Remarque
Cette commande est disponible avec le Module d'analyse prédictive. Cliquez ici pour plus d'informations sur l'activation du module.
Variables importantes
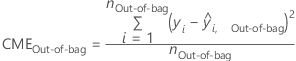
| Terme | Description |
|---|---|
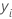 | valeur de la variable de réponse pour la ligne i |
 | nombre de lignes qui apparaissent dans les données out-of-bag sur l'ensemble de la forêt |
 | prédiction out-of-bag pour la ligne i |
Ensuite, permutez aléatoirement les valeurs d'une variable, xm à travers les données out-of-bag. Laissez identiques les valeurs de réponse et les valeurs des autres prédicteurs. Procédez ensuite de même pour calculer l'erreur quadratique moyenne des données permutées,  .
.
L'importance pour la variable xm vient de la différence des deux erreurs quadratiques moyennes :
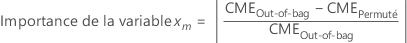
Minitab arrondit les valeurs inférieures à 10-7 à 0.

Prédictions out-of-bag et de test
Les calculs prévus pour les mesures suivantes de l'exactitude du modèle dépendent de la méthode de validation. Les prédictions out-of-bag proviennent uniquement des arbres où une ligne est out-of-bag. Pour un arbre donné, j, dans l'analyse, prédisez les données out-of-bag avec l'arbre. Répétez la prédiction pour chaque arbre de la forêt. Ensuite, calculez la moyenne des prédictions out-of-bag pour chaque ligne qui apparaît au moins une fois dans les données out-of-bag. Pour l’évaluation du modèle avec les données out-of-bag, la moyenne de la variable de réponse est la moyenne pour toutes les lignes dans les données out-of-bag.
Pour le fichier de données de test, utilisez chaque arbre de la forêt pour prédire chaque valeur du fichier de données de test. Ensuite, faites la moyenne des prédictions de tous les arbres pour obtenir la prédiction pour le modèle. Pour l’évaluation du modèle avec le fichier de test, la réponse moyenne est la moyenne des lignes du fichier de test.
R carré
Le calcul de R2 utilise les données out-of-bag ou les données de test. Les prédictions diffèrent dans ces deux cas. En général, la formule de R2 a la forme suivante :
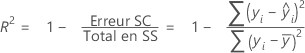
Racine de l'erreur quadratique moyenne (RMSE)

Erreur quadratique moyenne (MSE)
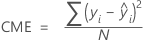
Écart absolu moyen (MAD)
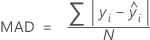
Pourcentage d'erreur absolue moyen (MAPE)

Notation
| Terme | Description |
|---|---|
| yi |  valeur de réponse observée valeur de réponse observée |
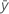 | réponse moyenne |
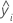 | valeur de réponse prévue pour la ligne 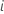 |
| N | nombre de lignes |