Remarque
Cette commande est disponible avec le Module d'analyse prédictive. Cliquez ici pour plus d'informations sur l'activation du module.
Prédicteurs importants
- Trouvez la réduction des erreurs moyennes au carré lorsque le prédicteur divise un nœud.
- Ajoutez toutes les réductions de tous les nœuds où le prédicteur est le séparateur de nœuds.
Le score d’importance pour le prédicteur est alors égal à la somme des scores d’amélioration du modèle sur tous les arbres.

Moyenne du log négatif de vraisemblance pour une réponse binaire
Données d’apprentissage ou aucune validation
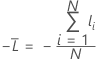
où
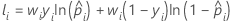
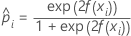
Notation pour les données d’apprentissage ou aucune validation
| Terme | Description |
|---|---|
| N | effectif de l’échantillon des données complètes ou des données d’apprentissage |
| wi | pondération pour la ie observation de l'ensemble de données complet ou de l'ensemble de données d'apprentissage |
| yi | ie valeur de réponse qui vaut 1 pour l’événement et 0 autrement dans l’ensemble de données complet ou l’ensemble de données d’apprentissage |
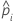 | probabilité prévue de l'événement pour la ie ligne de l'ensemble de données complet ou de l'ensemble de données d'apprentissage |
 | valeur ajustée du modèle |
Validation croisée sur K ensembles
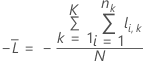
où
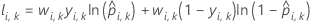

Notation pour la validation croisée sur K partitions
| Terme | Description |
|---|---|
| N | effectif de l’échantillon des données complètes ou des données d’apprentissage |
| nk | effectif de l'échantillon de la partition k |
| wi, k | pondération pour la ie observation dans la partition k |
| yi, k | valeur de réponse binaire du cas i dans la partition k. yi, k = 1 pour la classe événement, et 0 autrement. |
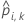 | probabilité prévue pour le cas i dans la partition k. La probabilité prévue provient du modèle qui n’utilise pas les données dans la partition k. |
 | valeur ajustée pour le cas i dans la partition k. La valeur ajustée provient du modèle qui n’utilise pas les données dans la partition k. |
Ensemble de données de test

où
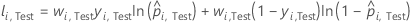
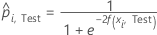
Notation pour l’ensemble de données de test
| Terme | Description |
|---|---|
| nTest | effectif de l’échantillon de l’ensemble de données de test |
| wi, Test | pondération pour la ie observation dans l'ensemble de données de test |
| yi, Test | valeur de réponse binaire du cas i dans la partition k dans l’ensemble de données de test. yi, k = 1 pour la classe événement, et 0 autrement. |
 | probabilité prévue pour le cas i dans l'ensemble de données de test |
 | valeur ajustée pour le cas i dans l'ensemble de données de test |
Moyenne du log négatif de vraisemblance pour une réponse multinomiale
 est nombre de niveaux dans la variable de réponse.
est nombre de niveaux dans la variable de réponse. Données d’apprentissage ou aucune validation
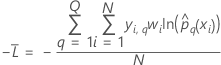
où
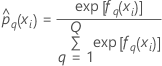
Notation pour les données d’apprentissage ou aucune validation
| Terme | Description |
|---|---|
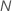 | effectif de l’échantillon des données complètes ou des données d’apprentissage |
| wi | pondération pour la ie observation de l'ensemble de données complet ou de l'ensemble de données d'apprentissage |
| yi, q | ie valeur de réponse qui vaut 1 lorsque 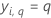 et 0 autrement et 0 autrement |
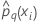 | probabilité prévue du qe niveau de la réponse pour la ie ligne dans l'ensemble de données complet ou de l'ensemble de données d'apprentissage |
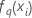 | valeur ajustée de la qe séquence d’arbres pour la ie ligne, utilisée pour calculer la probabilité prévue du qe niveau de la réponse |
Validation croisée sur K ensembles
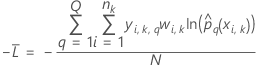
où
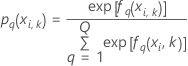
Notation pour la validation croisée sur K partitions
| Terme | Description |
|---|---|
| N | effectif de l’échantillon des données d’apprentissage |
| nk | effectif de l'échantillon de la partition k |
| wi, k | pondération pour la ie observation dans la partition k |
| yi, k, q | ie valeur de réponse du cas i dans la partition k qui vaut 1 quand  et 0 autrement. et 0 autrement. |
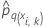 | La probabilité prévue du qe niveau de la réponse pour la ie ligne de la partition k. La probabilité prévue provient du modèle qui n’utilise pas les données dans la partition k. |
 | La valeur ajustée de la qe séquence des arbres pour la ie ligne de la partition k, utilisée pour calculer la probabilité prévue du qe niveau de la réponse. La valeur ajustée provient du modèle qui n’utilise pas les données dans la partition k. |
Ensemble de données de test

où
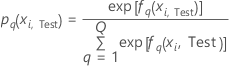
Notation pour l’ensemble de données de test
| Terme | Description |
|---|---|
| nTest | effectif de l’échantillon des données de test |
| wi, Test | pondération pour la ie observation dans les données de test |
| yi, Test, q | ie valeur de réponse du cas i dans l’ensemble de données de test qui vaut 1 lorsque 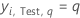 et 0 autrement. et 0 autrement. |
 | La probabilité prévue du qe niveau de la réponse pour la ie ligne dans les données de test. La probabilité prévue provient du modèle qui n’utilise pas les données de test. |
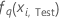 | La valeur ajustée pour la qe séquence des arbres pour la ie ligne dans les données de test, utilisée pour calculer la probabilité prévue du qe niveau de la réponse. La probabilité prévue provient du modèle qui n’utilise pas les données de test. |
Aire sous la courbe ROC
Formule


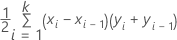
où k est le nombre de probabilités d'événements distinctes et (x0, y0) est le point (0, 0).
Pour calculer l'aire d'une courbe à partir d'un ensemble de données de test ou à partir de données à validation croisée, utilisez les points de la courbe correspondante.
Notation
| Terme | Description |
|---|---|
| TPR | taux de vrais positifs |
| FPR | taux de faux positifs |
| TP | vrais positifs, événements qui ont été correctement évalués |
| FN | faux négatifs, événements qui ont été mal évalués |
| P | nombre d’événements positifs réels |
| FP | faux positifs, non-événements qui ont été mal évalués |
| N | nombre d’événements négatifs réels |
| FNR | taux de faux négatifs |
| TNR | taux de vrais négatifs |
Exemple
| X (taux de faux positifs) | Y (taux de vrais positifs) |
|---|---|
| 0,0923 | 0,3051 |
| 0,4154 | 0,7288 |
| 0,7538 | 0,9322 |
| 1 | 1 |
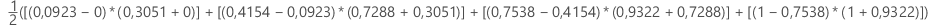

IC à 95 % pour l'aire sous la courbe ROC
L’intervalle suivant donne les limites supérieure et inférieure de l’intervalle de confiance :
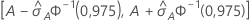
Le calcul de l'erreur type de l'aire sous la courbe ROC (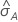 ) provient de Salford Predictive Modeler®. Pour obtenir des informations générales sur l’estimation de la variance de l'aire située sous la courbe ROC, consultez les références suivantes :
) provient de Salford Predictive Modeler®. Pour obtenir des informations générales sur l’estimation de la variance de l'aire située sous la courbe ROC, consultez les références suivantes :
Engelmann, B. (2011). Measures of a ratings discriminative power: Applications and limitations, Dans B. Engelmann et R. Rauhmeier (Eds.), The Basel II Risk Parameters:Estimation, Validation, Stress Testing - With Applications to Loan Risk Management (2e éd.) Heidelberg ; New York : Springer. doi :10.1007/978-3-642-16114-8
Cortes, C. et Mohri, M. (2005). Confidence intervals for the area under the ROC curve. Advances in neural information processing systems, 305-312.
Feng, D., Cortese, G. et Baumgartner, R. (2017). A comparison of confidence/credible interval methods for the area under the ROC curve for continuous diagnostic tests with small sample size. Statistical Methods in Medical Research, 26(6), 2603-2621. doi :10.1177/0962280215602040
Notation
| Terme | Description |
|---|---|
| A | aire située sous la courbe ROC |
 | 0,975 percentile de la loi normale standard |
Lift
Pour consulter les calculs généraux du lift cumulé, accédez à Méthodes et formules pour la courbe de lift dansAjuster le modèle et Découvrir les prédicteurs principaux avec Classification TreeNet®.
Taux de mauvais classement
Dans le cas pondéré, utilisez les dénombrements pondérés à la place des dénombrements.

Pour la validation croisée sur K partitions, le nombre de cas mal classés correspond à la somme des mauvais classements, lorsque chaque partition est l'ensemble de données de test.
Pour la validation avec un ensemble de données de test, le nombre de cas mal classés correspond à la somme des mauvais classements dans l'ensemble de données de test et le dénombrement total correspond à l'ensemble de données de test.