Sur ce thème
Equation de régression
Une équation de régression permet de décrire la relation entre la réponse et les termes du modèle. L'équation de régression est une représentation algébrique de la droite de régression. L'équation de régression pour le modèle linéaire prend la forme suivante : Y= b0 + b1x1. Dans l'équation de régression, Y représente la variable de réponse, b0 est la constante ou l'ordonnée à l'origine, b1 est le coefficient estimé du terme linéaire (également appelé pente de la droite) et x1 est la valeur du terme.
L'équation de régression avec plusieurs termes prend la forme suivante :
y = b0 + b1X1 + b2X2 + ... + bkXk
- y est la variable de réponse
- b0 est la constante
- b1, b2, ..., bk sont les coefficients
- X1, X2, ..., Xk sont les valeurs du terme
Si le modèle contient à la fois des variables continues et des variables de catégories, le tableau de l'équation de régression peut afficher une équation pour chaque combinaison de niveaux des variables de catégorie. Pour utiliser ces équations afin d'effectuer des prévisions, vous devez choisir celle qui est la mieux adaptée, en vous fondant sur les valeurs des variables de catégorie, puis entrer les valeurs des variables continues.
Valeurs des variables
Le modèle utilise la valeur des variables pour calculer les prévisions. Si les valeurs des variables sont aberrantes par rapport aux données utilisées par Minitab pour estimer le modèle, alors Minitab affiche un avertissement sous la prévision.
Valeur ajustée
Les valeurs ajustées sont notées 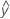 . Les valeurs ajustées sont des estimations ponctuelles de la réponse moyenne des valeurs des prédicteurs. Les valeurs des prédicteurs sont également appelées valeurs de x.
. Les valeurs ajustées sont des estimations ponctuelles de la réponse moyenne des valeurs des prédicteurs. Les valeurs des prédicteurs sont également appelées valeurs de x.
Interprétation
Les valeurs ajustées sont calculées en indiquant les valeurs de x correspondant à chaque observation de l'ensemble de données dans l'équation du modèle.
Par exemple, si l'équation est y = 5 + 10x, la valeur ajustée pour x = 2 est 25 (25 = 5 + 10(2)).
Minitab note les prévisions associées à des valeurs de prédicteur aberrantes par rapport aux autres valeurs des données. Seul un test plus poussé, avec des échantillons plus anciens, peut confirmer que la durée de stockage est exacte.
ErT ajust
L’erreur type de l’ajustement (ajustement SE) estime la variation de la réponse moyenne estimée pour les paramètres de variable spécifiés. Le calcul de l’intervalle de confiance pour la réponse moyenne utilise l’erreur type de l’ajustement. Les erreurs types sont toujours non négatives. L’analyse calcule les erreurs-types pour les Stat modèles du menu et les modèles de Regressão Linear et Regressão Logística Binária à partir du Module d'analyse prédictive.
Interprétation
Utilisez l'erreur type de l'ajustement pour mesurer la précision de l'estimation de la réponse moyenne. Plus l’erreur-type est petite, plus la réponse moyenne prédite est précise. Par exemple, un analyste développe un modèle pour prédire le délai de livraison. Pour un ensemble de paramètres variables, le modèle prédit un délai de livraison moyen de 3,80 jours. L’erreur type de l’ajustement pour ces paramètres est de 0,08 jour. Pour un deuxième ensemble de paramètres variables, le modèle produit le même délai de livraison moyen avec une erreur standard de l’ajustement de 0,02 jour. L’analyste peut être plus confiant dans le fait que le délai de livraison moyen pour le deuxième ensemble de paramètres variables est proche de 3,80 jours.
Avec la valeur ajustée, vous pouvez utiliser l’erreur type de l’ajustement pour créer un intervalle de confiance pour la réponse moyenne. Par exemple, en fonction du nombre de degrés de liberté, un intervalle de confiance à 95 % s’étend sur environ deux erreurs types au-dessus et en dessous de la moyenne prédite. Pour les délais de livraison, l’intervalle de confiance à 95 % pour la moyenne prédite de 3,80 jours lorsque l’erreur type est de 0,08 est (3,64, 3,96) jours. Vous pouvez être sûr à 95 % que la moyenne de la population se situe dans cette plage. Lorsque l’erreur-type est de 0,02, l’intervalle de confiance à 95 % est de (3,76, 3,84) jours. L’intervalle de confiance pour le deuxième ensemble de paramètres de variable est plus étroit car l’erreur standard est plus petite.
Intervalle de confiance pour la valeurs ajustées (IC à 95 %)
Ces intervalles de confiance (IC) sont des étendues de valeurs ayant de fortes chances de contenir la réponse moyenne pour la population qui présente les valeurs observées pour les prédicteurs ou les facteurs du modèle.
Les échantillons étant aléatoires, il est peu probable que deux échantillons d'une population donnent des intervalles de confiance identiques. Cependant, si vous prélevez de nombreux échantillons, un certain pourcentage des intervalles de confiance obtenus contiendra le paramètre de population inconnu. Le pourcentage de ces intervalles de confiance contenant le paramètre est le niveau de confiance de l'intervalle.
L'intervalle de confiance est composé de deux parties :
Interprétation
Utilisez l'intervalle de confiance afin d'évaluer l'estimation de la valeur ajustée pour les valeurs observées des variables.
Par exemple, avec un niveau de confiance de 95 %, vous pouvez être sûr à 95 % que l'intervalle de confiance comprend la moyenne de la population pour les valeurs spécifiées des variables de prévision ou facteurs dans le modèle. L'intervalle de confiance vous aide à évaluer la signification pratique de vos résultats. Utilisez vos connaissances spécialisées pour déterminer si l'intervalle de confiance comporte des valeurs ayant une signification pratique pour votre situation. Plus l'intervalle de confiance est large, moins vous avez de certitudes concernant la moyenne de valeurs futures. Si l'intervalle est trop grand pour être utile, envisagez d'augmenter votre effectif d'échantillon.
IP à 95 %
L'intervalle de prévision est une étendue ayant de fortes chances de contenir une réponse future pour une combinaison de paramètres de variables sélectionnée. L'intervalle de prévision est toujours plus large que l'intervalle de confiance correspondant.
Interprétation
Par exemple, un ingénieur qualité a déterminé que la durée de stockage d'un nouveau médicament est de 54,79 mois. Dans le cadre de cette analyse, la durée de stockage est définie comme le moment auquel l'ingénieur ne peut plus être sûr à 95 % que la concentration du plus mauvais lot est égale à 90 % de la concentration voulue. L'ingénieur souhaite prévoir la concentration moyenne du plus mauvais lot au bout de 54,79 mois.
Dans ces résultats, la prévision pour la réponse moyenne est d'environ 91,36 %. Cependant, l'ingénieur souhaite également estimer la gamme de valeurs d'une seule pilule du lot 2. L'intervalle de prévision indique que l'on peut être sûr à 95 % que la concentration prévue dans une seule pilule du lot 2 au bout de 54,79 mois est à peu près comprise entre 89,3217 % et 93,4001 %.
Configuration
| Variable | Configuration |
|---|---|
| Mois | 54,79 |
| Lot | 2 |
Prévision
| Valeur ajustée | ErT ajust | IC à 95 % | IP à 95 % | |
|---|---|---|---|---|
| 91,3609 | 0,801867 | (89,7233; 92,9986) | (89,3217; 93,4001) | XX |