Sur ce thème
- Valeur ajustée
- ErT ajust
- Intervalle de confiance pour la valeurs ajustées (IC à 95 %)
- Val rés
- Val. résid. norm
- Valeurs résiduelles supprimées
- Hi (effet de levier)
- Distance de Cook (D)
- DFITS
- Valeurs ajustées et valeurs résiduelles conditionnelles
- DL pour la moyenne conditionnelle
- Valeurs ajustées et valeurs résiduelles marginales
- DL pour la moyenne marginale
Valeur ajustée
Les valeurs ajustées sont notées 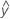 . Les valeurs ajustées sont des estimations ponctuelles de la réponse moyenne pour des valeurs données des prédicteurs. Les valeurs des prédicteurs sont également appelées valeurs de x.
. Les valeurs ajustées sont des estimations ponctuelles de la réponse moyenne pour des valeurs données des prédicteurs. Les valeurs des prédicteurs sont également appelées valeurs de x.
Interprétation
Les valeurs ajustées sont calculées en indiquant les valeurs de x correspondant à chaque observation de l'ensemble de données dans l'équation du modèle.
Par exemple, si l'équation est y = 5 + 10x, la valeur ajustée pour x = 2 est 25 (25 = 5 + 10(2)).
Les observations dont les valeurs ajustées sont très différentes de la valeur observée peuvent être des valeurs aberrantes. Les observations possédant des valeurs de prédicteurs aberrantes peuvent être influentes. Si Minitab détermine que vos données comprennent des valeurs aberrantes ou influentes, vos résultats comprennent le tableau Ajustements et diagnostics pour les observations aberrantes, qui indique quelles sont ces observations. Les observations aberrantes signalées par Minitab suivent mal l'équation de régression proposée. Toutefois, il est normal d'obtenir quelques observations aberrantes. Par exemple, selon les critères utilisés pour définir des valeurs résiduelles normalisées élevées, vous pouvez vous attendre à ce qu'environ 5 % de vos observations soient signalées pour leur valeur résiduelle normalisée importante. Pour plus d'informations sur les valeurs aberrantes, reportez-vous à la rubrique Observations aberrantes.
ErT ajust
L’erreur type de l’ajustement (ajustement SE) estime la variation de la réponse moyenne estimée pour les paramètres de variable spécifiés. Le calcul de l’intervalle de confiance pour la réponse moyenne utilise l’erreur type de l’ajustement. Les erreurs types sont toujours non négatives. L’analyse calcule les erreurs-types pour les Stat modèles du menu et les modèles de Regressão Linear et Regressão Logística Binária à partir du Module d'analyse prédictive.
Interprétation
Utilisez l'erreur type de l'ajustement pour mesurer la précision de l'estimation de la réponse moyenne. Plus l’erreur-type est petite, plus la réponse moyenne prédite est précise. Par exemple, un analyste développe un modèle pour prédire le délai de livraison. Pour un ensemble de paramètres variables, le modèle prédit un délai de livraison moyen de 3,80 jours. L’erreur type de l’ajustement pour ces paramètres est de 0,08 jour. Pour un deuxième ensemble de paramètres variables, le modèle produit le même délai de livraison moyen avec une erreur standard de l’ajustement de 0,02 jour. L’analyste peut être plus confiant dans le fait que le délai de livraison moyen pour le deuxième ensemble de paramètres variables est proche de 3,80 jours.
Avec la valeur ajustée, vous pouvez utiliser l’erreur type de l’ajustement pour créer un intervalle de confiance pour la réponse moyenne. Par exemple, en fonction du nombre de degrés de liberté, un intervalle de confiance à 95 % s’étend sur environ deux erreurs types au-dessus et en dessous de la moyenne prédite. Pour les délais de livraison, l’intervalle de confiance à 95 % pour la moyenne prédite de 3,80 jours lorsque l’erreur type est de 0,08 est (3,64, 3,96) jours. Vous pouvez être sûr à 95 % que la moyenne de la population se situe dans cette plage. Lorsque l’erreur-type est de 0,02, l’intervalle de confiance à 95 % est de (3,76, 3,84) jours. L’intervalle de confiance pour le deuxième ensemble de paramètres de variable est plus étroit car l’erreur standard est plus petite.
Intervalle de confiance pour la valeurs ajustées (IC à 95 %)
Ces intervalles de confiance (IC) sont des étendues de valeurs ayant de fortes chances de contenir la réponse moyenne pour la population qui présente les valeurs observées pour les prédicteurs ou les facteurs du modèle.
Les échantillons étant aléatoires, il est peu probable que deux échantillons d'une population donnent des intervalles de confiance identiques. Cependant, si vous prélevez de nombreux échantillons, un certain pourcentage des intervalles de confiance obtenus contiendra le paramètre de population inconnu. Le pourcentage de ces intervalles de confiance contenant le paramètre est le niveau de confiance de l'intervalle.
L'intervalle de confiance est composé de deux parties :
Interprétation
Utilisez l'intervalle de confiance afin d'évaluer l'estimation de la valeur ajustée pour les valeurs observées des variables.
Par exemple, avec un niveau de confiance de 95 %, vous pouvez être sûr à 95 % que l'intervalle de confiance comprend la moyenne de la population pour les valeurs spécifiées des variables de prévision ou facteurs dans le modèle. L'intervalle de confiance vous aide à évaluer la signification pratique de vos résultats. Utilisez vos connaissances spécialisées pour déterminer si l'intervalle de confiance comporte des valeurs ayant une signification pratique pour votre situation. Plus l'intervalle de confiance est large, moins vous avez de certitudes concernant la moyenne de valeurs futures. Si l'intervalle est trop grand pour être utile, envisagez d'augmenter votre effectif d'échantillon.
Val rés
Une valeur résiduelle (ei) est la différence entre une valeur observée (y) et la valeur ajustée correspondante (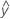 ), qui est la valeur prévue par le modèle.
), qui est la valeur prévue par le modèle.
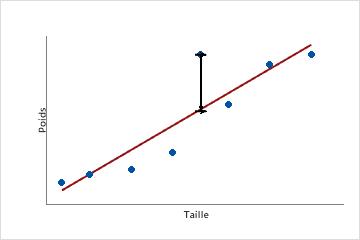
Ce nuage de points représente le poids d'un échantillon d'hommes adultes en fonction de leur taille. La droite de régression ajustée représente la relation entre la taille et le poids. Si la taille est égale à 6 pieds, la valeur ajustée pour le poids correspond à 190 livres. Si le poids réel est 200 livres, la valeur résiduelle est 10.
Interprétation
Représentez les valeurs résiduelles afin de déterminer si votre modèle est adapté et vérifie les hypothèses de régression. L'examen des valeurs résiduelles peut fournir des informations utiles sur l'ajustement du modèle aux données. En général, les valeurs résiduelles doivent être distribuées de manière aléatoire sans aucun schéma clair ni aucune valeur aberrante. Si Minitab détermine que vos données comprennent des observations aberrantes, il les indique dans les résultats, dans le tableau Ajustements et diagnostics pour les observations aberrantes. Les observations aberrantes signalées par Minitab suivent mal l'équation de régression proposée. Toutefois, il est normal d'obtenir quelques observations aberrantes. Par exemple, en vous fondant sur les critères de valeurs résiduelles élevées, vous pouvez vous attendre à ce qu'environ 5 % de vos observations soient signalées pour leur valeur résiduelle importante. Pour plus d'informations sur les valeurs aberrantes, reportez-vous à la rubrique Observations aberrantes.
Val. résid. norm
La valeur résiduelle normalisée est égale à la valeur résiduelle (ei) divisée par une estimation de son écart type.
Interprétation
Utilisez les valeurs résiduelles normalisées pour détecter les valeurs aberrantes. Les valeurs résiduelles normalisées supérieures à 2 et inférieures à −2 sont généralement considérées comme élevées. Le tableau Ajustements et diagnostics pour les observations aberrantes signale ces observations avec un "R". Les observations signalées par Minitab suivent mal l'équation de régression proposée. Toutefois, il est normal d'obtenir quelques observations aberrantes. Par exemple, selon les critères propres aux valeurs résiduelles normalisées élevées, vous pouvez vous attendre à ce qu'environ 5 % de vos observations soient signalées pour leur valeur résiduelle normalisée importante. Pour plus d'informations, reportez-vous à la rubrique Observations aberrantes.
Les valeurs résiduelles normalisées sont utiles car les valeurs résiduelles brutes peuvent ne pas indiquer de façon correcte les valeurs aberrantes. La variance de chaque valeur résiduelle brute peut varier selon la valeur de x qui lui est associée. Cette variation inégale complique l'évaluation de la grandeur des valeurs résiduelles brutes. La normalisation des valeurs résiduelles règle ce problème en convertissant les différentes variances sur une échelle commune.
Valeurs résiduelles supprimées
Le calcul de chaque valeur résiduelle studentisée supprimée revient à supprimer systématiquement chaque observation de l'ensemble de données, à estimer l'équation de régression et à évaluer la capacité du modèle à prévoir l'observation supprimée. Chaque valeur résiduelle supprimée studentisée est également normalisée en divisant la valeur résiduelle supprimée d'une observation par une estimation de son écart type. L'omission de l'observation permet de déterminer le comportement du modèle sans elle. Si une observation possède une valeur résiduelle supprimée studentisée élevée (si sa valeur absolue est supérieure à 2), il peut s'agir d'une valeur aberrante dans les données.
Interprétation
Utilisez les valeurs résiduelles supprimées studentisées pour détecter des valeurs aberrantes. Chaque observation est omise pour déterminer la capacité du modèle à prévoir la réponse lorsqu'elle n'est pas incluse dans le processus d'ajustement du modèle. Les valeurs résiduelles supprimées studentisées supérieures à 2 ou inférieures à −2 sont généralement considérées comme élevées. Les observations signalées par Minitab suivent mal l'équation de régression proposée. Toutefois, il est normal d'obtenir quelques observations aberrantes. Par exemple, en vous fondant sur les critères de valeurs résiduelles élevées, vous pouvez vous attendre à ce qu'environ 5 % de vos observations soient signalées pour leur valeur résiduelle importante. Si l'analyse révèle de nombreuses observations aberrantes, le modèle ne décrit peut-être pas de façon adéquate la relation entre les prédicteurs et la variable de réponse. Pour plus d'informations, reportez-vous à la rubrique Observations aberrantes.
Les valeurs résiduelles supprimées et normalisées peuvent être plus utiles que les valeurs résiduelles brutes pour détecter les valeurs aberrantes. Elles corrigent les éventuelles différences de variance des valeurs résiduelles brutes dues à des valeurs de prédicteurs ou facteurs différentes.
Hi (effet de levier)
La valeur Hi, aussi appelée effet de levier, mesure la distance entre la valeur de x d'une observation et la moyenne des valeurs de x de toutes les observations d'un ensemble de données.
Interprétation
Les valeurs Hi sont comprises entre 0 et 1. Dans le tableau Ajustements et diagnostics pour les observations aberrantes, Minitab affecte un X aux observations qui présentent soit un effet de levier supérieur à 3p/n, soit à la valeur 0,99, en considérant en priorité la plus petite de ces valeurs. Dans la valeur 3p/n, p représente le nombre de coefficients du modèle et n le nombre d'observations. Les observations que Minitab signale par un "X" peuvent être influentes.
Les observations influentes ont un effet disproportionné sur le modèle et peuvent générer des résultats trompeurs. Par exemple, un coefficient pourra être statistiquement significatif ou non selon qu'un point influent est inclus ou exclus. Les observations influentes peuvent être des points à effet de levier et/ou des valeurs aberrantes.
En cas d'observation influente, déterminez si elle est due à une erreur d'entrée de données ou de mesure. Si l'observation n'est due ni à une erreur d'entrée de données, ni à une erreur de mesure, déterminez dans quelle mesure l'observation est influente. Tout d'abord, ajustez le modèle avec et sans observation. Ensuite, comparez les coefficients, les valeurs de p, le R2, et d'autres informations relatives au modèle. Si le modèle change de manière significative lorsque vous supprimez l'observation influente, examinez le modèle plus en détail pour déterminer si vous avez spécifié le modèle de façon incorrecte. Vous pouvez être amené à rassembler davantage de données pour résoudre le problème.
Distance de Cook (D)
La distance de Cook (D) mesure l'effet qu'a une observation sur un ensemble de coefficients dans un modèle linéaire. La distance de Cook prend en compte la valeur à effet de levier et la valeur résiduelle normalisée de chaque observation afin de déterminer l'effet de l'observation.
Interprétation
Les observations dont la valeur D est élevée peuvent être considérées comme influentes. L'un des critères couramment utilisés pour déterminer si une valeur D est élevée est qu'elle soit supérieure à la médiane de la loi F : F(0,5, p, n-p), où p représente le nombre de termes du modèle (constante comprise) et n le nombre d'observations. Une autre façon d'examiner les valeurs D consiste à les comparer à l'aide d'un graphique, tel qu'un diagramme des valeurs individuelles. Les observations possédant des valeurs D supérieures à la moyenne peuvent être influentes.
Les observations influentes ont un effet disproportionné sur le modèle et peuvent générer des résultats trompeurs. Par exemple, un coefficient pourra être statistiquement significatif ou non selon qu'un point influent est inclus ou exclus. Les observations influentes peuvent être des points à effet de levier et/ou des valeurs aberrantes.
En cas d'observation influente, déterminez si elle est due à une erreur d'entrée de données ou de mesure. Si l'observation n'est due ni à une erreur d'entrée de données, ni à une erreur de mesure, déterminez dans quelle mesure l'observation est influente. Tout d'abord, ajustez le modèle avec et sans observation. Ensuite, comparez les coefficients, les valeurs de p, le R2, et d'autres informations relatives au modèle. Si le modèle change de manière significative lorsque vous supprimez l'observation influente, examinez le modèle plus en détail pour déterminer si vous avez spécifié le modèle de façon incorrecte. Vous pouvez être amené à rassembler davantage de données pour résoudre le problème.
DFITS
La valeur DFITS mesure l'effet de chaque observation sur les valeurs ajustées dans un modèle linéaire. La valeur DFITS exprime approximativement le changement, en nombre d'écarts types, de la valeur ajustée lorsque chaque observation est supprimée de l'ensemble de données et que le modèle est réajusté.
Interprétation
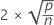
| Terme | Description |
|---|---|
| p | nombre de termes dans le modèle |
| n | nombre d'observations |
Les observations influentes ont un effet disproportionné sur le modèle et peuvent générer des résultats trompeurs. Par exemple, un coefficient pourra être statistiquement significatif ou non selon qu'un point influent est inclus ou exclus. Les observations influentes peuvent être des points à effet de levier et/ou des valeurs aberrantes.
En cas d'observation influente, déterminez si elle est due à une erreur d'entrée de données ou de mesure. Si l'observation n'est due ni à une erreur d'entrée de données, ni à une erreur de mesure, déterminez dans quelle mesure l'observation est influente. Tout d'abord, ajustez le modèle avec et sans observation. Ensuite, comparez les coefficients, les valeurs de p, le R2, et d'autres informations relatives au modèle. Si le modèle change de manière significative lorsque vous supprimez l'observation influente, examinez le modèle plus en détail pour déterminer si vous avez spécifié le modèle de façon incorrecte. Vous pouvez être amené à rassembler davantage de données pour résoudre le problème.
Valeurs ajustées et valeurs résiduelles conditionnelles
Quand le lot est un facteur aléatoire, les valeurs ajustées conditionnelles sont les valeurs ajustées d'un lot spécifique. La valeur résiduelle conditionnelle d'une observation est égale à la valeur observée de la réponse moins la valeur ajustée conditionnelle de la réponse.
Interprétation
Les valeurs ajustées conditionnelles permettent d'étudier les différences entre des lots spécifiques dans l'étude lorsque le lot est un facteur aléatoire.
DL pour la moyenne conditionnelle
Les degrés de liberté (DL) représentent la quantité d'informations disponible dans les données pour estimer l'intervalle de confiance pour la réponse moyenne.
Interprétation
Utilisez les DL pour comparer la quantité d'informations disponible sur les différentes moyennes conditionnelles. Généralement, plus le nombre de degrés de liberté est élevé, plus l'intervalle de confiance pour la moyenne est étroit. Les erreurs types étant différentes selon les observations, l'intervalle de confiance d'une moyenne ayant un nombre plus important de degrés de liberté n'est pas forcément plus étroit que celui d'une moyenne ayant moins de degrés de liberté.
Valeurs ajustées et valeurs résiduelles marginales
Lorsque le lot est un facteur aléatoire, les valeurs ajustées marginales sont les valeurs ajustées pour la population globale. La valeur résiduelle marginale d'une observation est égale à la valeur observée de la réponse moins la valeur ajustée marginale de la réponse.
Interprétation
Les valeurs ajustées marginales permettent de prévoir les valeurs de réponse pour tout lot futur lorsque le lot est un facteur aléatoire.
DL pour la moyenne marginale
Les degrés de liberté (DL) représentent la quantité d'informations disponible dans les données pour estimer l'intervalle de confiance pour la réponse moyenne.
Interprétation
Utilisez les DL pour comparer la quantité d'informations disponible sur les différentes moyennes marginales. Généralement, plus le nombre de degrés de liberté est élevé, plus l'intervalle de confiance pour la moyenne est étroit. Les erreurs types étant différentes selon les observations, l'intervalle de confiance d'une moyenne ayant un nombre plus important de degrés de liberté n'est pas forcément plus étroit que celui d'une moyenne ayant moins de degrés de liberté.