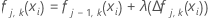Les modèles TreeNet® sont une approche de la résolution de problèmes de classification et de régression à la fois plus exacts et plus résistants au surajustement qu'un seul arbre de classification ou de régression. De manière générale, ce procédé consiste à commencer par un modèle initial composé d'un petit arbre de régression. Cet arbre donne des valeurs résiduelles pour chaque ligne des données qui deviennent la variable de réponse pour l’arbre de régression suivant. Nous construisons un autre petit arbre de régression pour prédire les valeurs résiduelles à partir du premier arbre et calculons à nouveau les valeurs résiduelles résultantes. Nous répétons cette séquence jusqu'à ce qu'un nombre optimal d'arbres présentant une erreur de prédiction minimale soit identifié à l'aide d'une méthode de validation. La séquence d'arbres qui en résulte constitue le modèle de classification TreeNet®.
Pour le cas de classification, nous pouvons ajouter des détails mathématiques afin d'effectuer une analyse avec une réponse binaire et une analyse avec une réponse multinomiale.
Réponse binaire
La création du modèle utilise les informations suivantes :
La variable de réponse, , prend les valeurs suivantes : {-1, 1}.
Les valeurs initiales ajustées pour le calcul des valeurs résiduelles généralisées ont la forme suivante :
Où est le nombre d'événements et est le nombre de non-événements.
La création du modèle utilise également les données suivantes saisies par l'analyste :
Entrée
Symbole
taux d'apprentissage
taux d'échantillonnage
nombre maximal de nœuds terminaux par arbre
nombre d'arbres
Le processus comporte les étapes générales suivantes pour le développement du je arbre, j=1,...,J :
Tirez un échantillon aléatoire de taille s * N à partir des données d'apprentissage, où N est le nombre de lignes dans ces données.
Calculez les valeurs résiduelles généralisées, gi, j, pour :
où
et est un vecteur qui représente la ie ligne des valeurs du prédicteur dans les données d'apprentissage.
Ajustez un arbre de régression avec au maximum M nœuds terminaux aux valeurs résiduelles généralisées. L'arbre divise les observations en groupes M maximaux qui s'excluent mutuellement.
Pour le me nœud terminal dans l'arbre de régression, calculez les mises à jour internes au nœud pour les valeurs ajustées de l'arbre précédent comme suit :
où
Terme
Description
nombre d'événements dans le nœud terminal m de l'arbre j
nombre de cas dans le nœud terminal m de l'arbre j
moyenne arithmétique de pour tous les cas dans le nœud terminal m de l'arbre j
Réduisez les mise à jour à l'intérieur du nœud du taux d'apprentissage et appliquez les valeurs pour les valeurs ajustées mises à jour, fj(xi) :
Répétez les étapes 1 à 5 pour les J arbres de l'analyse.
Réponse multinomiale
Pour une réponse multinomiale à K niveaux, l'analyse ajuste un arbre à chaque niveau de la variable de réponse pour chaque itération. Les valeurs initiales ajustées pour le calcul des valeurs résiduelles généralisées pour l'un des arbres ont la forme suivante :
où est le nombre de cas où la valeur de réponse est k et N est le nombre de lignes dans les données d'apprentissage.
La création du modèle utilise également les données suivantes saisies par l'analyste :
Entrée
Symbole
taux d'apprentissage
taux d'échantillonnage
nombre maximal de nœuds terminaux par arbre
nombre d'arbres
Le calcul des probabilités à partir des ajustements prend en compte la nature dépendante de ces arbres. Autrement, le processus est sensiblement le même que pour le cas binaire.
Tirez un échantillon aléatoire de taille s * N à partir des données d'apprentissage, où N est le nombre de lignes dans cet ensemble de données.
Calculez les valeurs résiduelles généralisées, gi, j, k pour , , le nombre d’arbres de l’analyse, et , le nombre de niveaux dans la variable de réponse
où
et est un vecteur qui représente la ie ligne des valeurs de prédicteur dans l’ensemble de données d'apprentissage.
Par exemple, la probabilité d'un résultat codé comme 1 à partir d'une réponse multinomiale à trois niveaux se calcule par la formule suivante :
où est l'ajustement pour la ie ligne du j–1 arbre pour le ke niveau de la variable de réponse.
Ajustez un arbre de régression avec au maximum M nœuds terminaux aux valeurs résiduelles généralisées. L'arbre divise les observations en groupes M maximaux qui s'excluent mutuellement.
Pour le me nœud terminal dans le je arbre de régression, calculez les mises à jour internes au nœud pour les valeurs ajustées de l'arbre précédent comme suit :
où
Terme
Description
nombre de cas pour le résultat k dans le nœud terminal m de l'arbre j
nombre de cas dans le nœud terminal m de l'arbre j
moyenne arithmétique de pour tous les cas dans le nœud terminal m de l’arbre j.
Réduisez les mises à jour à l'intérieur du nœud du taux d'apprentissage et appliquez les valeurs pour obtenir les valeurs ajustées mises à jour, fj, k, m(xi) :
Répétez les étapes 1 à 5 pour chacun des J arbres de l'analyse et pour chacun des K niveaux de la variable de réponse.
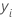 , prend les valeurs suivantes : {-1, 1}.
, prend les valeurs suivantes : {-1, 1}.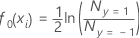
 est le nombre d'événements et
est le nombre d'événements et  est le nombre de non-événements.
est le nombre de non-événements.
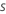
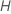
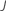
 :
:
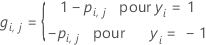

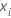 est un vecteur qui représente la ie ligne des valeurs du prédicteur dans les données d'apprentissage.
est un vecteur qui représente la ie ligne des valeurs du prédicteur dans les données d'apprentissage.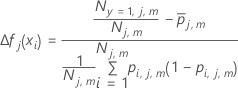 où
où

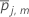
 pour tous les cas dans le nœud terminal m de l'arbre j
pour tous les cas dans le nœud terminal m de l'arbre j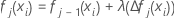
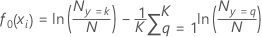
 est le nombre de cas où la valeur de réponse est k et N est le nombre de lignes dans les données d'apprentissage.
est le nombre de cas où la valeur de réponse est k et N est le nombre de lignes dans les données d'apprentissage.
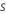
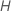
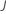
 ,
,  , le nombre d’arbres de l’analyse, et
, le nombre d’arbres de l’analyse, et 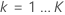 , le nombre de niveaux dans la variable de réponse
, le nombre de niveaux dans la variable de réponse
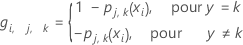
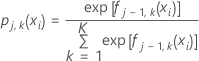
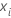 est un vecteur qui représente la ie ligne des valeurs de prédicteur dans l’ensemble de données d'apprentissage.Par exemple, la probabilité d'un résultat codé comme 1 à partir d'une réponse multinomiale à trois niveaux se calcule par la formule suivante :où
est un vecteur qui représente la ie ligne des valeurs de prédicteur dans l’ensemble de données d'apprentissage.Par exemple, la probabilité d'un résultat codé comme 1 à partir d'une réponse multinomiale à trois niveaux se calcule par la formule suivante :où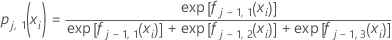
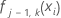 est l'ajustement pour la ie ligne du j–1 arbre pour le ke niveau de la variable de réponse.
est l'ajustement pour la ie ligne du j–1 arbre pour le ke niveau de la variable de réponse.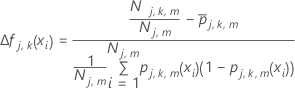
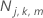

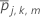
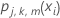 pour tous les cas dans le nœud terminal m de l’arbre j.
pour tous les cas dans le nœud terminal m de l’arbre j.