Sur ce thème
- Effet du format des données sur l'interprétation du R2 de la somme des carrés d'écart et du R2 ajusté de la somme des carrés d'écart
- Pourquoi le test d'adéquation de l'ajustement par la somme des carrés d'écart peut-il être trompeur avec des données au format réponse binaire/effectif ?
- Pourquoi le test d'adéquation de l'ajustement de Pearson peut-il être trompeur pour les données au format réponse binaire/effectif ?
Dans la fonction régression logistique binaire, vous pouvez entrer les données sous deux formats : au format réponse binaire/effectif ou au format événement/essai. La fiabilité et l'interprétation de certaines statistiques dans les résultats dépendent du format des données. Pour plus d'informations sur les cas dans lesquels utiliser chaque format de données, reportez-vous à la rubrique Quand utiliser chaque format de données dans la régression logistique binaire ?.
Effet du format des données sur l'interprétation du R2 de la somme des carrés d'écart et du R2 ajusté de la somme des carrés d'écart
Dans le cadre de la régression logistique binaire, le format des données influe sur la façon dont vous interprétez les valeurs du R2 de la somme des carrés d'écart et du R2 ajusté de la somme des carrés d'écart. Au format événement/essai, chaque valeur observée représente la probabilité de l'événement pour tous les essais de cette ligne de données. En général, cette probabilité concerne plusieurs essais et est comprise entre 0 et 1. En revanche, chaque observation au format réponse binaire/effectif représente en général un seul essai. La valeur observée pour un seul essai est 1 ou 0.
En général, l'utilisation d'un format de données différent entraîne une différence dans la somme des carrés d'écart totale des données. Pour les données de type événement/essai, la somme des carrés d'écart représente la différence entre les probabilités prévues et celles observées. Pour le format réponse binaire/effectif, la somme des carrés d'écart représente la différence entre les probabilités prévues et le résultat de chaque essai, de 0 % ou 100 %. Le R2 de la somme des carrés d'écart et le R2 ajusté de la somme des carrés d'écart sont en général supérieurs pour les données au format événement/essai.
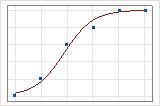
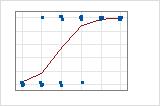
Un graphique montre bien la différence. Dans ces diagrammes, les symboles représentent les observations issues des données et la courbe représente les valeurs prévues dans le modèle. Pour les données au format événement/essai, les symboles sont proches de la courbe. La valeur du R2 de la somme des carrés d'écart pour les données au format événement/essai est d'environ 96 %. Le modèle prévoit très bien les probabilités moyennes.
Pour les données au format réponse binaire/effectif, les observations sont proches de la courbe des valeurs prévues lorsque celle-ci est proche de 0 % ou de 100 %. La valeur du R2 de la somme des carrés d'écart pour les données au format réponse binaire/effectif est d'environ 56 %. La relation entre les probabilités prévues et les cas individuels n'est pas aussi forte.
Pourquoi le test d'adéquation de l'ajustement par la somme des carrés d'écart peut-il être trompeur avec des données au format réponse binaire/effectif ?
Dans le cadre de la régression logistique binaire, le format des données influe sur la fiabilité des tests d'adéquation de l'ajustement par la somme des carrés d'écart. Plus le nombre d'essais par ligne diminue, plus la valeur de p fournie par le test d'adéquation de l'ajustement par la somme des carrés d'écart diminue. Les données au format réponse binaire/effectif comptent en général peu d'essais par ligne. Par conséquent, si les données sont au format réponse binaire/effectif, le test d'adéquation de l'ajustement par la somme des carrés d'écart indiquera probablement un faible ajustement même si celui-ci est en fait satisfaisant. De même, le test d'adéquation de l'ajustement par la somme des carrés d'écart indiquera probablement à tort un faible ajustement si les données sont au format événement/essai mais que le nombre d'essais par ligne est faible.
Le test de Hosmer-Lemeshow ne dépend pas du format des données. Lorsque les données comptent plusieurs essais par ligne, le test de Hosmer-Lemeshow est un indicateur plus fiable de l'ajustement du modèle aux données.
Comparez ces deux ensembles de résultats, qui concernent les mêmes données, mais avec des formats différents. Pour ces données, la forme du modèle est correcte. Les informations de réponse, les coefficients et les résultats du test de Hosmer-Lemeshow sont identiques. La conclusion du test d'adéquation de l'ajustement par la somme des carrés d'écart dépend du format des données.
Dans ces résultats, les données sont au format réponse binaire/effectif, sans colonne d'effectifs. L'analyse utilise 500 lignes de données. Chaque ligne représente un essai. Au seuil de signification de 0,05, la valeur de p pour le test d'adéquation de l'ajustement par la somme des carrés d'écart indique que l'ajustement du modèle est faible. Cette valeur de p nous amènerait à conclure à tort que le format du modèle est incorrect. Si vous collectez des données au format réponse binaire/effectif, le test d'adéquation de l'ajustement par la somme des carrés d'écart n'est souvent pas fiable.
Régression logistique binaire : Y en fonction de X
Dans ces résultats, les données sont au format événement/essai. L'analyse utilise 5 lignes de données. Chaque ligne de données représente 100 essais. Au seuil de signification de 0,05, la valeur de p pour le test d'adéquation de l'ajustement par la somme des carrés d'écart n'indique en rien que le modèle est mal ajusté. Si vous collectez des données au format événement/essai, le test d'adéquation de l'ajustement par la somme des carrés d'écart est généralement fiable.
Régression logistique binaire : Evénement en fonction de X
Pourquoi le test d'adéquation de l'ajustement de Pearson peut-il être trompeur pour les données au format réponse binaire/effectif ?
Dans le cadre de la régression logistique binaire, le format des données influe sur la fiabilité des tests d'adéquation de l'ajustement de Pearson. L'approximation de la loi du Khi deux utilisée par le test de Pearson est inexacte lorsque le nombre d'événements attendu par ligne est faible. Les données au format réponse binaire/effectif comptent en général peu d'essais par ligne. Par conséquent, le test d'ajustement de Pearson a de grandes chances d'être inexact lorsque les données sont au format réponse binaire/effectif.
Le test de Hosmer-Lemeshow ne dépend pas du format des données. Lorsque les données comptent plusieurs essais par ligne, le test de Hosmer-Lemeshow est un indicateur plus fiable de l'ajustement du modèle aux données.
Comparez ces deux ensembles de résultats, qui concernent les mêmes données, mais avec des formats différents. Pour ces données, la forme du modèle est incorrecte. Le véritable modèle contient l'interaction entre X1 et X2. Les informations de réponse, les coefficients et les résultats du test de Hosmer-Lemeshow sont identiques. La conclusion du test d'adéquation de l'ajustement de Pearson dépend du format des données.
Dans ces résultats, les données sont au format réponse binaire/effectif avec une colonne d'effectifs. L'analyse utilise 18 lignes de données. Chaque ligne représente 250 essais de Bernoulli. Au seuil de signification de 0,05, la valeur de p pour le test d'adéquation de l'ajustement de Pearson indique que le modèle est ajusté aux données. Cette valeur de p nous amènerait à conclure à tort que le modèle est adapté. Si vous collectez des données au format réponse binaire/effectif, le test d'adéquation de l'ajustement de Pearson n'est pas fiable.
Régression logistique binaire : Y en fonction de X1; X2
Dans ces résultats, les données sont au format événement/essai. L'analyse utilise 9 lignes de données. Chaque ligne de données représente 500 essais. Au seuil de signification de 0,05, la valeur de p pour le test d'adéquation de l'ajustement de Pearson indique que le modèle n'est pas ajusté aux données. Si vous collectez des données au format événement/essai, le test d'adéquation de l'ajustement de Pearson est généralement fiable.