Niveau A | Niveau B | Risque relatif | IC à 95 % |
|---|---|---|---|
| Scène | |||
| II | I | 1,1503 | (0,4647; 2,8477) |
| III | I | 1,9010 | (0,9459; 3,8204) |
| IV | I | 5,5068 | (2,4086; 12,5901) |
| III | II | 1,6526 | (0,6819; 4,0049) |
| IV | II | 4,7872 | (1,7825; 12,8566) |
| IV | III | 2,8968 | (1,2952; 6,4788) |
Principaux résultats : Risque relatif, IC à 95 %
Etape 4 : Déterminer si le modèle satisfait à l’hypothèse des dangers proportionnels
- Tableau des essais pour les dangers proportionnels
-
Utilisez les tests pour déterminer si le modèle répond à l’hypothèse des dangers proportionnels. L’hypothèse nulle est que le modèle répond à l’hypothèse pour tous les prédicteurs. En général, un seuil de signification (noté alpha ou α) de 0,05 fonctionne bien. Un seuil de signification de 0,05 indique 5 % de risques de conclure à tort que le modèle explique la variation dans la réponse.
Si la valeur de p est inférieure ou égale au seuil de signification, vous pouvez en conclure que le modèle ne rend pas correctement compte de la relation. Si la valeur de p est supérieure au seuil de signification, vous ne pouvez pas conclure que le modèle explique la variation dans la réponse.
- Parcelle d’Arjas
-
Utilisez le diagramme d’Arjas pour déterminer si le modèle répond à l’hypothèse des dangers proportionnels pour un prédicteur catégorique. Si les courbes du diagramme diffèrent de la ligne de 45 degrés, le modèle ne répond pas à l’hypothèse des dangers proportionnels pour le prédicteur.
Si le modèle ne répond pas à l’hypothèse d’une variable, essayez plutôt d’utiliser la variable comme variable de stratification.
- Intrigue d’Andersen
-
Utilisez le diagramme d’Andersen pour déterminer si le modèle répond à l’hypothèse des risques proportionnels pour différentes strates. Chaque combinaison de valeurs d’une ou plusieurs variables de stratification définit une strate. Le graphique contient une courbe pour chaque strate. Si le modèle répond à l’hypothèse, les courbes sont des lignes droites passant par le point où X = 0 et Y = 0. Si le taux de danger de référence pour une strate est le même que le taux de danger de référence pour la strate sur l’axe des x, la courbe suit la ligne de référence de 45 degrés sur le graphique.
Si le modèle ne répond pas à l’hypothèse, demandez-vous s’il faut diviser les données par la variable de stratification pour laquelle le modèle ne répond pas à l’hypothèse des risques proportionnels. Effectuez ensuite une analyse distincte sur chaque sous-ensemble de données. Les analyses distinctes fournissent des effets différents pour les prédicteurs de chaque sous-ensemble.
Tests de risques proportionnels
| Terme | DL | Corrélation | Khi deux | Valeur de p |
|---|---|---|---|---|
| Âge | 1 | 0,1328 | 1,18 | 0,278 |
| Scène | ||||
| II | 1 | -0,0104 | 0,01 | 0,940 |
| III | 1 | -0,2445 | 2,86 | 0,091 |
| IV | 1 | -0,1193 | 0,63 | 0,426 |
| Global | 4 | — | 4,61 | 0,330 |
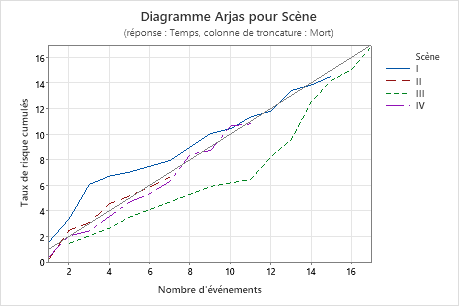
Principaux résultats : Valeur P, tracé d’Arjas
Dans ces résultats, les valeurs de p pour l’essai pour les dangers proportionnels sont toutes supérieures à 0,05, de sorte que vous ne pouvez pas conclure que le modèle ne répond pas à l’hypothèse des dangers proportionnels.
Le diagramme d’Arjas affiche les taux de danger cumulatifs par rapport au nombre d’événements pour chaque niveau de Scène. Dans ce diagramme d’Arjas, les lignes suivent généralement la ligne de 45 degrés, de sorte que vous pouvez conclure que le modèle répond à l’hypothèse des dangers proportionnels pour le prédicteur Scène.