Sur ce thème
L’analyse de la variance fournit un test de la signification statistique pour chaque prédicteur du modèle.
DL
L'interprétation du rapport des probabilités de succès varie selon que le prédicteur est de catégorie ou continu. Pour un prédicteur catégorique, les degrés de liberté sont inférieurs de 1 au nombre de niveaux, k, dans le prédicteur (k – 1). Pour un prédicteur continu, les degrés de liberté sont toujours 1. Pour un terme d’ordre supérieur, les degrés de liberté sont le produit des degrés de liberté dans les termes composites. Par exemple, le degré de liberté pour l’interaction entre deux prédicteurs catégoriques à 3 niveaux est de 2 × 2 = 4.
Khi deux
- Test de Wald
- Test de rapport de vraisemblance
- Tests de score
Si des clusters sont présents dans la conception, Minitab fournit le tableau ANOVA basé sur le test de Wald, car les méthodes de rapport de vraisemblance et de score supposent que les observations au sein des clusters sont indépendantes.
Lorsque la variable de réponse n’a pas de temps de réponse liés, le test de score est identique au test de classement log-rank bien connu.
Définitions :
Les calculs pour les 3 types de tests utilisent les définitions suivantes.
Soit 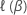 soit la fonction de ressemblance partielle de Breslow ou la fonction de
vraisemblance partielle d’Efron évaluée à
β.
soit la fonction de ressemblance partielle de Breslow ou la fonction de
vraisemblance partielle d’Efron évaluée à
β.
Soit 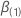 être un vecteur
q-composant et
être un vecteur
q-composant et 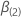 être un vecteur(p –
q)de composante de sorte que les 2 vecteurs de coefficient de
composante p ont les définitions suivantes :
être un vecteur(p –
q)de composante de sorte que les 2 vecteurs de coefficient de
composante p ont les définitions suivantes :  et
et 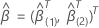 .
.
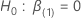

Soit 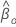 être la probabilité maximale (partielle) de
être la probabilité maximale (partielle) de  dans le
cadre du modèle restreint, lorsque
dans le
cadre du modèle restreint, lorsque 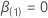 . Alors
l’estimation de la probabilité maximale sous l’hypothèse nulle a la forme
suivante :
. Alors
l’estimation de la probabilité maximale sous l’hypothèse nulle a la forme
suivante :
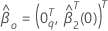
où 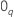 est un vecteur
q-composantede zéros et
est un vecteur
q-composantede zéros et  est la probabilité maximale (partielle) de
est la probabilité maximale (partielle) de 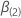 Lorsque
la valeur
Lorsque
la valeur 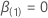 .
.
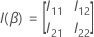
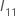 est la matrice
q ×
q suivante :
est la matrice
q ×
q suivante : 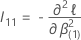
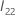 est la matrice
p –
q ×
p –
q suivante :
est la matrice
p –
q ×
p –
q suivante : 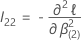
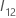 et
et  se définit par :
se définit par : 
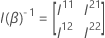
Dans l’hypothèse nulle, la statistique de test pour chacun des trois tests (Wald, rapport de vraisemblance et tests de score) a une distribution asymptotique du chi carré avec q degrés de liberté. La distribution asymptotique est valide lorsque le nombre d’événements observés est important par rapport au nombre de paramètres dans le modèle. Pour les prédicteurs catégoriels, le nombre d’événements dans chaque niveau doit également être suffisamment important.
Test de Wald
Pour le test de Wald, la statistique du test se présente sous la forme suivante :
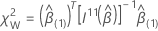
où 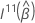 est la sous-matrice
q supérieure ×
q de
est la sous-matrice
q supérieure ×
q de  .
.
Si la conception comporte des grappes, les calculs utilisent la variance
robuste de Lin & Wei (1989)1.
Soit  être la matrice des
scores résiduels. La matrice de variance/covariance a la forme suivante :
être la matrice des
scores résiduels. La matrice de variance/covariance a la forme suivante :

où 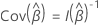 et
et  est la matrice
résiduelle du score réduit. Pour obtenir la matrice résiduelle de score réduit,
remplacez chaque groupe de lignes résiduelles de score par la somme de ces
lignes résiduelles.
est la matrice
résiduelle du score réduit. Pour obtenir la matrice résiduelle de score réduit,
remplacez chaque groupe de lignes résiduelles de score par la somme de ces
lignes résiduelles.
Test de rapport de vraisemblance
Les hypothèses du test de rapport de vraisemblance sont les suivantes :
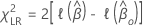
où 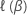 est la fonction log-vraisemblance partielle appropriée du modèle.
est la fonction log-vraisemblance partielle appropriée du modèle.
Si des clusters sont présents dans la conception, Minitab fournit le tableau ANOVA basé sur le test de Wald, car les méthodes de rapport de vraisemblance et de score supposent que les observations au sein des clusters sont indépendantes.
Tests de score
Soit 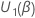 être le vecteur des
dérivées partielles de la fonction log-vraisemblance par rapport à
être le vecteur des
dérivées partielles de la fonction log-vraisemblance par rapport à
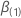 .
Plus précisément, ce vecteur
q-composanta la forme suivante :
.
Plus précisément, ce vecteur
q-composanta la forme suivante :
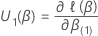
Ensuite, la statistique de test pour le test de score a la forme suivante:
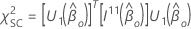
Si des clusters sont présents dans la conception, Minitab fournit le tableau ANOVA basé sur le test de Wald, car les méthodes de rapport de vraisemblance et de score supposent que les observations au sein des clusters sont indépendantes.
Valeur de p
La valeur de p ajustée comporte l'expression suivante :

où  est une variable aléatoire qui suit une distribution du chi carré avec
est une variable aléatoire qui suit une distribution du chi carré avec
 degrés de
liberté.
degrés de
liberté.  est la statistique de test.
est la statistique de test.