Sur ce thème
Coefficients
[1] P. McCullagh et J. A. Nelder (1989). Generalized Linear Models, 2nd Ed., Chapman & Hall/CRC, London.
Erreur type des coefficients
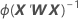
W est une matrice diagonale dans laquelle les éléments diagonaux sont fournis par la formule suivante :
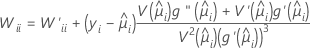
où

La matrice de variance/covariance est fondée sur la matrice hessienne observée au lieu de la matrice d'informations de Fisher. Minitab utilise la matrice hessienne observée, car le modèle obtenu est plus fiable en cas d'erreur de spécification de la moyenne conditionnelle.
Si la liaison canonique est utilisée, la matrice hessienne observée et la matrice d'informations de Fisher sont identiques.
Notation
| Terme | Description |
|---|---|
| yi | valeur de la réponse pour la ie ligne |
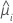 | réponse moyenne estimée pour la ie ligne |
| V(·) | fonction de variance fournie dans le tableau ci-dessous |
| g(·) | fonction de liaison |
| V '(·) | première dérivée de la fonction de variance |
| g'(·) | première dérivée de la fonction de liaison |
| g''(·) | seconde dérivée de la fonction de liaison |
La fonction de variance dépend du modèle :
| Modèle | Fonction de variance |
| Binomiale | 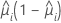 |
| Poisson | 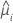 |
Pour plus d'informations, reportez-vous à [1] et à [2].
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh et J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Z
La statistique Z sert à déterminer si le prédicteur est associé à la réponse de manière significative. De grandes valeurs absolues de Z indiquent une relation significative. La formule est la suivante :
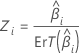
Notation
| Terme | Description |
|---|---|
| Zi | Statistique de test pour une loi normale standard |
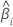 | Coefficient estimé |
 | Erreur type du coefficient estimé |
Pour les petits échantillons, le test du rapport de vraisemblance peut être un test de signification plus fiable. Les valeurs de p du rapport de vraisemblance figurent dans le tableau des sommes des carrés d'écart. Lorsque l'effectif d'échantillon est assez important, les valeurs de p des statistiques Z sont proches des valeurs de p des statistiques du rapport de vraisemblance.
valeur de p (P)
Utilisée dans les tests d'hypothèse pour vous aider à décider de rejeter ou non une hypothèse nulle. La valeur de p est la probabilité d'obtenir une statistique de test au moins aussi extrême que la valeur réelle que vous avez calculée, si l'hypothèse nulle est vérifiée. Une valeur limite couramment utilisée pour la valeur de p est 0,05. Par exemple, si la valeur de p d'une statistique de test est inférieure à 0,05, rejetez l'hypothèse nulle.
Intervalle de confiance
L'intervalle de confiance du grand échantillon pour un coefficient estimé est le suivant :
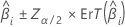
Concernant la régression logistique binaire, Minitab fournit des intervalles de confiance pour les rapports des probabilités de succès. Pour obtenir l'intervalle de confiance des rapports des probabilités de succès, utilisez un exposant pour les limites supérieure et inférieure de l'intervalle de confiance. L'intervalle indique l'étendue des probabilités de succès pour chaque variation d'unité du prédicteur.
Notation
| Terme | Description |
|---|---|
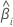 | ie coefficient |
 | probabilité cumulée inverse de la loi normale standard à 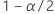 |
 | seuil de signification |
 | erreur type du coefficient estimé |
Matrice de variance/covariance
Matrice d x d, où d représente le nombre de prédicteurs plus un. La variance de chaque coefficient figure dans la cellule en diagonale et la covariance de chaque paire de coefficients figure dans la cellule hors diagonale appropriée. La variance est l'erreur type du carré du coefficient.
La matrice de variance/covariance provient de la dernière itération de la valeur inverse de la matrice d'informations. La matrice de variance/covariance a la forme suivante :
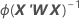
W est une matrice diagonale dans laquelle les éléments diagonaux sont fournis par la formule suivante :

où

La matrice de variance/covariance est fondée sur la matrice hessienne observée au lieu de la matrice d'informations de Fisher. Minitab utilise la matrice hessienne observée, car le modèle obtenu est plus fiable en cas d'erreur de spécification de la moyenne conditionnelle.
Si la liaison canonique est utilisée, la matrice hessienne observée et la matrice d'informations de Fisher sont identiques.
Notation
| Terme | Description |
|---|---|
| yi | valeur de la réponse pour la ie ligne |
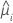 | réponse moyenne estimée pour la ie ligne |
| V(·) | fonction de variance fournie dans le tableau ci-dessous |
| g(·) | fonction de liaison |
| V '(·) | première dérivée de la fonction de variance |
| g'(·) | première dérivée de la fonction de liaison |
| g''(·) | seconde dérivée de la fonction de liaison |
La fonction de variance dépend du modèle :
| Modèle | Fonction de variance |
| Binomiale | 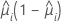 |
| Poisson | 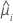 |
Pour plus d'informations, reportez-vous à [1] et à [2].
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh et J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.